Das ist eine für den Ausdruck optimierte Ansicht des gesamten Kapitels inkl. Unterseiten. Druckvorgang starten.
Installation
Wie installiert man das Kieselstein ERP System?
- 1: Installation Kieselstein ERP Server
- 1.1: Kurzanleitung Installation und Update Kieselstein ERP Server
- 1.2: Installation Kieselstein ERP Server unter Debian
- 1.3: Installation Kieselstein ERP Server unter Debian
- 1.4: Installation Kieselstein ERP Server unter Ubuntu
- 1.5: Installation Kieselstein ERP Server unter Windows(r)
- 1.6: Installation Kieselstein ERP Server unter Windows
- 1.7: Installation Kieselstein ERP Server unter macOS
- 1.8: Update
- 1.8.1: Update Kieselstein ERP Server unter Debian
- 1.8.2: Update Kieselstein ERP Server unter Windows Server
- 1.9: Anforderungen Kieselstein ERP Server
- 1.10: Datensicherung
- 1.11: IT-Betreuung
- 1.12: File orientierte Dokumente Datenbank
- 2: Installation Client
- 2.1: Installation Kieselstein ERP Client unter Debian
- 2.2: Installation Kieselstein ERP Client unter Ubuntu
- 2.3: Installation Client zu Kieselstein ERP unter Windows(r)
- 2.4: Installation Client zu Kieselstein ERP unter macOS
- 3: Installation RestAPI
- 4: Installation unter Docker
- 5: Installation KES-ZE-Terminal
- 5.1: Windows Einstellungen zum KES-ZE-Terminal
- 5.2: Barcodesimulator
- 5.3: Leseeinheiten zum KES-ZE-Terminal
- 6: Installation KES-App
- 7: Nach der Installation
- 8: laufende Pflege
- 9: Installation Reportgenerator(en)
- 9.1: Installation Jasperstudio
- 9.2: Installation iReport 5.5.0
- 9.3: Formulare bearbeiten
- 9.4: Farbdefinitionen
- 9.5: Formelsammlung
- 9.6: Anwender Reports
- 9.7: Belegkopfdaten
- 9.8: Report Varianten
- 9.9: XSL-Dateien
- 9.10: Besonderheiten
- 10: Arbeiten mit Barcode
- 11: Drucker einrichten
- 12: Zeitserver einrichten
- 13: Dokumentenscann einrichten
- 14: EMail Versand einrichten
- 15: Praktische Zusatztools
- 16: Tipps und Tricks
- 17: Installation Hilfeeditor
- 18: Schnittstellen
- 18.1: CleverCure
- 18.2: Woo Commerce Import
- 18.3: Profirst Anbindung
- 19: Knowledge
- 20: Datenübernahme
1 - Installation Kieselstein ERP Server
Wie den Kieselstein ERP Applikationsserver installieren
Wie für die Installation deines Kieselstein ERP Servers vorgehen
Vorbereitung für Serverinstallation
Wird die Serverinstallation von uns durchgeführt, so benötigen wir, neben den ganzen Zugangsdaten,
- bitte die Info auf welches Laufwerk die Installation erfolgen sollte.
- In virtuellen Umgebungen, bitte genau den Server angeben auf den es installiert werden sollte.
- bitte die Größen Kalkulationen beachten siehe Anforderungen
Ein dringender Rat
Installiere dein Kieselstein ERP immer auf einem dedizierten Rechner, der nur für dein Kieselstein ERP da ist. Gerne in einer virtuellen Maschine.Leider hat die Praxis zu oft gezeigt, dass andere Programme durch komische Fehlfunktionen dein Kieselstein zerstört haben. Die Reparatur ist dann entsprechend aufwändig. In einem Falle mussten wir dann die Arbeit des Tages verwerfen und auf das Gott sei Dank vorhandene Backup zurückgreifen.
Wie komme ich zu einer aktuellen Version?
Wir freuen uns über jedeN der uns beim Testen der aktuelle Software hilft. Insofern stehen unter dem Link die latest Release und ein aktueller Build zur Verfügung.
D.h. über den Link kommst zum Repository des Kernsystem von Kieselstein ERP. 
Nun kannst du durch Klick auf Latest Release  die letzte gültige Version herunterladen.
die letzte gültige Version herunterladen.
Alternativ bekommst du den aktuellen Stand durch Klick auf  , welche den neuesten von der Technik / Softwareentwicklung zur Verfügung dargestellten Stand darstellt.
, welche den neuesten von der Technik / Softwareentwicklung zur Verfügung dargestellten Stand darstellt.
Um die Latest Release zu verwenden, klicke auf den Button und dann auf

Um die neueste Version herunterzuladen, Klicke auf Pipeline passed (du solltest nur Build mit einem Status von Passed verwenden).
Nun wird die Build Pipeline angezeigt. Klicke hier im rechten Bereich auf Artefakte herunterladen und wähle build-distpack:archive
ACHTUNG
Wenn du Zwischenversionen verwendest, solltest du diese ausschließlich für Tests auf einem Testsystem verwenden. Wir haben diese Zwischenversionen weder ausführlich getestet, noch ist sichergestellt, dass diese problemlos zur richtigen Release aktualisiert werden können.Entzippe aus dieser Datei das dist Verzeichnis nach ?:\kieselstein\dist
Lege parallel dazu ein Verzeichnis data (?:\kieselstein\data) an
Für die Installation benötigst du auch
- Postgresserver Version 14 oder 15, https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
- PGadmin in der aktuellen Version mindesten PGadmin 4, Version 7.x, https://www.pgadmin.org/download/pgadmin-4-windows/
ACHTUNG: Für die Prüfung der Datenbankversion müssen die Runtime-Programme des Postgres mit in den Pfad aufgenommen werden. Dieser ändert sich zwischen den Versionen. Du findest diese aber von der Struktur her unter ?:\Program Files\PostgreSQL\14\bin, wobei 14 die Version ist.
wir verwenden gerne auch noch:
- Firefox oder Google Chrome (https://www.mozilla.org/de/firefox/new/)
- TotalCommand von Ghilser siehe https://www.ghisler.com/ddownload.htm
- Libre Office siehe https://de.libreoffice.org/download/download/
- Acrobate Reader von Adobe siehe https://get.adobe.com/de/reader/
- Notepad++ siehe https://notepad-plus-plus.org/downloads/
- 7Zip siehe https://www.7-zip.org/download.html muss installiert werden
Installation Datenbankserver
Es werden aktuell ausschließlich PostgresQL Version 14 und 15 unterstützt. MS-SQL wird nicht unterstützt. Für eine eventuelle Konvertierung deiner MS-SQL Datenbank wende dich bitte an die Kieselstein ERP eG. Neuere PostgresQL Versionen können funktionieren, sind aber aktuell von uns nicht freigegeben.
Bei der Installation darauf achten, dass nur PostgresSQL Server und die Command Line Tools installiert werden.
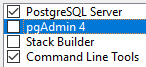
Bei der Installation muss auch das default Passwort für den User Postgres angegeben werden (postgres). Beachte in diesem Zusammenhang auch die Themen der Datenzugriffssicherheit. Aktuell kann das Datenbankpasswort durch die Environmentvariable MAIN_DB_PASS übersteuert werden.
Bitte prüfe, dass auch der Port auf 5432 vorgeschlagen wird.
Beachte dass die Installation in Windowssystemen idealerweise auf einem eigenen Laufwerk erfolgt. Also z.B. nicht auf C: sondern, vom Betriebssystem unabhängig auf z.B. D:
Installation PGadmin
Die abschließende Meldung nach dem Rechner-Neustart kann ignoriert werden.
Setzen Environmentvariable
- path Erweiterung auf Postgres “?:\Program Files\PostgreSQL\14\bin"
Hinweis: Es muss auch der Dienst auf diesen Pfad zugreifen können. - KIESELSTEIN_DIST=?:\kieselstein\dist
- KIESELSTEIN_DATA=?:\kieselstein\data
- eventuell ein abweichendes Datenbankpasswort: MAIN_DB_PASS
Es gibt noch weitere optionale Environment-Variablen welche in der README.md Datei bei den Start-Scripten (im KIESELSTEIN_DIST/bin/) beschrieben sind.
Datenbank einrichten
- ?:\Kieselstein\dist\bootstrap\database\createDb.bat ausführen, 4x postgres PW eingeben
- ?:\Kieselstein\dist\bootstrap\database\fillDb.bat ausführen, 1x postgres PW eingeben
ACHTUNG:
Wenn du bestehende Daten übernimmst, schau im Kieselstein ERP Wiki nach wie es nun weiter geht. Ansonsten:
Vorbereitete Daten
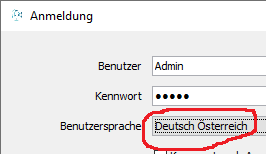
Wir haben für Testzwecke eine sehr kleine und einfache Musterdatenbank eingerichtet. Diese findest du hier. Bitte beachte:
- in deutsch Österreichisch anmelden
- es sind keine Dokumente enthalten
- es ist die integrierte Finanzbuchhaltung aktiviert und damit auch die österreichischen Steuersätze und Formulare usw.
D.h. anstatt des fillDb.bat führst du das fillDb_Demodaten.bat aus.
Eine weitere Variante sind Demodaten in deDE und ohne Fibu. Diese findest du hier. Bitte beachte:
- in deutsch Deutsch anmelden
- es sind keine Dokumente enthalten
- die integrierte Finanzbuchhaltung ist deaktiviert und es sind die deutschen Mehrwertsteuersätze eingerichtet.
D.h. anstatt des fillDb.bat führst du das fillDb_Demodaten_DE_OF.bat aus.
WICHTIG
Diese Daten müssen auf die aktuelle Datenbankversion gehoben werden.
D.h. bevor du mit der Installation fortfährst muss je nach Betriebssystem das Datenbankupdate ausgeführt werden.
Leere Datenbank ab der Version 1.x.x
Ab der Version 1.x.x steht anstatt obiger FillDb eine leere Datenbank zur Verfügung.
D.h. der Installationsprozess ändert sich insofern, das du nach dem CreateDb das Liquibase aus dem Liquibaseverzeichnis (?:\kieselstein\dist\bootstrap\liquibase) mit run-liquibase.bat update eine leere aber funktionsfähige Datenbank erzeugst. In dieser sind auch alle Änderungen passend zur installierten Version enthalten.
Für Linux Anwender, ebenfalls in das liquibase Verzeichnis wechseln (/opt/kieselstein/dist/bootstrap/liquibase) und mit ./liquibase.sh update die leere Datenbank erzeugen.
ACHTUNG: Liquibase ab Version 4.29 verlangt Java 11
Java installieren
- Azul Java 8 mit FX installieren siehe
- darauf achten, dass Java Home gesetzt wird
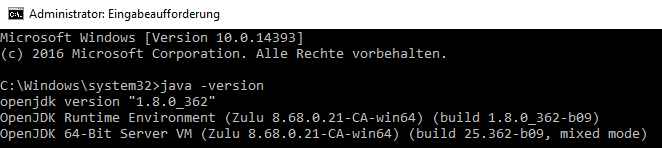
 Prüfen, dass auch installiert durch Command Shell, Java -version
Prüfen, dass auch installiert durch Command Shell, Java -version
Client vorbereiten
Aus ?:\Kieselstein\dist\clients\kieselstein-ui-swing-0.0.11.tar.gz mehrfach in die Ordner (zip) reinwechseln bis zum kieselstein-ui-swing-0.0.11. Hier die beiden Verzeichnisse bin und lib z.B. nach ?:\Kieselstein\dist\client kopieren. Nun das ?:\Kieselstein\dist\client\bin\kieselstein-ui-swing.bat editieren und den localhost auf die IP-Adresse des Servers austauschen. Wenn in anderen Sprache gestartet werden sollte, auch noch das -Dloc=de_AT auf z.B. -Dloc=de_DE oder -Dloc=de_CH oder -Dloc=en_US oder -Dloc=it_IT oder pl_PL oder sl_SL austauschen. (Weitere Sprachen, bitte melden)
Das Kieselstein-Desktop-Icon findest du hier
Weiteres zu Sprachen am Client siehe
Server Dienst einrichten
- Mit Administratorrechten eine Command Shell starten.
- Es hat sich bewährt vorher einmalig den Service manuell zu starten, also:
?:\Kieselstein\dist\bin\launch-kieselstein-main-server.bat
starten. Üblicherweise, je nach Datenbankgröße und Leistungsfähigkeit des Rechners kann es ein bisschen dauern bis der Dienst läuft. Man sieht das unter ?:\Kieselstein\dist\wildfly-12.0.0.Final\standalone\deployments<br>Hier muss für alle drei Files deployed stehen. Wenn nicht siehe - nun testweise den Client aus ?:\Kieselstein\dist\client\bin\kieselstein-ui-swing.bat starten
und mit Admin, admin anmelden.
Geht die Anmeldung, d.h. man sieht die Button Bar so läuft der Zugriff grundsätzlich. Nun den Client beenden und dann den Server (mit Strg+C) stoppen und mit der Einrichtung des Serverdienstes fortsetzen.
so läuft der Zugriff grundsätzlich. Nun den Client beenden und dann den Server (mit Strg+C) stoppen und mit der Einrichtung des Serverdienstes fortsetzen. - aus ?:\Kieselstein\dist\bootstrap\service\windows\ install-kieselstein-services.bat aufrufen
- in die Dienste / Services wechseln und die beiden Kieselsteindienste starten. Beim ersten Start hat sich die Überwachung des deployments bewährt. Sollte diese mit failed stehen bleiben, dann im log nachsehen. Hier kann man meist, auch wenn es mühsam ist, die Ursache finden.
Fehlermeldung beim Einrichten des Dienstes
Kommt beim Einrichten des Dienstes die Meldung
 so bedeutet dies “nur”, dass bisher kein Kieselstein ERP Dienst eingerichtet ist (und nicht upgedated werden konnte).
Du findest trotzdem nun die neu eingerichteten
so bedeutet dies “nur”, dass bisher kein Kieselstein ERP Dienst eingerichtet ist (und nicht upgedated werden konnte).
Du findest trotzdem nun die neu eingerichteten  in den Windows-Diensten.
in den Windows-Diensten.
Tipps und Tricks
Eine lose Sammlung von Tipps, KnowHow und ähnlichem für den/die Consultant im Rahmen der Installation.
ACHTE immer auf die Sicherheit Durch das öffnen von Ports, gibt es natürlich auch mehr Möglichkeiten das System anzugreifen. Also denke auch an die Verwendung von VPN Tunnel usw..
Dass Betriebssystem, Virenscanner und Firewall immer aktuell sind, ergibt sich schon aus der DSGVO.
Die Themen rund um die Sicherheit, Passwörter abweichend vom default usw. sind im Web ausreichend abgehandelt. Kieselstein ERP eG Mitglieder schauen im Wiki unter dem Suchwort Sicherheit nach.
Ports die für die Kommunikation benötigt werden
| Port | Zweck |
|---|---|
| 8080 | für den Zugriff auf den Kieselstein ERP Applikationsserver |
| 8280 | für den Zugriff auf die RestAPI Ab Version 1.x.x greift die RestAPI auf 8080 zu |
| 5432 | für den Zugriff auf die Postgres-Datenbank |
| 22 | für Linux, SSH Kommunikation |
Das sind die Standard Ports. Diese können, z.B. für weitere parallele Installationen am gleichen Rechner auch abweichen.
Siehe dazu: …/kieselstein/dist/bin/launch-kieselstein-main-server.bat bzw. .sh
Ergänzung an der pg_hba.conf
Hier sollte zusätzlich der gewünschte Netzwerkkreis eingetragen werden, mit dem auch ein Zugriff erlaubt ist. Beispiel:
- host all all 192.168.xx.0/24 scram-sha-256
was bedeutet, dass aus dem Subnetz xx alle IP-Geräte die ein Passwort wissen auf die Datenbank zugreifen können.
Die pg_hba.conf findest du, je nach Betriebssystem unter:
| Betriebssystem | Pfad | Bemerkung |
|---|---|---|
| Windows(R) | c:\Programm Files\PostgreSQL\VV\data\ | |
| Debian | /etc/postgresql/14/main | Achtung: Wenn englisch installiert muss der datestyle auf ‘ios, dmy’ gestellt werden. |
| Ubuntu | /etc/postgresql/14/main | ev. muss zusätzlich in der postgresql.conf listen_addresses=’*’ gestellt werden |
| iOS | .. |
Starten der Dienste unter Linux
systemctl start/stop wildfly.service systemctl start/stop tomcat.service
| Betriebssystem | Pfad |
|---|---|
| Debian | /etc/systemd/system/, |
Ändern der IP-Adresse des Kieselstein ERP Servers
ACHTUNG: Wenn auf dem Kieselstein ERP Server die IP Adresse verändert wurde, so muss danach unbedingt der Kieselstein ERP Server neu gestartet werden.
Vorbereitung für die Client-Installation
Vom Client aus auf http://Kieselstein-ERP-SERVER-IP-Adresse:8080 gehen.
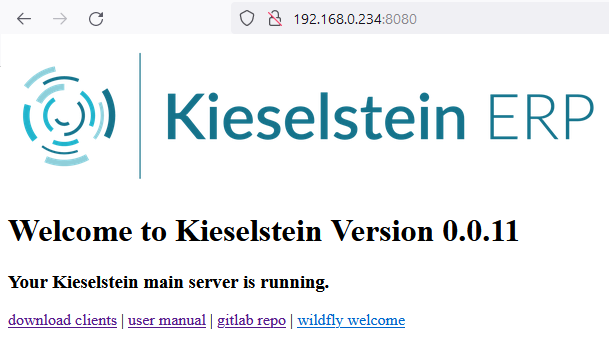
Auf der Willkommensseite findest du links unten den Link zu download clients.
hier werden alle Dateien angezeigt die im Server unter c:\Kieselstein\dist\clients zur Verfügung stehen. D.h. üblicherweise werden hier die angepassten ?:\Kieselstein\dist\client Verzeichnisse als Client.zip einkopiert und somit dem Anwender zur Verfügung gestellt.
Bewährt hat sich auch, dass hier ein aktuelles Java für den Client hinterlegt wird.
https://www.azul.com/downloads/?version=java-11-lts&os=windows&architecture=x86-64-bit&package=jdk-fx#zulu
Tools
Tools (VDA-Scann-App, Terminal, Android-Mobile-App, evtl. Java) können im {KIESELSTEIN_DATA}/tools Ordner abegelgt werden und über http://Kieselstein-ERP-SERVER-IP-Adresse:8080/tools heruntergeladen werden.
Welche Java Version für den Server?
Der Basis-Link für das erprobte Zulu Java findest du unter https://www.azul.com/downloads/?package=jdk#zulu
Hier dann für den Server nur Java 8 mit jdk-FX verwenden.
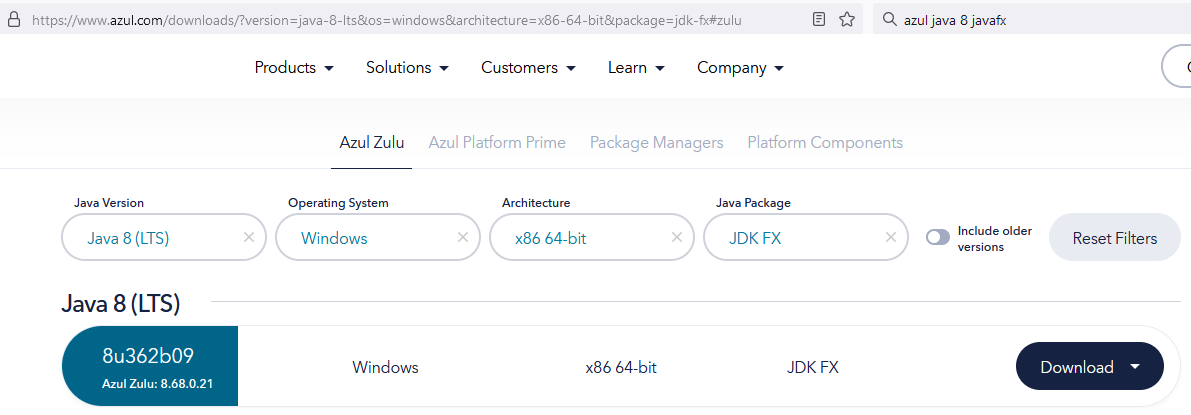
Für Windows-User empfiehlt sich die .msi herunterzuladen.
virtualisierte Betriebsumgebungen
Bitte achte massivst darauf, dass auch in virtuellen Betriebsumgebungen ausreichen Ram zur Verfügung steht. Es kommt leider immer wieder vor, dass manche IT-Betreuer glauben, der VM ausreichend Platz gegeben zu haben, es kommt dieses RAM aber bei der VM nicht an. Hier empfiehlt sich, eine fixe Speicher Zuweisung zu verwenden.
Wie gehts nun weiter?
1.1 - Kurzanleitung Installation und Update Kieselstein ERP Server
Kurzanleitung wie den Kieselstein ERP Applikationsserver installieren bzw. updaten
Wie für die Installation deines Kieselstein ERP Servers vorgehen.
Diese Beschreibung teilt sich, unabhängig von den Betriebssystemen in zwei Bereiche:
- Völlige Neuinstallation
- Update einer bestehenden Kieselstein ERP Installation.
Sie gilt ab der Kieselstein ERP Version 1.0.6, welche auch am Server Java 11 voraussetzt.
Kurzfassung der Neuinstallation
Beachte das unter Vorbereitung geschriebene
Unabhängig vom Betriebssystem ist die Vorgehensweise im wesentlichen immer die gleiche. Die wesentlichsten Unterschiede zwischen den Betriebssystemen ist das Thema:
- Rechte -> hier setzen wir entsprechend umfassendes Wissen voraus.
- wo ist das Root-Verzeichnis deiner Kieselstein ERP Installation
- Windows: Lokales Laufwerk (dargestellt mit ?:) und dann ?:\kieselstein
- Linux(e): /opt/kieselstein
In der nachfolgenden Beschreibung wird von Windows als Server Betriebssystem ausgegangen. Wir wissen, dass Linux Admins, immer auch ein umfassendes Wissen in der Windows Administration haben und dies entsprechend übersetzen können.
Benötigte Programme
- AZUL OpenJDK FX für Java 11 siehe
- PostgresQL 15, Installation ausgenommen für MAC OS immer ohne PGAdmin und Stack Builder
- PGadmin
- Latest Release deines Kieselstein ERP von Gitlab
- Datenbankversionsverwaltung, liquibase
Installation
Für Windows die Empfehlung alles auf ein eigenes Laufwerk zu installieren z.B. D:
- Installation Java, inkl. permanentem Setzen des Java_Home
- Installation PostgresQL, alles default, PW: postgres
- Installation PGadmin
- Installation Liquibase
- Unter Linux die Schriften installieren
- Installation *Kieselstein ERP
- Einrichten der Verzeichnisse data und dist unter ?:\Kieselstein
- Einkopieren des Dist Verzeichnisses aus dem kieselstein-distpack-?.?.?.tar.gz auf ?:\kieselstein\dist
- unter Windows hinzufügen des Pfades auf die PostgresQL Runtimes z.B.
- Einrichten der Environment Variablen wie unter ?:\kieselstein\dist\bin\readme.md beschrieben Unter Linux darauf achten, dies OHNE EXPORT zu machen und danach den Server neu starten
- erstellen der Datenbanken
- aus ?:\kieselstein\dist\bootstrap\liquibase createdb.bat(sh) ausführen und 4x das DB-Passwort angeben
- danach liquibase.sh update / run-liquibase.bat update ausführen
- erstellen des Clients
- ?:\kieselstein\dist\clients das kieselstein-client-?.?.?.tar entzippen und die beiden Verzeichnisse bin und lib auf c:\kieselstein\client kopieren
- im c:\kieselstein\client\bin das kieselstein-client.bat das localhost:8080 auf Kieselstein Server IP-Adresse:8080 korrigieren
- Bewährt hat sich nun das Verzeichnis c:\kieselstein\client zu zippen und auf ?:\kieselstein\dist\clients zur Verfügung zu stellen.
- erster Server Start
- den Server manuell aus einer CMD-Shell starten um eventuelle Fehlermeldungen o.ä. zu sehen
- ?:\kieselstein\dist\bin\launch-kieselstein-main-server.bat(sh) starten
Es sollte sofort / nach wenigen Sekunden unter ?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\deployments die drei Dateien mit dodeploy erscheinen. - Nach weiteren Sekunden wenigen Minuten müssen diese verschwinden und dafür *.deployed erscheinen. Ist dem nicht so, in den *.failed nachsehen oder unter ?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\log\server.log
- den Client starten und anmelden, also
c:\kieselstein\client\bin\kieselstein-client.bat starten und mit Admin, admin anmelden. Nun muss die Standard Maske deines Kieselstein ERP erscheinen.
- Als Dienst / Service einrichten
- den Cmd-Shell wieder stoppen (Strg+C)
- Windows:
- auf ?:\kieselstein\dist\bootstrap\service\windows wechseln
- install-kieselstein-services.bat ausführen
- In die Dienste wechseln und den Dienst starten und auf automatisch, verzögerter Start stellen
- Linux
- auf ?:\kieselstein\dist\bootstrap\service\linux wechseln
- install-kieselstein-services.sh ausführen
- Den Dienst mit systemctl start kieselstein-main-server starten
- nun müssen nach wenigen Sekunden / Minuten unter ?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\deployments die drei Dateien mit dodeploy erscheinen.
- in den Client wechseln / neu starten und z.B. die Benutzerverwaltung oder das System aufrufen.
- Gratulation, dein Kieselstein ERP läuft
Hinweis:
Gegebenenfalls an die Freigabe des Ports 8080 für den Zugriff innerhalb deines Netzwerkes denken.
Kurzfassung des Updates
Grundsätzlich sind die Kieselstein ERP Updates so gestaltet, dass diese, egal welche Version deine Ausgangsdatenbank hat, jederzeit aktualisiert werden können. Die Unterschiede liegen in der Ausgangsbasis für den Beginn der Liquibase Installation und gegebenenfalls in der Verlagerung der Anwenderspezifischen Reports.
Es wird immer auf die aktuelle Version upgedated. Also diejenige die du aus dem Gitlab heruntergeladen hast. Ein Downgrade ist nicht vorgesehen.
Denke daran, dass du ein vollständiges und überprüftes Backup deiner Daten und Reports gemacht hast, bevor du mit dem Update beginnst.
Bewährt hat sich hier, das nächtliche Backup zu nutzen. D.h. es wird, kurz vor dem Beginn des automatischen Backup, der bestehende Kieselstein ERP Server gestoppt. Somit können keine Veränderungen an den Daten (von den “normalen” Anwendern) durchgeführt werden und du kannst das Backup, das mit Vacuum schon auch mal einige Stunden dauern kann, als Sicherheit für dein Update nutzen.
Voraussetzungen
Diese Beschreibung geht davon aus, dass du auf 1.0.6 oder höher aktualisierst. D.h. es müssen folgende Dinge eingerichtet und funktionsfähig sein:
- Liquibase
- Java 11 passend zu deinem Betriebssystem
- aktuelle Kieselstein ERP Release
Vorgehensweise
- Stoppen des/der Dienste deines Kieselstein ERP Systems
- Windows: Dienste Stoppen
- falls von vor 1.0.3 dann aus ?:\kieselstein\dist\bootstrap\service\windows\delete-kieselstein-services.bat ausführen
WICHTIG: Dies vor den weiteren Schritten, da sonst die Pfade nicht mehr stimmen
- falls von vor 1.0.3 dann aus ?:\kieselstein\dist\bootstrap\service\windows\delete-kieselstein-services.bat ausführen
- Linux:
- systemctl stop kieselstein-main-server.service
- falls die Ausgangsinstallation vor der 1.?.? ist
- REST Service löschen da dieser ab der 1.?.? im Wildfly integriert ist.
systemctl stop kieselstein-rest-server.service
systemctl disable kieselstein-rest-server.service
rm /etc/systemd/system/kieselstein-rest-server.service
- REST Service löschen da dieser ab der 1.?.? im Wildfly integriert ist.
- Windows: Dienste Stoppen
- umbenennen des ?:\kieselstein\dist auf die Version aus ?:\kieselstein\dist\Version.txt sodass dies nun z.B. ?:\kieselstein\dist.0.2.14 lautet
- das dist aus der aktuellen Release auf ?:\kieselstein\dist entpacken
- Datenbank updaten
- wenn deine Datenbank vor der 0.0.13 ist oder die initiale 17366 ist, dann
- für Windows aus ?:\kieselstein\dist\bootstrap\liquibase
run-liquibase.bat changelog-sync –label-filter=“0.0.12” ausführen - für Linux aus /opt/kieselstein/dist/bootstrap/liquibase
./liquibase.ch changelog-sync –label-filter=“0.0.12” ausführen
- für Windows aus ?:\kieselstein\dist\bootstrap\liquibase
- für alle höheren Versionen und nach obigem
liquibase.sh update / run-liquibase.bat update ausführen
- wenn deine Datenbank vor der 0.0.13 ist oder die initiale 17366 ist, dann
- Wenn deine Ausgangsinstallation vor der 1.0.3 ist, so müssen die Anwender Reports nach data verschoben werden. D.h. ab der 1.0.3. und höher sind die Anwenderreports unter ?:\kieselstein\data\reports\ (auf das s bei reports achten)
D.h. wenn dein Briefpapier bisher unter ?:\kieselstein\dist\wildfly-12.0.0.Final\helium\server\helium\report\report\allgemein\anwender war, so muss der Inhalt des Anwenderverzeichnisses nun nach ?:\kieselstein\data\reports\allgemein - Solltest du eine Zwischenversion nach der 0.2.14 bis zu 1.0.3 besitzen, so ist die Ausgangsbasis ?:\kieselstein\dist\wildfly-26.1.2.Final\kieselstein\reports\allgemein\
- WICHTIG: Nutze die Gelegenheit wirklich nur die Anwenderreports zu übertragen von denen du dir sicher bist, dass diese tatsächlich verwendet werden.
Diese neue Struktur wurde eingeführt um das Update deines Kieselstein ERP, insbesondere unter der Berücksichtigung der Fremdsprachigen Anwenderspezifischen Reports quasi mit wenigen Klicks zu ermöglichen. - Wenn deine Ausgangsbasis vor der 1.0.3 war, dann nun die Dienste neu installieren, also
- Windows ?:\kieselstein\dist\bootstrap\service\windows\install-kieselstein-services.bat
- Linux: /opt/kieselstein/dist/bootstrap/service/linux\install-kieselstein-services.sh
- Kieselstein Dienste starten
Anmerkung: Ab der Version 1.x.x ist die Restful API im Wildfly integriert. Damit wurden ab der 1.x.x auch der Port für den Zugriff auf die Rest-Services auf 8080 geändert.
Dies muss gegebenenfalls in den peripheren Geräten wie Terminals, mobile App, eigene Apps die die Kieselstein ERP Rest nutzen geändert werden.
Alternativ steht auch ein kleiner Proxy dafür zur Verfügung. - Nun die Clients wie oben beschrieben zur Verfügung stellen, also:
- ?:\kieselstein\dist\clients das kieselstein-client-?.?.?.tar entzippen und die beiden Verzeichnisse bin und lib auf c:\kieselstein\client kopieren
- im c:\kieselstein\client\bin das kieselstein-client.bat das localhost:8080 auf Kieselstein Server IP-Adresse:8080 korrigieren
- Bewährt hat sich nun das Verzeichnis c:\kieselstein\client zu zippen und auf ?:\kieselstein\dist\clients zur Verfügung zu stellen.
- Prüfen dass dein Kieselstein Server läuft
- es müssen nach wenigen Sekunden / Minuten unter ?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\deployments die drei Dateien mit dodeploy erscheinen.
- in das Client-Bin-Verzeichnis wechseln und den Client neu starten und z.B. die Benutzerverwaltung oder das System aufrufen. Also: ?:\kieselstein\clients\bin\kieselstein-client.bat
Ausrollen der neuen Clients
du findest nun in einem Web-Browser unter http://IP_deines_Kieselstein_Servers:8080 die Startseite deines Kieselstein ERP Servers.

Hier auf download clients klicken.
In diesem Verzeichnis findest du alles, was du auf deinem Kieselstein ERP Server unter Clients (?:\kieselstein\dist\clients) zur Verfügung gestellt hast.
D.h. du kannst hier z.B. das passende APK für die mobile App zur Verfügung stellen, oder auch das Installationsprogramm für deine Terminals.
1.2 - Installation Kieselstein ERP Server unter Debian
Installation Kieselstein ERP Server unter Debian
Den Kieselstein ERP Server auf einem frischen Debian installieren.
in DEUTSCH installieren
Default MUSS das Betriebssystem in de (deutsch) installiert sein und in der richtigen Timezone. Alles andere artet in Arbeit aus.Debian 11 installieren mit root und user
Was mir alles so bei der Installation unter Debian unterkommt.
Es ist dies ein Debian 11 mit Desktop Gnome (Std)
- installiert in einer VM
- Ram: 6144 MB, Minimaler Ram 4096MB Maximaler Ram 8192MB
- Prozessoren: 4
- Festplatte 64GB
Boot-Auswahl:
- Grafical install von einer Netzwerk DVD Installation
- Sprache: German / Deutsch
- Land: Österreich / Deutschland / Schweiz / Liechtenstein
- Tastatur: Deutsch
- Rechnername: Großbuchstaben, Ziffern, Minus
- Domain-Name … leer belassen
- Eine Platte / Laufwerk eingerichtet
- Systemumgebung Debian desktop environment
- Gnome, default
- Standard-Systemwerkzeuge
Dauer ca. 30 Minuten
ssh server einrichten
OpenSSH Server installieren
apt update
apt upgrade
apt install openssh-server
Root Login per SSH ausschalten
nano /etc/ssh/sshd_config
und folgende Zeile ändern
PermitRootLogin yes
und speichern.
systemctl restart ssh
Midnight Commander
Ein praktische Werkzeug ist auch der Midnight Commander.
apt install mc
gedit
Natürlich kann man die Dateien mit dem Nano bearbeiten. Praktischer ist jedoch der gedit.
Anmelden und als root arbeiten
Da üblicherweise kein root installiert wird, man aber die Rechte braucht, einfach mit su root und dem eigenen PW anmelden.
Wichtig
Riesen Unterschied zwischen su root der hat nur normalen User context undsu - root
Liefert auch Zugriff auf Programme die echte Root Privilegien erfordern. Z.B. das update-grub
IP Adresse des Rechners
ip address
Java installieren
www.azul.com, klick auf Downloads 
runterscrollen und Java8 LTS, Debian, x86 64.bit, JDK FX auswählen = 8u372b07
-
.deb herunterladen
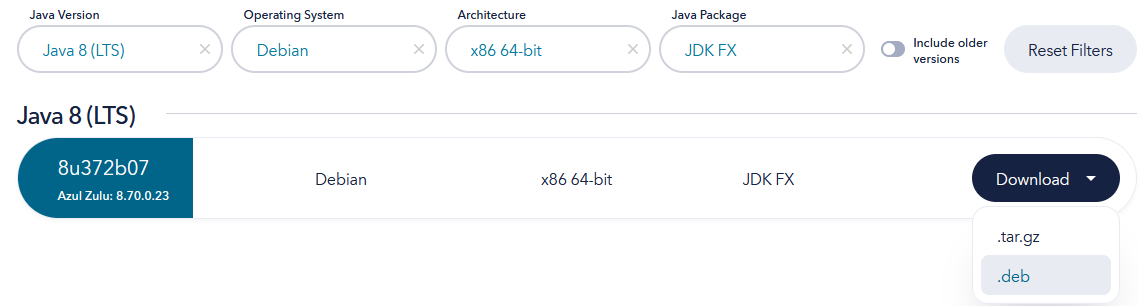
nur Java FX verwenden
WICHTIG: Achte darauf, das Java FX auszuwählen. Alle anderen werden immer wieder mal Abstürzen. -
Terminal öffen,
-
su - root
-
auf das home des herunterladenden Users wechseln und ins Downloads, z.B. /home/keg/Downloads
-
apt install ./zulu8.70.0.23-ca-fx-jdk8.0.372-linux_amd64.deb
-
danach mit java -version überprüfen
Installation postgresql
- www.postgresql.org/download/linux/debian
- auf Copy Script klicken
- ins Terminal wechseln, in dem man als su - root angemeldet ist
- Einfügen (rechte Maus)
- hinten um -14 für Postgres 14 ergänzen und enter.
Prüfen ob läuft:
- systemctl is-enabled postgresql
- systemctl status postgresql
Password für User postgres setzen
-
sudo -u postgres psql
-
ALTER USER postgres WITH PASSWORD ‘postgres’; ACHTUNG: Beachte die GoDB
-
\q (um den psql Editor wieder zu verlassen)
Einstellungen anpassen
Einstellungen anpassen
WICHTIG: Die DateStyle Einstellungen prüfen. Der Default ist im Debian anders als im Windows und in jeder Linux Distribution ist es wiederum anders.-
Pfad: /etc/postgresql/14/main
-
Einstellen postgresql.conf
- listen_addresses = ‘*’ # what IP address(es) to listen on; ist im Debian default auf localhost
- datestyle = ‘iso, dmy’ # umstellen!
Auf die Timezone achten. Diese muss auf ‘Europe/Vienna’ (bzw. Berlin gerne auch Zuerich) stehen
-
Gegebenenfalls auch den Zugriff von außen einrichten. D.h.:
- Einrichten mit User postgres, PW: postgres
- Ergänzen der pg_hba.conf host all all 127.0.0.1/32 scram-sha-256 host all all 192.168.xx.0/24 scram-sha-256
-
Datenbankserver neu starten systemctl restart postgresql
Installation Kieselstein ERP, Version :
- Verzeichnis anlegen
- cd /opt
- mkdir kieselstein
- cd kieselstein
- mkdir dist
- mkdir data
- cd /opt
Installation Liquibase
Für die Datenbankmigrationen, muss das Tool liquibase installiert werden.
wget -O- https://repo.liquibase.com/liquibase.asc | gpg --dearmor > liquibase-keyring.gpg && \
cat liquibase-keyring.gpg | sudo tee /usr/share/keyrings/liquibase-keyring.gpg > /dev/null && \
echo 'deb [arch=amd64 signed-by=/usr/share/keyrings/liquibase-keyring.gpg] https://repo.liquibase.com stable main' | sudo tee /etc/apt/sources.list.d/liquibase.list
apt-get update
apt-get install liquibase
JAVA_HOME
Im Debian 11 ist das eigentliche Java unter /usr/lib/jvm/zulu-fx-8-amd64/jre/bin/java
Wir setzen die Enviroment Variable unter /etc/environment
- export JAVA_HOME=/usr/lib/jvm/zulu-fx-8-amd64/jre
- export KIESELSTEIN_DIST=/opt/kieselstein/dist
- export KIESELSTEIN_DATA=/opt/kieselstein/data
Anmerkung: Das wirkt nur für den Service nach einem Neustart des gesamten Systems.
Um den Server manuell starten zu können, empfiehlt sich die Einrichtung des unten beschriebenen Start.sh
Rechte setzen
Als su - root auf /opt wechseln und
chmod 777 kieselstein -R
ACHTUNG: Sicherheit!!
Herunterladen aktuelle Kieselstein ERP Version
Die Datei von Gitlab herunterladen, mit dem Archivemanager öffnen und in das dist die Dateien aus dem Archivemanager reinkopieren.
Erzeugen der Datenbanken
In das Verzeichnis /opt/kieselstein/dist/bootstrap/database wechseln
- sudo -u postgres ./createDb.sh
Anmerkung: damit wird das als User Postgres ausgeführt und daher das PostgresPW entsprechend 4x abgefragt - danach die Default Daten einfügen
sudo -u postgres ./fillDb.sh
Anmerkung: Auch hier das PW für den user Postgres angeben (1x)
Einrichten des Dienstes und starten des Servers
als root nach /opt/kieselstein/dist/bootstrap/service/linux
./install-kieselstein-services.sh
ausführen. Damit wird auch systemctl start kieselstein-main-server.service gestartet.
- Wichtig1: Es muss dafür das environment gesetzt worden sein, also auch an den Reboot denken.
- Wichtig2: du musst das als su - root ausführen. Achte auf den Unterschied, wo das Minuszeichen steht. Linux Knowledge
läuft der Server ?
bewährt hat sich das Laufen des Servers in folgender Reihenfolge zu prüfen:
- /opt/kieselstein/dist/wildfly-12.0..Final/standalone/deployments
Hier müssen für alle drei Dateien auch .deployed Dateien stehen - Prüfen ob die RestAPI geht:
einen Browser starten (Firefox), http://localhost:8280/kieselstein-rest-docs/ muss die Restapi Dokumentation bringen. Hier idealerweise interactive interface nutzen und beide Ping testen. - Client starten und mit Admin, admin anmelden.
Also unter /opt/kieselstein/dist/clients/kieselstein-ui-swing-xxxx.tar.gz mit dem Archivemanager öffnen und idealerweise nach /opt/kieselstein/dist/client/ entpacken und danach aus …/bin/ den ./kieselstein-ui-swing starten
Schriften installieren
Kommt beim Drucken die Meldung

Schriftart ’null’ am Server nicht verfügbar, so müssen die in den Reports verwendeten Schriften noch installiert werden.
Üblicherweise wird von Kieselstein ERP die Schriftart Arial verwendet. D.h. diese nachinstallieren. Dazu:
- herunterladen installationspaket: ttf-mscorefonts-installer_3.8_all.deb -> Download erlauben
- in das Downloadverzeichnis wechseln
- als su - root
apt install ./ttf-mscorefonts-installer_3.8_all.deb
lädt ein Menge Dateien von sourceforge herunter.
Am Besten danach den Server neu starten (shutdown -r now)
weiters zu tun
- Backup einrichten
- Einrichten der Zugriffe von anderen Rechner aus.
Installation auf Hyper V
Anmerkungen worauf bei der Installation mit Hyper V zu achten ist:
- Generation virtueller Computer -> 2. Generation
- Minimales und maximales Ram angeben
- Anzahl der erlaubten Prozessoren definieren
- SCSI-Controller
- Hinzufügen von DVD Laufwerk
- Imagedatei für Debian angeben
- Firmware
- Bootreihenfolge auf DVD Laufwerk
Anmerkung: Wenn das Ding nicht von dem ISO Image Boote will, die Netzwerkkarte auf nicht verbunden stellen
Ansicht
Wenn man nun versehentlich die Ansicht der VM auf 25% stellt, kann man nicht mehr zurück, weil das Menü nicht breit genug ist.
Der Trick der hilft ist,
- die Verbindung zur Maschine herstellen,
- die Maus über den Menüpunkt Ansicht stellen
- die VM mit Strg+S starten und sofort
- auf Ansicht klicken
- Dann wieder auf Automatik stellen Hat mit Debian nichts zu tun, auch wenn im Hyper V da einige andere Dinge fehlen.
Auflösung im Hyper V
Bildschirmauflösung unter Hyper V ändern, ergänzen des Booteintrages
- als root anmelden (su - root)
- auf etc/default wechseln
- mit nano die datei grub editieren und
- in der Zeile die mit GRUB_CMDLINE_LINUX_DEFAULT beginnt hinten
video=hyperv_fb:<Breite>x<Höhe>
dazuschreiben. z.B.: Breite = 1680 x 1050
ACHTUNG: muss unter Hochkommas sein. D.h. die Zeile lautet dann
GRUB_CMDLINE_LINUX_DEFAULT=“quiet splash video=hyperv_fb:1680×1050”- danach update-grub
- danach neu starten (shutdown -r now)
1.3 - Installation Kieselstein ERP Server unter Debian
Installation Kieselstein ERP Server unter Debian
Den Kieselstein ERP Server auf einem frischen Debian installieren.
in DEUTSCH installieren
Default MUSS das Betriebssystem in de (deutsch) installiert sein und in der richtigen Timezone. Alles andere artet in Arbeit aus.Dauer ca. 30 Minuten
SSH-Server einrichten
OpenSSH Server installieren
apt update
apt upgrade
apt install openssh-server
Datenbank
Installation
apt-get install wget sudo curl gnupg2
sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
apt-get install postgresql-15
Konfiguration anpassen
Mit vi oder anderen Texteditor öffnen.
vi /etc/postgresql/15/main/postgresql.conf
Hier müssen das Datums-Format und die Zeitzone umgestellt werden.
datestyle = 'iso, dmy'
timezone = 'Europe/Vienna'
# Auf die Timezone achten. Diese muss auf ‘Europe/Vienna’ (bzw. Berlin gerne auch Zuerich) stehen
Zugriffskonfiguration
Sollte ein Zugriff von einem anderen System auf die Datenbank notwendig sein, muss hier auch der listen_addresses Wert
gesetzt werden (auf * für alle, bzw. die IP-Adressen welche unbedingt Zugriff auf die Datenbank brauchen).
Gegebenenfalls auch den Zugriff von außen einrichten. D.h.:
- Einrichten mit User postgres, PW: postgres
- Ergänzen der /etc/postgresql/15/main/pg_hba.conf host all all 127.0.0.1/32 scram-sha-256 host all all 192.168.xx.1/24
Prüfen ob die Datenbank läuft:
systemctl is-enabled postgresql
systemctl status postgresql
Datenbank-Passwort setzen
Datenbank öffnen
sudo -u postgres psql
Passwort für den Datenbankbenutzer setzen:
ALTER USER postgres WITH PASSWORD '<Sicheres Passwort>';
exit
Hinweis: Es sollte ein sicheres Passwort verwendet werden, welches über einen Passwort-Generator erstellt wurde (Achtung das Passwort wird hier in folgenden Schritten noch benötigt!).
Java installieren
Download der Java Version:
wget https://cdn.azul.com/zulu/bin/zulu11.74.15-ca-fx-jdk11.0.24-linux_amd64.deb
Alternativ kann der Download auch über die Azul-Seite erfolgen.
Siehe hierfür auch Java-Version.
Installation der Java Version:
Den folgenden Befehl im Download-Verzeichnis der Java-Version ausführen.
apt install ./zulu11.74.15-ca-fx-jdk11.0.24-linux_amd64.deb
Installation überprüfen:
java -version
Installation Liquibase
Für die Datenbankmigrationen, muss das Tool liquibase installiert werden.
wget -O- https://repo.liquibase.com/liquibase.asc | gpg --dearmor > liquibase-keyring.gpg && \
cat liquibase-keyring.gpg | sudo tee /usr/share/keyrings/liquibase-keyring.gpg > /dev/null && \
echo 'deb [arch=amd64 signed-by=/usr/share/keyrings/liquibase-keyring.gpg] https://repo.liquibase.com stable main' | sudo tee /etc/apt/sources.list.d/liquibase.list
apt-get update
apt-get install liquibase
Schriften Installieren
Damit die Reports funktionieren, muss die Schriftart Arial installiert werden. Dies kann unter Linux so durchgeführt werden.
wget http://ftp.de.debian.org/debian/pool/contrib/m/msttcorefonts/ttf-mscorefonts-installer_3.8_all.deb
apt install ./ttf-mscorefonts-installer_3.8_all.deb
Umgebungsvariablen setzen
Mit vi oder nano oder anderem Texteditor öffnen.
vi /etc/environment
Wichtig! Die Umgebungsvariablen müssen OHNE export hinzugefügt werden.
- JAVA_HOME=/usr/lib/jvm/zulu-fx-11-amd64
- KIESELSTEIN_DIST=/opt/kieselstein/dist
- KIESELSTEIN_DATA=/opt/kieselstein/data
- MAIN_DB_PASS=(Sicheres Passwort welches für den Datenbank-Benutzer verwendet wurde)
- DOC_DB_PASS=(Sicheres Passwort welches für den Datenbank-Benutzer verwendet wurde)
Optional kann auch die KIESELSTEIN_WILDFLY_CONFIG Umgebungsvariable gesetzt werden.
Wichtig ist dabei das die Variable keine anderen Variablen beinhalten darf.
Bsp: KIESELSTEIN_WILDFLY_CONFIG=/opt/kieselstein/data/wildfly
Es müssen dann noch einmalig folgende files vom wildfly ordner in den KIESELSTEIN_WILDFLY_CONFIG kopiert werden.
/opt/kieselstein/dist/wildfly-26.1.2.Final/standalone/configuration/
- application-roles.properties
- application-users.properties
- mgmt-groups.properties
- mgmt-users.properties
Danach noch einen Applikations-User mit /opt/kieselstein/dist/wildfly-26.1.2.Final/bin/add-user.sh hinzufügen.
source /etc/environment
oder Server Neustarten
reboot
Installation Kieselstein ERP, Version (aktuelle Version):
Verzeichnisse anlegen:
mkdir /opt/kieselstein
mkdir /opt/kieselstein/dist
mkdir /opt/kieselstein/data
Herunterladen aktuelle Kieselstein ERP Version
Dist-Paket über die bestehende Installation entpacken (In der Windows Eingabeaufforderung cmd.exe) Beispiel:
# Beispiel für Download des Dist-Pakets.
wget https://gitlab.com/kieselstein-erp/sources/kieselstein/-/jobs/7650408929/artifacts/raw/kieselstein-distpack/build/distributions/kieselstein-distpack-1.0.0-rc.1.tar.gz
# Beispiel für das Entpacken des Dist-Packets.
tar -xvf ./kieselstein-distpack-1.0.0-rc.1.tar.gz -C /opt/kieselstein
Datenbank Initialisieren
cd /opt/kieselstein/dist/bootstrap/liquibase/
./createdb.sh
Hier muss dann 4x das Passwort für den Postgres-Benutzer eingegeben werden.
Danach auch die default Datenbank auf den aktuellen Stand deines Kieselstein Servers heben.
./liquibase.sh update
Einrichten des Dienstes und starten des Servers
cd /opt/kieselstein/dist/bootstrap/service/linux
./install-kieselstein-services.sh
ausführen. Damit wird auch systemctl start kieselstein-main-server.service gestartet.
ACHTUNG: Es muss dafür das environment gesetzt worden sein
WildFly user hinzufügen
Wird für BasicAuth bei EDIFACT und CLEVERCURE benötigt.
KIESELSTEIN_DATA/wildfly Ordner erstellen und die folgenden Dateien aus KIESELSTEIN_DIST/wildfly-26.1.2.Final/standalone/configuration hinein kopieren.
- application-roles.properties
- application-users.properties
- mgmt-groups.properties
- mgmt-users.properties
NGINX Webserver (Optional)
Sollte für die REST-Schnittstelle ein eigener Port notwendig sein. Damit der Zugriff zum Beispiel über das Internet zur Verfügung gestellt werden kann oder bestehende Zeiterfassung-Terminals oder andere Anwendungen bereits den Port: 8280 verwenden kann ein Nginx-Webserver als Proxy hierfür installiert werden.
# Nginx-Webserver installieren:
apt install nginx
# Konfiguration für Kieselstein verlinken:
ln -s /opt/kieselstein/dist/bootstrap/nginx/kieselstein.conf /etc/nginx/sites-enabled/kieselstein-main.cfg
# Testen ob die Konfiguration gültig ist:
nginx -t
# Nginx-Webserver Dienst neustarten
systemctl restart nginx
Für das Freischalten im Internet sollte auf jeden Fall ein SSL-Zertifikat noch hinterlegt werden (siehe hier auch Configuring HTTPS servers bzw. Nginx-Webserver)
Zum Überpüfen ob der Nginx funktioniert und mit dem Kieselstein kommuniziert kann die Url: http://(Name oder IP-Adresse des Servers):8280/kieselstein-rest/services/rest/api/v1/system/ping aufgerufen werden.
läuft der Server ?
bewährt hat sich das Laufen des Servers in folgender Reihenfolge zu prüfen:
- /opt/kieselstein/dist/wildfly-26.1.2.Final/standalone/deployments/
Hier müssen für alle drei Dateien auch .deployed Dateien stehen - Prüfen ob die RestAPI geht:
einen Browser starten, http://localhost:8080/kieselstein-rest-docs/ muss die Restapi Dokumentation bringen. Bzw. auch mit dem Nginx-Port http://localhost:8280/kieselstein-rest-docs/ aufrufen (falls Nginx-Installiert wurde). - Client starten und mit Admin, admin anmelden.
weiters zu tun
- Backup einrichten
- Einrichten der Zugriffe von anderen Rechner aus.
1.3.1 - Update Kieselstein ERP Server von Version 0.2.x auf 1.x.x unter Debian
Migration von Kieselstein Version 0.2.x auf 1.x.x mit Java-11 Installation unter Debian.
Wenn eine bestehende Kieselstein Installation mit der Version 0.2.x vorhanden ist, können folgende Schritte für das Update auf Version 1.x.x durchgeführt werden.
Falls möglich, snapshot vom Server machen.
Kieselstein Dienste deaktivieren
Dienste beenden
- Beide Kieselstein Dienste (Kieselstein Main Server & Kieselstein REST Server) beenden
systemctl stop kieselstein-main-server.service
# REST Service kann gelöscht werden da dieser jetzt im Wildfly integriert ist.
systemctl stop kieselstein-rest-server.service
systemctl disable kieselstein-rest-server.service
rm /etc/systemd/system/kieselstein-rest-server.service
Backup des Kieselstein Dist-Verzeichnis erstellen
Das aktuell installierte Kieselstein in ein eigenes Verzeichnis mit der aktuellen Versionsnummer im Namen wegsichern. Beispiel:
cp -r /opt/kieselstein/ /opt/kieselstein-0.2.10
Neues Java Installieren
- Azul Java 11 mit FX installieren Siehe hierfür auch Java-Version.
Altes Java Deinstallieren (optional)
apt remove <Pfald zum alten Java-Deb-Paket.>
JAVA_HOME Umgebungsvariablen anpassen
Mit vi oder Nano oder einem anderen Texteditor öffnen.
vi /etc/environment
Nur den Wert für JAVA_HOME anpassen, alles andere kann so bleiben wie es ist.
- JAVA_HOME=/usr/lib/jvm/zulu-fx-11-amd64
Neue Umgebungsvariable laden
source /etc/environment
Nicht mehr benötigte Anwendungen entfernen
Reports sichern
Damit die Anwender-Reports nach dem Update wieder zur Verfügung stehen, muss der Reports-Ordner in ein neues Verzeichnis kopiert werden.
mkdir /opt/kieselstein/dist/wildfly-26.1.2.Final/
mkdir /opt/kieselstein/dist/wildfly-26.1.2.Final/kieselstein/
cp -r /opt/kieselstein/dist/wildfly-12.0.0.Final/server/helium/report/ /opt/kieselstein/dist/wildfly-26.1.2.Final/kieselstein/reports/
WICHTIG: Dies muss vor dem Entpacken des neuen Dist-Packets erfolgen, damit neuere Versionen der Standard-Reports richtig nachgezogen werden.
ACHTUNG
Obige Beschreibung gilt nur für die 1.0.x VOR der 1.0.3. Ab der 1.0.3 ist auch die Verlagerung der Anwenderreprots nach ../kieselstein/data/reports gegeben. Für Details dazu siehe bitte( /docs/installation/10_reportgenerator/anwenderreports/ )Alte Programmdateien löschen
Folgende Ordner können nun komplett gelöscht werden:
rm -rf /opt/kieselstein/dist/apache-tomcat-*
rm -rf /opt/kieselstein/dist/bin
rm -rf /opt/kieselstein/dist/bootstrap
rm -rf /opt/kieselstein/dist/service
rm -rf /opt/kieselstein/dist/wildfly-12.0.0.Final
Installation Kieselstein ERP, Version (aktuelle Version):
Herunterladen aktuelle Kieselstein ERP Version
Dist-Paket über die bestehende Installation entpacken (In der Windows Eingabeaufforderung cmd.exe) Beispiel:
# Beispiel für Download des Dist-Pakets.
wget https://gitlab.com/kieselstein-erp/sources/kieselstein/-/jobs/7650408929/artifacts/raw/kieselstein-distpack/build/distributions/kieselstein-distpack-1.0.0-rc.1.tar.gz
# Beispiel für das Entpacken des Dist-Packets.
tar -xvf ./kieselstein-distpack-1.0.0-rc.1.tar.gz -C /opt/kieselstein
Datenbank Updaten
cd /opt/kieselstein/dist/bootstrap/liquibase/
./liquibase.sh update
Hinweis: Wenn die bestehende Kieselstein Version kleiner als 0.0.13 ist:
Dann muss dem Liquibase noch mitgeteilt werden, dass es bereit die Grund-Datenstruktur gibt, somit muss vor dem Befehl
./liquibase.sh updatenoch folgender Befehl aufgerufen werden:./liquibase.sh changelog-sync --label-filter="0.0.12"
Einrichten des Dienstes und starten des Servers
cd /opt/kieselstein/dist/bootstrap/service/linux
./install-kieselstein-services.sh
NGINX Webserver (Optional)
Die Kieselstein-REST Schnittstelle wurde mit dem Update in den Wildfly integriert und ist somit auch über den Port: 8080 erreichbar.
Sollte es notwendig sein, dass diese wie bisher über den Port 8280 erreichbar ist, kann hier ein Nginx-Webserver als Proxy vorgeschaltet werden (Siehe NGINX Webserver)
Läuft der Server ?
Siehe Läuft der Server
Dokumentendatenbank Workspace.xml anpassen
Wenn eine bestehende Dokumentendatenbank existiert, müssen hier folgende Parameter Werte (Achtung diese Werte sind 2x in der XML-Datei vorhanden) angepasst werden:
/opt/kieselstein/data/jackrabbit/workspaces/default/workspace.xml
- driver: javax.naming.InitialContext
- url: java:/JRDS
Und folgende Parameter können gelöscht werden:
- user
- password
Beispiel:
Alte XML-Datei
<?xml version="1.0" encoding="UTF-8"?>
<Workspace name="default">
<FileSystem class="org.apache.jackrabbit.core.fs.db.DbFileSystem">
<param name="driver" value="org.postgresql.Driver"/>
<param name="url" value="jdbc:postgresql://${org.kieselstein.db-doc.host}:${org.kieselstein.db-doc.port}/${org.kieselstein.db-doc.name}"/>
<param name="schema" value="postgresql"/>
<param name="user" value="postgres"/>
<param name="password" value="postgres"/>
<param name="schemaObjectPrefix" value="ws_"/>
</FileSystem>
<PersistenceManager class="org.apache.jackrabbit.core.persistence.bundle.PostgreSQLPersistenceManager">
<param name="driver" value="org.postgresql.Driver"/>
<param name="url" value="jdbc:postgresql://${org.kieselstein.db-doc.host}:${org.kieselstein.db-doc.port}/${org.kieselstein.db-doc.name}"/>
<param name="user" value="postgres"/>
<param name="password" value="postgres"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="jcr_${wsp.name}_"/>
<param name="externalBLOBs" value="false"/>
</PersistenceManager>
<SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
<param name="path" value="${wsp.home}/index"/>
</SearchIndex>
</Workspace>
Neue XML-Datei:
<?xml version="1.0" encoding="UTF-8"?><Workspace name="default">
<FileSystem class="org.apache.jackrabbit.core.fs.db.DbFileSystem">
<param name="driver" value="javax.naming.InitialContext"/>
<param name="url" value="java:/JRDS"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="ws_"/>
</FileSystem>
<PersistenceManager class="org.apache.jackrabbit.core.persistence.pool.PostgreSQLPersistenceManager">
<param name="driver" value="javax.naming.InitialContext"/>
<param name="url" value="java:/JRDS"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="jcr_${wsp.name}_"/>
<param name="externalBLOBs" value="false"/>
</PersistenceManager>
<SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
<param name="path" value="${wsp.home}/index"/>
</SearchIndex>
</Workspace>
Datei basierte Dokumenten Datenbank
Man kann das jackrabbit config file mit der DOC_CONFIG Umgebungsvariable ändern.
Umgebungsvariable auf den folgenden Wert setzen um die Datei-basierte Dokumenten Datenbank zu verwenden.
DOC_CONFIG=/opt/kieselstein/conf/jackrabbit-datastore-fs.xml
Die dokumente werden standardmäsßig in folgenden Ordner gespeichert. Kann mit der DOC_REPO Umgebungsvariable geändert werden.
DOC_REPO=/opt/kieselstein/data/jackrabbit
<?xml version="1.0" encoding="UTF-8"?>
<Repository>
<Security appName="Jackrabbit">
<AccessManager class="org.apache.jackrabbit.core.security.simple.SimpleAccessManager"/>
<LoginModule class="org.apache.jackrabbit.core.security.simple.SimpleLoginModule">
<param name="anonymousId" value="anonymous"/>
</LoginModule>
</Security>
<Workspaces rootPath="${rep.home}/workspaces" defaultWorkspace="default"/>
<DataStore class="org.apache.jackrabbit.core.data.FileDataStore">
<param name="path" value="${rep.home}/datastore"/>
<param name="minRecordLength" value="100"/>
</DataStore>
</Repository>
weiters zu tun
- Clients Updaten (diese benötigen jetzt auch Java 11) siehe auch
- Wenn Nginx nicht installiert wurde bei allen Zeiterfassung-Terminals oder anderen Programmen, welche die REST-Schnittstelle verwenden, den Port auf 8080 ändern.
Empfehlung:
Insbesondere für die Tests in der ersten Zeit, sollte für ein eventuelles Fallback auf den Clients sowohl die Version für den Java 8 Server als auch für den Java 11 Server parallel vorgehalten werden. Damit man, im schlimmsten Falle, schnell auf die Vorgängerversion zurückwechseln kann.
1.4 - Installation Kieselstein ERP Server unter Ubuntu
Installation Kieselstein ERP Server unter Ubuntu
Hier kommen die eventuellen Besonderheiten zu einer Ubuntu Installation rein. Aktuell bitte wie unter Debian beschrieben vorgehen.
www.azul.com/downloads/ … damit die Werbung nicht kommt
wenn apt nicht gegangen weil z.B. zu wenig Rechte dann apt reinstall usw.
apt install postgresql holt die aktuellste Postgresversion derzeit 16 ACHTUNG: Installiert OHNE Passwort. daher su postgres psql damit bist du im Scripteditor commander nun
Ubuntu Version lsb_release -a
su postgres -> der Sudo geht irgendwie nicht Mit sudo su kannst du auch root rechte bekommen
Anmerkung Wenn das kopieren per Fernwartung nicht geht, dann über den Firefox auf die docs.kieselstein-erp.org gehen und von dort doe Kommandos herauskopieren. Im Ubuntu dann mit rechter Maustaste in den Eingabefeldern einfügen.
Je nach Maschine für das filldb sich etwas gedulden. Das kann dauern.
export KIESELSTEIN_JAVA_OPT_XMX=5G export KIESELSTEIN_JAVA_OPT_XMS=512m
reboot … = shutdown -r now
1.5 - Installation Kieselstein ERP Server unter Windows(r)
Installation Kieselstein ERP Server unter Windows(r)
Hier findest du ergänzende Punkte zur Installatiion unter Windows. Die Standard-Installation ist im Hauptkapitel beschrieben.
Firewall
Nach der Installation und dem erfolgreichen Test daran denken, dass in der Regel, zumindest für den Port 8080.
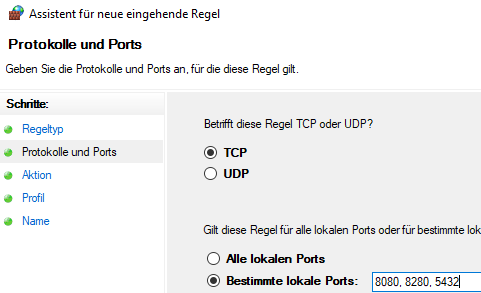
8280 wenn auch die Rest-API verwendet werden sollte
5432 wenn auch von innerhalb des Netzwerkes auf den PostgresQL zugegriffen werden sollte.
ACHTUNG: Sicherheit!!
Der Server startet nicht
Im Deploymentsverzeichnis (?:\Kieselstein\dist\wildfly-12.0.0.Final\standalone\deployments) steht kieselstein-0.0.11.ear.failed.
Ev. auch nur jackrabbit-jca-1.5.7.rar.failed.
So kann man in den beiden Dateien nachsehen.
Effizienter ist vermutlich in der ?:\Kieselstein\dist\wildfly-12.0.0.Final\standalone\log\server.log nachzusehen.
Dafür zuerst das log Verzeichnis löschen um nur die aktuellsten Einträge zu bekommen und dann den Server erneut starten, bis wiederum im Deplomentsverzeichnis das failed kommt.
Nun sucht man in der server.log am Besten von oben nach dem ersten Eintrag mit Error. Meist findet man einen Eintrag wie z.B.:
2023-09-22 17:15:23,014 ERROR [org.apache.jackrabbit.core.fs.db.DatabaseFileSystem] (MSC service thread 1-3) failed to initialize file system: org.postgresql.util.PSQLException: FATAL: Passwort-Authentifizierung f�r Benutzer �postgres� fehlgeschlagen
Dies bedeutet, dass der Applikationsserver sich nicht an der Datenbank anmelden konnte. Versuche nun dich mittels PGAdmin auf der Datenbank mit postgres, postgres anzumelden. Ist dies nicht möglich, stimmt das Passwort der Datenbank nicht. Eventuell wurde bei der Installation des Postgresservers ein falsches oder kein Passwort vergeben. D.h. es muss das Passwort geändert werden. Wenn du das andere(falsche) Passwort kennst, melde dich mit diesem an und ändere das Passwort. Wenn du dieses nicht kennst, muss zuerst der Zugang zum PostgresQL-Server auf dem Rechner auf dem dieser läuft so freigeschaltet werden, dass du dich auch ohne Passwort anmelden kannst. Dafür muss die pg_hba.conf angepasst werden. Diese findest du unter “?:\Program Files\PostgreSQL\14\data". Ergänze diese nun abhängig von deiner IP-Konfiguration um
- host all all 127.0.0.1/32 trust (IP V4)
- host all all ::1/128 trust (IP V6)
Nun muss der postgresql Dienst neu gestartet werden.
Wechsle nun als Administrator nach ?:\Program Files\PostgreSQL\14\bin
und rufe psql.exe -U postgres auf
Nun mit
\password postgres
das Passwort auf postgres setzen und dann mit
\q
Das Programm wieder verlassen.
Nun musst du dich auch im PGAdmin mit dem Passwort anmelden können.
Bitte beachte, dass ab PostgresQL 15 der PGAdmin 7 zum Einsatz kommen sollte.
Info:
Bei der Modifikation der pg_hba.conf auf IP V4 bzw. IP V6 achten! Kommt
psql: Fehler: Verbindung zum Server auf »localhost« (::1)
So fehlt der passende Eintrag in der pg_hba.conf
Info:
Nach diesen Änderungen empfiehlt sich auch die Verzeichnisse log, tmp, data aus dem standalone (?:\kieselstein\dist\wildfly-12.0.0.Final\standalone) zu löschen, damit die ganzen falschen Einträge weg sind.
1.6 - Installation Kieselstein ERP Server unter Windows
Installation Kieselstein ERP Server unter Windows
Den Kieselstein ERP Server auf einem frischen Windows installieren.
Installation Datenbankserver
Es werden aktuell ausschließlich PostgresQL Version 14 und 15 unterstützt. MS-SQL wird nicht unterstützt. Für eine eventuelle Konvertierung deiner MS-SQL Datenbank wende dich bitte an die Kieselstein ERP eG. Neuere PostgresQL Versionen können funktionieren, sind aber aktuell von uns nicht freigegeben.
Bei der Installation darauf achten, dass nur PostgresSQL Server und die Command Line Tools installiert werden.

Bei der Installation muss auch das Passwort für den User Postgres angegeben werden.
Hinweis: Es sollte ein sicheres Passwort verwendet werden, welches über einen Passwort-Generator erstellt wurde (Achtung das Passwort wird hier in folgenden Schritten noch benötigt!).
Java installieren
- Azul Java 11 mit FX installieren Siehe hierfür auch Java-Version.
- darauf achten, dass Java Home gesetzt wird
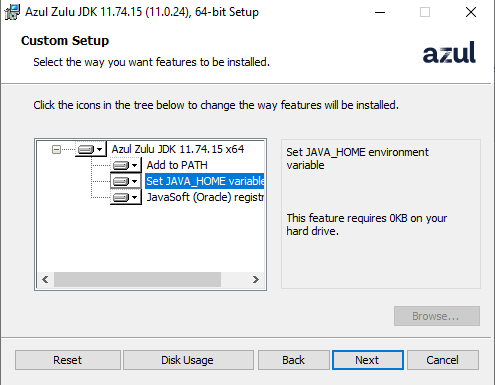
- Prüfen, dass Java auch installiert wurde durch Command Shell,
Java -version
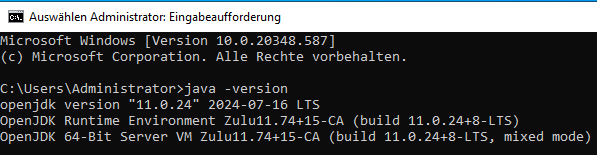
Setzen Environmentvariable
- path Erweiterung auf Postgres “?:\Program Files\pgAdmin 4\v6\runtime”
- KIESELSTEIN_DIST=?:\kieselstein\dist
- KIESELSTEIN_DATA=?:\kieselstein\data
- MAIN_DB_PASS=(Das oben definierte Datenbank-Passwort)
- DOC_DB_PASS=(Das oben definierte Datenbank-Passwort)
Optional kann auch die KIESELSTEIN_WILDFLY_CONFIG Umgebungsvariable gesetzt werden.
Wichtig ist dabei das die Variable keine anderen Variablen beinhalten darf.
Bsp: KIESELSTEIN_WILDFLY_CONFIG=?:\kieselstein\data\wildfly
Es müssen dann noch einmalig folgende files vom wildfly ordner in den KIESELSTEIN_WILDFLY_CONFIG kopiert werden.
?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\configuration
- application-roles.properties
- application-users.properties
- mgmt-groups.properties
- mgmt-users.properties
Danach noch einen Applikations-User mit \opt\kieselstein\dist\wildfly-26.1.2.Final\bin\add-user.bat hinzufügen.
Es gibt noch weitere optionale Environment-Variablen welche in der README.md Datei bei den Start-Scripten (im KIESELSTEIN_DIST/bin/) beschrieben sind.
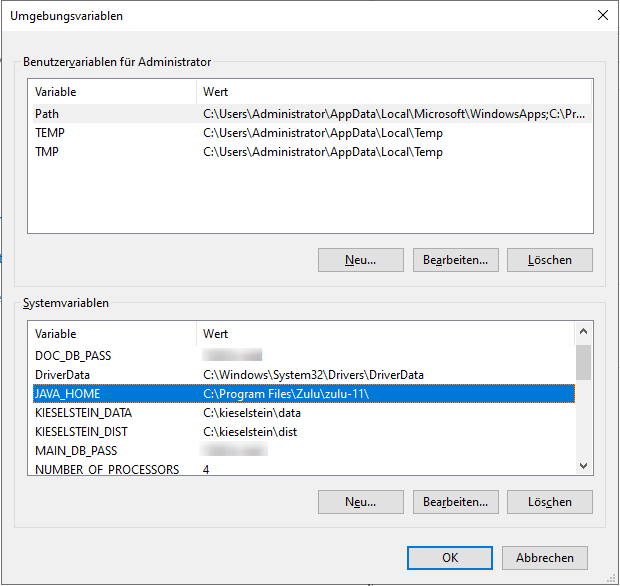
Achtung: Damit die Umgebungsvariablen für den Kieselstein-Dienst funktionieren, müssen diese als Systemvariablen hinterlegt werden.
Installation Liquibase
Für die Datenbankmigrationen muss das Tool liquibase installiert werden.
Aktuelle Liquibase Version vom git Repository runterladen:
https://github.com/liquibase/liquibase/releases
Hier bis zu den Assets runterscrollen und dann den passenden (Windows-)Installer auswählen. Z.B.: liquibase-windows-x64-installer-x.x.x.exe

Den Installer am Server ausführen und durchklicken.
Bitte darauf achten, dass Add Liquibase to PATH angehakt bleibt.

Achtung nach der Installation von Liquibase müssen für die weiteren Arbeiten neue Eingabeaufforderungen (cmd) gestartet werden! Ein Neustart des Servers ist nicht erforderlich.
ACHTUNG
Das Liquibase ergänzt die Pfad-Angabe nur benutzerspezifisch.Das bedeutet, wenn du danach das Update unter einem anderen Benutzer machst, hast du keinen Zugriff mehr.
Unsere Empfehlung:
Verschiebe die Pfad-Ergänzung von den Benutzervariablen in die Systemvariablen.
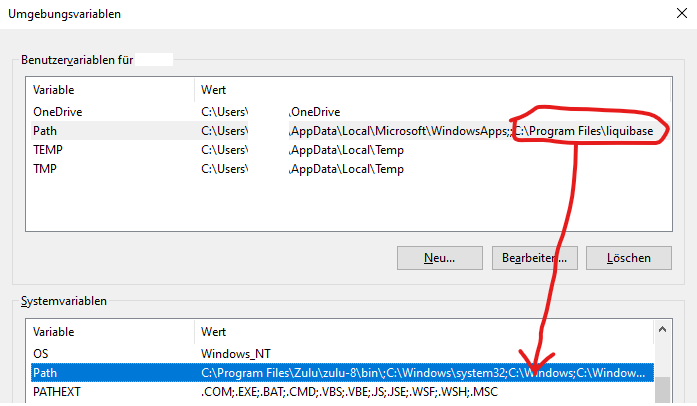
Installation Kieselstein ERP, Version (aktuelle Version):
Herunterladen aktuelle Kieselstein ERP Version
Dist-Paket über die bestehende Installation entpacken (In der Windows Eingabeaufforderung cmd.exe) Beispiel:
tar -xvf <pfad-zum-dist-packet>.gz -C ?:\kieselstein\
Datenbank Initialisieren
Die installierte ?:\kieselstein\dist\bootstrap\liquibase\createdb.bat ausführen. Hier muss dann 4x das Passwort für den Postgres-Benutzer eingegeben werden.
In der Command Shell in das Verzeichnis navigieren und mit liquibase den update Befehl durchführen:
cd ?:\kieselstein\dist\bootstrap\liquibase
run-liquibase.bat update
Einrichten des Dienstes und starten des Servers
Mit Administrationsrechten das Install-Script ?:\kieselstein\dist\bootstrap\service\windows\install-kieselstein-services.bat ausführen.
NGINX Webserver (Optional)
Sollte für die REST-Schnittstelle ein eigener Port notwendig sein. Damit der Zugriff zum Beispiel über das Internet zur Verfügung gestellt werden kann oder bestehende Zeiterfassung-Terminals oder andere Anwendungen bereits den Port: 8280 verwenden, kann ein Nginx-Webserver als Proxy hierfür installiert werden.
Mit Administrationsrechten das Install-Script ?:\kieselstein\dist\bootstrap\service\windows\install-kieselstein-nginx-service.bat ausführen.
Für das Freischalten im Internet sollte auf jeden Fall ein SSL-Zertifikat noch hinterlegt werden (siehe hier auch Configuring HTTPS servers bzw. Nginx-Webserver)
Zum Überprüfen ob der Nginx funktioniert und mit dem Kieselstein kommuniziert, kann die Url: http://(Name oder IP-Adresse des Servers):8280/kieselstein-rest/services/rest/api/v1/system/ping aufgerufen werden.
TODO Hinterfragen ob die Config gleich ins richtige Verzeichnis vom Dist-Pack geladen werden kann oder ob das manuell gemacht werden muss.
läuft der Server?
bewährt hat sich, das Laufen des Servers in folgender Reihenfolge zu prüfen:
- ?:\kieselstein\dist\wildfly-26.1.2.Final\standalone\deployments/
Hier müssen für alle drei Dateien auch .deployed Dateien stehen - Prüfen ob die RestAPI geht:
einen Browser starten, http://localhost:8080/kieselstein-rest-docs/ muss die Restapi Dokumentation bringen. Bzw. auch mit dem Nginx-Port http://localhost:8280/kieselstein-rest-docs/ aufrufen (falls Nginx-Installiert wurde). - Client starten und mit Admin, admin anmelden.
weiters zu tun
- Backup einrichten
- Einrichten der Zugriffe von anderen Rechner aus.
Server startet nicht, was tun?
Wenn du Daten von anderen Installationen übernimmst, muss beim ersten Start deines Servers der Index der Dokumentendatenbank neu aufgebaut werden. Dies wird grundsätzlich vom Server unterstützt. Es kann aber unter Umständen so lange dauern, dass der Server von sich aus abbricht.
D.h. gegebenenfalls den Server mehrfach starten und oder zusätzlich das Timeout temporär höher drehen. D.h. im launch-kieselstein-main-server(.bat)
Linux (ca Zeile 60)
MAIN_SERVER_OPTS="${MAIN_SERVER_OPTS} -Djboss.as.management.blocking.timeout=3600"
Windows (ca Zeile 90)
set MAIN_SERVER_OPTS=%MAIN_SERVER_OPTS% -Djboss.as.management.blocking.timeout=3600
hinzufügen. Erhöht das Timeout auf eine Stunde.
1.6.1 - Update Kieselstein ERP Server von Version 0.2.x auf 1.x.x unter Windows
Migration von Kieselstein Version 0.2.x auf 1.x.x mit Java-11 Installation unter Windows.
Wenn eine bestehende Kieselstein Installation mit der Version 0.2.x vorhanden ist, können folgende Schritte für das Update auf Version 1.x.x durchgeführt werden.
Kieselstein Dienste deaktivieren
Dienste beenden
- Beide Kieselstein Dienste (Kieselstein Main Server & Kieselstein REST Server) beenden
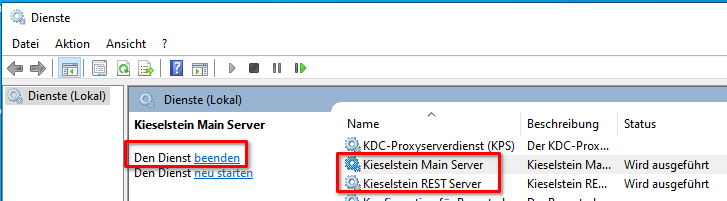
- nun die Dienste deinstallieren, also:
?:\kieselstein\dist\bootstrap\service\windows\delete-kieselstein-services.bat
Backup des Kieselstein Dist-Verzeichnis erstellen
Das aktuell installierte Kieselstein in ein eigenes Verzeichnis mit der aktuellen Versionsnummer im Namen wegsichern.
Beispiel: C:\kieselstein nach C:\kieselstein-0.2.10 kopieren.
Neues Java Installieren
-
Azul Java 11 mit FX installieren Siehe hierfür auch Java-Version.
-
darauf achten, dass Java Home gesetzt wird
-
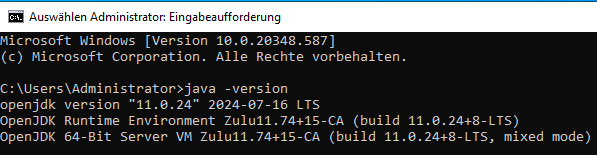
Prüfen, dass Java auch installiert wurde durch Command Shell,
Java -version
Altes Java Deinstallieren (optional)
Über “Programme hinzufügen oder entfernen” nach JDK Suchen und die Java 8 Version deinstallieren.
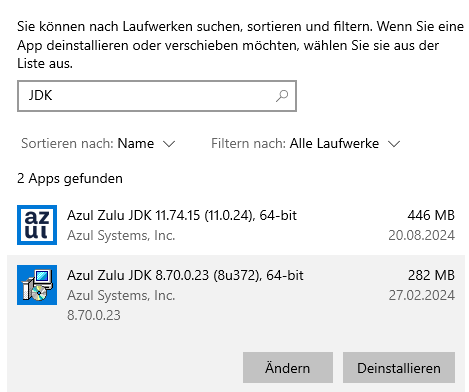
Achtung: Diesen Schritt nur durchführen, wenn auf dem Server sicher keine andere Anwendung mehr das Java 8 JDK benötigt!
Auf jeden Fall ist sicherzustellen, dass die JAVA_HOME Variable auf das Neue JDK 11 gesetzt wurde:

Nicht mehr benötigte Anwendungen entfernen
Bestehende Kieselstein Dienste deinstallieren
Dafür das Skript ?:\kieselstein\dist\bootstrap\service\windows\delete-kieselstein-services.bat mit Administrator Rechten ausführen.
Reports sichern
Damit die Anwender-Reports nach dem Update wieder zur Verfügung stehen, muss der Reports-Ordner in ein neues Verzeichnis kopiert werden.
Hier muss der bestehende ?:\kieselstein\dist\wildfly-12.0.0.Final\server\helium\report nach ?:\kieselstein\dist\wildfly-26.1.2.Final\kieselstein\reports kopiert werden.
WICHTIG: Dies muss vor dem Entpacken des neuen Dist-Packets erfolgen, damit neuere Versionen der Standard-Reports richtig nachgezogen werden.
ACHTUNG
Obige Beschreibung gilt nur für die 1.0.x VOR der 1.0.3. Ab der 1.0.3 ist auch die Verlagerung der Anwenderreprots nach ?:\kieselstein\data\reports gegeben. Für Details dazu siehe bitte( /docs/installation/10_reportgenerator/anwenderreports/ )ACHTUNG: Die Definitionen für dein JasperStudio entsprechend übertragen und auch die Einstellungen im Jasper Studio entsprechend anpassen.
Dies idealerweise bevor du die nachfolgenden Verzeichnisse löscht.
- In Jasperstudio direkt.
Eigenschaften des Projekts auf den neuen Pfad ändern.
Z.B. von …?:\kieselstein\dist\wildfly-12.0.0.Final\server\helium\report auf ?:\kieselstein\data\reports zu ändern.
Denke auch daran dass die .classpath entsprechend anzupassen ist
und denke an die Verlagerung der .settings, bin und an das Neu-Schreiben des .projects für JasperStudio.
Im Verzeichnis bin solltest du auch die aktuelle kieselstein-ejb-1.0.3.jar anstatt der bisherigen ejb.jar verwenden.
Alte Programmdateien löschen
Folgende Ordner können nun komplett gelöscht werden:
- ?:\kieselstein\dist\apache-tomcat-8.5.93
- ?:\kieselstein\dist\bin
- ?:\kieselstein\dist\bootstrap
- ?:\kieselstein\dist\service
- ?:\kieselstein\dist\wildfly-12.0.0.Final
Installation Kieselstein ERP, Version (aktuelle Version):
Herunterladen aktuelle Kieselstein ERP Version
TODO Referenz auf die richtige Version setzen.
Dist-Paket über die bestehende Installation entpacken (In der Windows Eingabeaufforderung cmd.exe) Beispiel
tar -xvf <pfad-zum-dist-packet>.gz -C ?:\kieselstein\
Datenbank Updaten
In der Command Shell in das Verzeichnis navigieren und mit liquibase den update Befehl durchführen:
cd C:\kieselstein\dist\bootstrap\liquibase
run-liquibase.bat update
Hinweis: Wenn die bestehende Kieselstein Version kleiner als 0.0.13 ist:
Dann muss dem Liquibase noch mitgeteilt werden, dass es bereit die Grund-Datenstruktur gibt, somit muss vor dem Befehl
run-liquibase.bat updatenoch folgender Befehl aufgerufen werden:run-liquibase.bat changelog-sync --label-filter="0.0.12"
Einrichten des Dienstes und starten des Servers
Mit Administrationsrechten das Install-Script ?:\kieselstein\dist\bootstrap\service\windows\install-kieselstein-services.bat ausführen.
NGINX Webserver (Optional)
Die Kieselstein-REST Schnittstelle wurde mit dem Update in den Wildfly integriert und ist somit auch über den Port: 8080 erreichbar.
Sollte es notwendig sein, dass diese wie bisher über den Port 8280 erreichbar ist, kann hier ein Nginx-Webserver als Proxy vorgeschaltet werden (Siehe NGINX Webserver)
läuft der Server?
Siehe Läuft der Server
Es hat sich bewährt nach einem Update, insbesondere nach dem Wechsel der Java Version, den Server manuell zu starten. D.h. mit administrativen Rechten das
?:\kieselstein\dist\bin\launch-kieselstein-main-server.bat
auszuführen.
Beobachte hier die Ausgabe der Console. Erscheint hier:
2024-09-19 10:58:50,075 ERROR [org.jboss.msc.service.fail] (ServerService Thread Pool -- 82) MSC000001: Failed to start service jboss.ra.deployer."jackrabbit-jca-2.22.0.rar": org.jboss.msc.service.StartException in service jboss.ra.deployer."jackrabbit-jca-2.22.0.rar": WFLYJCA0046: Failed to start RA deployment [jackrabbit-jca-2.22.0.rar]
at org.jboss.as.connector.services.resourceadapters.deployment.
...
Caused by: org.jboss.jca.deployers.common.DeployException: IJ020056: Deployment failed: jackrabbit-jca-2.22.0.rar
...
Caused by: java.lang.UnsupportedClassVersionError: Failed to link org/apache/jackrabbit/jca/JCAResourceAdapter (Module "deployment.jackrabbit-jca-2.22.0.rar" from Service Module Loader): org/apache/jackrabbit/jca/JCAResourceAdapter has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
this version of the Java Runtime only recognizes class file versions up to 52.0
so bedeutet dies, dass du vermutlich noch Java 8 auf deinem Server verwendest.
Gegebenenfalls willst du auf deinem Server, warum auch immer, auch noch Java 8 verwenden und hast daher beide Java Versionen installiert.
In diesem Falle muss das JAVA_HOME im Start-Batch
(?:\kieselstein\dist\bin\launch-kieselstein-main-server.bat) gesetzt werden.
Z.B. schreibst du in Zeile 3 set JAVA_HOME=c:\Program Files\Zulu\zulu-11, also den Pfad auf dein Java 11 rein.
Hinweis:
Wir raten, insbesondere am Server nur eine Java Version zu verwenden.Wir haben schon zu oft vermeintliche Fehler gesucht, die dann im Endeffekt die Ursache in einer falschen Javaversion hatten.
Dokumentendatenbank Workspace.xml anpassen
Wenn eine bestehende Dokumentendatenbank existiert, müssen hier folgende Parameter Werte (Achtung diese Werte sind 2x in der XML-Datei vorhanden) angepasst werden:
?:\kieselstein\data\jackrabbit\workspaces\default\workspace.xml
- driver: javax.naming.InitialContext
- url: java:/JRDS
Und folgende Parameter können gelöscht werden:
- user
- password
Beispiel:
Alte XML-Datei
<?xml version="1.0" encoding="UTF-8"?>
<Workspace name="default">
<FileSystem class="org.apache.jackrabbit.core.fs.db.DbFileSystem">
<param name="driver" value="org.postgresql.Driver"/>
<param name="url" value="jdbc:postgresql://${org.kieselstein.db-doc.host}:${org.kieselstein.db-doc.port}/${org.kieselstein.db-doc.name}"/>
<param name="schema" value="postgresql"/>
<param name="user" value="postgres"/>
<param name="password" value="postgres"/>
<param name="schemaObjectPrefix" value="ws_"/>
</FileSystem>
<PersistenceManager class="org.apache.jackrabbit.core.persistence.bundle.PostgreSQLPersistenceManager">
<param name="driver" value="org.postgresql.Driver"/>
<param name="url" value="jdbc:postgresql://${org.kieselstein.db-doc.host}:${org.kieselstein.db-doc.port}/${org.kieselstein.db-doc.name}"/>
<param name="user" value="postgres"/>
<param name="password" value="postgres"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="jcr_${wsp.name}_"/>
<param name="externalBLOBs" value="false"/>
</PersistenceManager>
<SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
<param name="path" value="${wsp.home}/index"/>
</SearchIndex>
</Workspace>
Neue XML-Datei:
<?xml version="1.0" encoding="UTF-8"?><Workspace name="default">
<FileSystem class="org.apache.jackrabbit.core.fs.db.DbFileSystem">
<param name="driver" value="javax.naming.InitialContext"/>
<param name="url" value="java:/JRDS"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="ws_"/>
</FileSystem>
<PersistenceManager class="org.apache.jackrabbit.core.persistence.pool.PostgreSQLPersistenceManager">
<param name="driver" value="javax.naming.InitialContext"/>
<param name="url" value="java:/JRDS"/>
<param name="schema" value="postgresql"/>
<param name="schemaObjectPrefix" value="jcr_${wsp.name}_"/>
<param name="externalBLOBs" value="false"/>
</PersistenceManager>
<SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
<param name="path" value="${wsp.home}/index"/>
</SearchIndex>
</Workspace>
weiters zu tun
- Clients Updaten (diese benötigen jetzt auch Java 11) siehe auch
- Wenn Nginx nicht installiert wurde bei allen Zeiterfassung-Terminals oder anderen Programmen, welche die REST-Schnittstelle verwenden, den Port auf 8080 ändern.
Empfehlung:
Insbesondere für die Tests in der ersten Zeit, sollte für ein eventuelles Fallback auf den Clients sowohl die Version für den Java 8 Server als auch für den Java 11 Server parallel vorgehalten werden. Damit man, im schlimmsten Falle, schnell auf die Vorgängerversion zurückwechseln kann.
1.7 - Installation Kieselstein ERP Server unter macOS
Installation Kieselstein ERP Server unter macOS
Hier findest du nur in textlicher Form zusammen gestellt, wie eine erste Installation unter MacOS erfolgen könnte.
Wir freuen uns, wenn ein entsprechender Profi, diese Beschreibung ergänzt.
Diese Installation baut auf der Kieselstein ERP Version 1.0.1 auf.
Wir haben auch einige Hintes für die Anwender anderer Betriebssysteme mit dazugegeben.
Wenn man im Finder verschiedene Devices usw. nicht findet, dann am Desktop auf Gehe Zu (Computer) und dann dieses Device links reinziehen. Ab dem Zeitpunkt ist es da.
Ab OS X Version 8? steht der Launcher zum starten der Dienste zur Verfügung launchctl start/stop (dienst) mit list sieht man alle Dienste und die die eine PID haben laufen
find / -name xxx*.* findet alle Dateien ab Root
Rechtsklick mit der Maus bringt Einsetzen (aus der zwischenablage)
prüfen welche Prozesse laufen
- ps aux | grep postgres
- Programme, Dienstprogramm, Aktivitätsanzeige
ev. aus dem /Library das Postgres komplett entfernen
wo bin ich?
mit pwd bekommt man den aktuelle Pfad im Terminal auf dem man steht
Downloads
idealerweise die Downloads über den Finder aus dem Download Verzeichnis starten
IP Adresse: ifconfig
Root user
Den Root User gibt es nicht wirklich, aber
sudo -s eigenes Password -> damit ich ausreichend Rechte habe
Postgres deinstallieren
??? open /Library/PostgreSQL/Version/uninstall-postgresql.app/Contents/MacOS/installbuilder.sh Sollte die Deinstallation nicht gehen, das Verzeichnis entfernen. Ev. dazu über Dienstprogramme, Aktivitäten den laufenden Prozess killen.
Postgres 15 installieren
- Bin als Administrator / mit administrativen Rechten angemeldet
- Download PostgresVersion 15.x
- dmg Datei aus Download öffnen und installieren. Auf den Port und das PW achten
- Pfad: /Library/PostgreSQL/15
ohne Stack Builder aber mit pgAdmin 4
Nach der Installation von PostgreSQL 15 findest du diesen direkt im Finder
Anpassen der Konfiguration
Je nach MAC Version und Postgresversion musst du die pg_hba.conf und die postgresql.conf anpassen. Siehe
Download Kieselstein ERP
von GitLab anscheinend nur mit Safari
Download Java11
Java11 auf die richtige Architektur achten (X64 oder ARM) JDK FX !!
altes / falsches Java deinstallieren
Java deinstallieren (laut Oracle)
- Klicken Sie im Dock auf das Finder-Symbol.
- Klicken Sie auf den Ordner Utilities
- Doppelklicken Sie auf das Terminal-Symbol
- Kopieren und fügen Sie die folgenden Befehle im Terminalfenster ein:
sudo rm -fr /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin
sudo rm -fr /Library/PreferencePanes/JavaControlPanel.prefPane
sudo rm -fr ~/Library/Application\ Support/Oracle/Java
Versuchen Sie nicht, Java zu deinstallieren, indem Sie die Java-Tools aus /usr/bin entfernen. Dieses Verzeichnis ist Teil der Systemsoftware. Änderungen werden von Apple zurückgesetzt, wenn Sie das nächste Mal ein BS-Update durchführen.
Verzeichnisse löschen mit File-Inhalten
rm -r Path
Kieselstein installieren
- /opt/kieselstein anlegen
- cd /opt
- mkdir kieselstein
- cd kieselstein
ins download wechseln, z.B. Finder und das .tar mittels Doppelklick entpacken
Das Dist kopieren und in der Hauptmenüleiste (ganz oben) mit Gehe Zu auf /opt/kieselstein wechseln und dort einsetzen (dorthin kopieren)
Environment-Variablen
Nun die Environmentvariablen anlegen / ergänzen
Laut einigen Beschreibungen sind diese für alle User auf /etc/bashrc … das File gegebenenfalls mit Nano anlegen export PATH=$PATH:/Library/PostgreSQL/15/bin export KIESELSTEIN_DATA=/opt/kieselstein/data/ export KIESELSTEIN_DIST=/opt/kieselstein/dist/ Terminal neu starten ev. mit printenv die ganzen environment variablen prüfen
ABER Es müssen diese auf meinen Mac in die bash-profile. Also:
- ~/.bash-profile eingeben. Damit findet man auch wo das File ist und dann ergänzen
mit Export, so wie oben beschrieben und wichtig danach
mit source ~/.bash-profile aktivieren
liquibase
herunterladen und installieren. Landet auf /usr/local/opt/liquibase
Datenbank einrichten
- Terminal neu starten
- im Terminal nun auf /opt/kieselstein/dist/bootstrap/liquibase wechseln
- createdb.sh ausführen und 4x pw eingeben
- dann aus dem Verzeichnis das ./liquibase.sh ausführen
Es dürfen keine Fehler kommen und es müssen 18 oder mehr updates ausgeführt angezeigt werden
Client am gleichen MAC starten
Im Finder aus /opt/kieselstein/dist/clients, das Kieselstein-client…tar mit Rechtsklick und Archivierungsprogramm öffnen. Damit bekommst du das in das clients mit den Unterverzeichnissen bin und lib
Wenn mehrfach verteilt werden sollte, die kieselstein-client.sh die IP Adresse anpassen
Nun den KES Server starten
auf /opt/kieselstein/dist/bin wechseln
und launch-kieselstein-main-server.sh
mit gehe zu auf deployment wechseln und prüfen ob startet
Nun den Client starten.
Um das aus dem Finder zu starten, musste du die Sicherheitseinstellungen erweitern D.h. Öffnen einer App durch Aussetzen der Sicherheitseinstellungen
- Suche im Finder auf deinem Mac nach der App, die du öffnen möchtest.
- Klicke bei gedrückter Taste „ctrl“ auf das Symbol der App und wähle „Öffnen“ aus dem Kontextmenü aus.
- Klicke auf „Öffnen“.
- Die App wird als Ausnahme zu deinen Sicherheitseinstellungen gesichert, sodass du sie künftig wie jede autorisierte App durch Doppelklicken öffnen kannst.
ToDos
zu klären sind noch folgende Dinge
- a.) wie den Dienst am MAC einrichten
- b.) wie das Desktop Icon einrichten
Zusatz-Infos
- Arbeitet man nicht auf einer echten MAC Tastatur sondern auf einer PC-USB Tastatur
- AltGR+7 = | Pipe
1.8 - Update
Muss ich regelmäßig updaten und wenn ja, was?
Für die Beschreibung des Server-Updates deiner Kieselstein ERP Installation siehe die betriebssystemspezifischen Updates in den Unterkapiteln
Allgemeine Punkte zum Thema Updaten / Aktualisieren
Da wir in der Praxis durchaus auch erleben, dass einfach ohne jegliche Notwendigkeit Updates eingespielt werden, hier unsere Gedanken und Informationen dazu.
Wir gehen hier davon aus, dass dein Kieselstein ERP-Server in einem sicheren Netzwerk betrieben wird.
Die nachfolgenden Infos sind für Server die vorne an der Front (= WorldWideWeb) stehen, wie z.B. WebServer, nicht zutreffend.
-
Wozu muss aktualisiert werden? Gibt es einen wichtigen Grund?
Nur dann sollte ein Update eingespielt werden.
Es gilt der alte Grundsatz, never touch a running system!
Wir können dies nur bestätigen. -
Die Kieselstein ERP eG mit Ihren Consultants sind KEINE IT-Betreuer.
Bitte suche dir einen sehr guten IT-Betreuer. Der auch etwas von IT-Infrastuktur versteht und auch weiß, warum man mechanisch getrennte Backups braucht. -
Welchen Wert hat dein ERP System für dein Unternehmen?
Welche Dinge werden passieren, wenn dein ERP nicht verfügbar ist?
- ich weiß nicht was ich heute produzieren sollte
- ich weiß nicht welche Waren ich einkaufen sollte
- ich kann keinen Kunden anrufen und ihm erklären, dass er seine Lieferung später bekommt
- ich habe keine Zeiterfassung meiner Mitarbeiter:innen und auch nicht meiner Maschinen
- das kann man noch lange fortsetzen
Wenn nun durch die, bei manchen Menschen ausgeprägte Update-Manie, täglich / wöchentlich neue Versionen in das Live-System eingespielt werden, das oft noch ohne ein qualifiziertes Backup / Fallback zu haben, dein ERP System, warum auch immer, nicht mehr funktioniert, so können wir von der Kieselstein ERP eG dazu nur sagen, Pech gehabt. Hoffentlich etwas dazu gelernt.
Unsere Techniker:innen sind Programmierer oder Consultants, aber keine IT-Leute die sich mit Servern und PC’s mehr als notwendig herum ärgern.
Richtige Update-Vorgehensweise
- Ist das Update wirklich notwendig
- erstelle ein vollwertiges Backup. Du musst im Falle des Falles auf diesen Stand zurückstellen können.
Manche unserer Mitglieder machen das in dem Sinne, dass die VM (virtuelle Maschine) des Echtsystems gesichert und kopiert wird. Beachte dazu das Thema vollwertige Sicherung einer VM mit der PostgresQL!
Nun können am Echtsystem die Updates durchgeführt werden. Sollten sich Probleme herausstellen, kann man auf die qualifizierte und vollwertige Sicherung zurückgreifen.
Oder es werden auf der kopierten VM die notwendigen Tests durchgeführt und erst danach die Updates am Echtsystem ausgerollt. - Selbstverständlich ist dein IT-Betreuer greifbar und deine Tests der neuen Version werden zu normalen Bürozeiten durchgeführt und sind nicht zeitkritisch. D.h. ob eine Fehlerbehebung einige Tage dauert ist nicht relevant.
Was mache ich, wenn mein System gecrasht ist
In solchen Fällen, welche in der Regel, bei gut gepflegter Hardware, sehr sehr selten auftreten, helfen wir nach besten Kräften. Wir wollen grundsätzlich dass die Systeme laufen. So ist es uns kürzlich gelungen, ein gechrastes Windowssystem mit guten vorhandenen Backupdaten innerhalb von wenigen Stunden, nachdem der neue Server wieder zur Verfügung gestanden ist, zum Laufen zu bringen.
Dein Kieselstein ERP läuft immer auf einem Server, auch wenn der Rechner mit vielleicht etwas geringerer Leistung ausgelegt ist.
Server sind immer mit gespiegelten Platten oder Raid-Platten ausgestattet. Es läuft eine Festplattenüberwachung und die Meldungen des Überwachungssystems werden erst genommen und umgehend, raschest möglich, durch deinen IT-Betreuer beseitigt.
Dass ein qualifiziertes und verifiziertes Backup zur Verfügung steht, ist selbstverständlich.
Zusammenfassend:
Seid euch selber des Wertes eurer Daten und Systeme bewusst. Durch die Update Manie wird nur eine Geringschätzung den eigenen Systemen gegenüber zum Ausdruck gebracht.
Update Prozess für dein Kieselstein ERP:
Vor jedem Update Prozess muss sowohl von der Datenbank als auch von den File-Systemen ein Backup gemacht werden.
Update Schritte je Betriebssystem:
Clients
Nach dem Update des Servers müssen auch die Clients wieder aktualisiert werden. Siehe hierfür bitte Installation Clients.
Sollte die Version des Kieselstein-Clients nicht mit der Version des Servers oder der Datenbank übereinstimmen kommt eine entsprechende Fehlermeldung und kann die Anmeldung nicht durchgeführt werden.
Fehlermeldungen mit Client-Version 0.0.13 oder kleiner:
 Dies wird nach dem anmelde Versuch bei Versionen, welche vor der Versionierung erstellt wurden angezeigt.
Hier muss das Client-Programm aktualisiert werden.
Dies wird nach dem anmelde Versuch bei Versionen, welche vor der Versionierung erstellt wurden angezeigt.
Hier muss das Client-Programm aktualisiert werden.
Ab Kieselstein Version 0.0.13 werden die jeweiligen Versionen angezeigt und die Anmeldung verhindert:
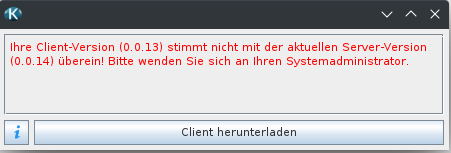
Troubleshooting
Wenn die Datenbankversion nicht mit der Wildfly Installation übereinstimmt,
kommt beim Starten des Clients folgende Fehlermeldung:
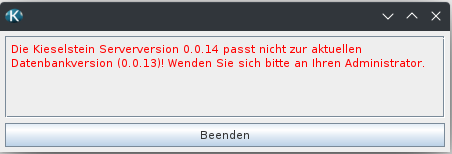 bzw. bei einem Umstieg von einer Version vor 0.0.13:
bzw. bei einem Umstieg von einer Version vor 0.0.13:
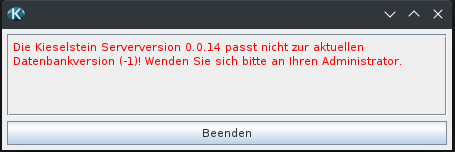
Am Server wird hier auch ein Fehler geloggt (kieselstein-dist/wildfly-12.0.0.Final/standalone/log/server.log)
2024-02-28 09:10:26,607 ERROR [com.lp.server.system.ejbfac.SystemFacBean] (EJB default - 8) Database version may not match server version (0.0.14)! Make sure the database was updated.: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1692)
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1619)
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.find(AbstractEntityManagerImpl.java:1106)
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.find(AbstractEntityManagerImpl.java:1033)
at org.jboss.as.jpa.container.AbstractEntityManager.find(AbstractEntityManager.java:213)
Hier muss der Dienst wieder gestoppt werden und das Liquibase update durchgeführt werden.
Releasehinweise
TODO Is a comming feature! In Zukunft kann es sein, dass nach einem Versionsupdate manuelle Datenbereinigungen durchgeführt werden müssen. Sollte eine solche Datenbereinigung notwendig sein, wird nach der Anmeldung eines Benutzer eine Liste (wenn mehrere) der noch nicht durchgeführten Aktionen angezeigt. Die Punkte in der Releasehinweise-Tabelle können nur von dem Kieselstein Admin-Benutzer als erledigt markiert werden. Solange noch nicht erledigte Releasehinweise vorhanden sind, werden diese jedem Benutzer bei der Anmeldunge angezeigt.
1.8.1 - Update Kieselstein ERP Server unter Debian
Update Kieselstein ERP Server unter Debian
Applicationsserver Updaten
- Dist-Pack auf den Server kopieren
- Dienste beenden
systemctl stop kieselstein-main-server.servicesystemctl stop kieselstein-rest-server.service
- Alte Programmdateien löschen:
rm /opt/kieselstein/dist/wildfly-*.Final/standalone/deployments/*.earrm /opt/kieselstein/dist/wildfly-*.Final/standalone/deployments/*.warrm /opt/kieselstein/dist/wildfly-*.Final/standalone/deployments/*.rarrm /opt/kieselstein/dist/wildfly-*.Final/standalone/deployments/*.deployedrm /opt/kieselstein/dist/apache-tomcat-*/webapps/*.war- und auch alle Verzeichnisse mit kieselstein-rest##. löschen
- Dist-Packet über die bestehende Installation entpacken
tar -xvf <pfad-zum-dist-packet>.gz -C /opt/kieselstein
- Client-Scripte anpassen
- Es muss geprüft werden, ob es manuelle Änderungen im Client-Paket für die Startskripte gab und diese eventuell bei den neuen Startscripten nachziehen (Hostname und Splashscreen zum Beispiel).
- Alte Client-Scripte löschen oder klar markieren als OLD (Siehe im Verzeichnis /opt/kieselstein/dist/clients/)
- Berechtigungen wieder für den Kieselstein Ordner setzen
chown -R kieselstein:kieselstein /opt/kieselstein
- Wenn im dist-Verzeichnis mehrere Tomcat oder Wildfly Versionen enthalten sind prüfen welche verwendet wird und die alten löschen
- Prüfen welche Tomcat-Version verwendet wird:
cat /opt/kieselstein/dist/bin/launch-kieselstein-rest-server.sh- Suche nach Zeile: export CATALINA_HOME="${KIESELSTEIN_DIST}/apache-tomcat-x.x.x", diese Tomcat Version wird verwendet die andere(n) müssen gelöscht werden.
- Prüfen welche Wildfly-Version verwendet wird:
cat /opt/kieselstein/dist/bin/launch-kieselstein-main-server.sh- Suche nach Zeile: wildfly_bin_dir=${KIESELSTEIN_DIST}/wildfly-x.x.x.Final/bin, diese Wildfly Version wird verwendet die andere(n) müssen gelöscht werden.
- Achtung Aktuell sind im Wildfly noch die Report-Dateien enthalten so wie eventuelle Anwender-Reports.
- Es müssen, wenn sich die Wildfly Version ändert, vor dem Löschen des alten Wildfly Ordners alle Anwender-Reports in den neuen Wildfly kopiert werden.
- /opt/kieselstein/dist/wildfly-.Final/server/helium/report//anwender
- Prüfen welche Tomcat-Version verwendet wird:
Datenbankmigrationen durchführen
Hinweis: Wenn Kieselstein Version kleiner als 0.0.13 ist:
Muss die initiale Migration gemacht werden.
Das gilt auch für den Start mit den Demodaten.
Installation Liquibase
Für die Datenbankmigrationen, muss das Tool liquibase installiert werden (mit root Rechten).
wget -O- https://repo.liquibase.com/liquibase.asc | gpg --dearmor > liquibase-keyring.gpg && \
cat liquibase-keyring.gpg | sudo tee /usr/share/keyrings/liquibase-keyring.gpg > /dev/null && \
echo 'deb [arch=amd64 signed-by=/usr/share/keyrings/liquibase-keyring.gpg] https://repo.liquibase.com stable main' | sudo tee /etc/apt/sources.list.d/liquibase.list
apt-get update
apt-get install liquibase
Initial-Migrationen setzen
- In das Liquibase Verzeichnis gehen
cd /opt/kieselstein/dist/bootstrap/liquibase- Bestehende Datenstrukturen als bereits migriert markieren
./liquibase.sh changelog-sync --label-filter="0.0.12"
ACHTUNG Wenn die Datenbank von der Default-Installation abweicht müssen in der /opt/kieselstein/dist/bootstrap/liquibase/liquibase.properties Datei die Verbindungseinstellungen angepasst werden:
liquibase.command.url=jdbc:postgresql://localhost:5432/KIESELSTEIN
liquibase.command.username=postgres
liquibase.command.password=postgres
Datenbank Updaten
cd /opt/kieselstein/dist/bootstrap/liquibase
./liquibase.sh update
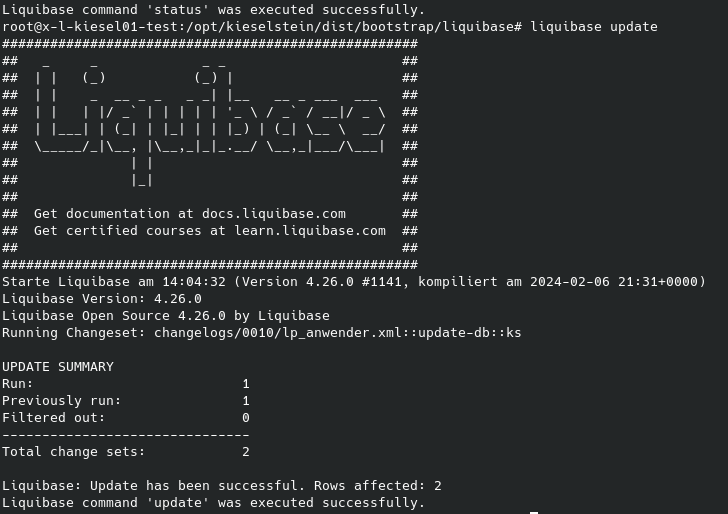
Hinweis
Sollten hier lange Listen von kryptischen Befehlen kommen, funktioniert das Datenbankupdate nicht.Dienste wieder aktivieren
systemctl start kieselstein-main-server.service
systemctl start kieselstein-rest-server.service
Aktualisieren der Clients
Siehe hierfür bitte Installation Clients.
Verlagerung der Anwenderreports
Bis inkl. der Version 0.2.14 wurden die Anwender-Reports innerhalb des Reportverzeichnisses unter anwender abgelegt.(?:\kieselstein\dist\wildfly-12.0.0.Final\server\helium\report..)
Ab der Version 1.0.3 (die dazwischen solltest du nicht verwenden) gibt es die Trennung in Dist und Data. Details siehe bitte
1.8.2 - Update Kieselstein ERP Server unter Windows Server
Update Kieselstein ERP Server unter Windows Server
Für die Kurzfassung siehe
Schritt für Schritt Anleitung
Applikationsserver Updaten
- Dist-Pack auf den Server kopieren
- Dienste beenden
- Beide Kieselstein Dienste (Kieselstein Main Server & Kieselstein REST Server) beenden
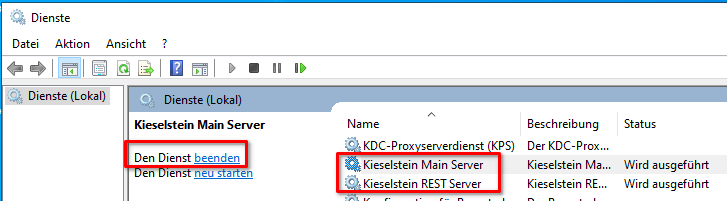
- Alte Programmdateien löschen:
- Im Verzeichnis ?:\kieselstein\dist\wildfly-12.0.0.Final\standalone\deployments
- Alle Dateien mit den Dateiendungen ear, rar und war löschen
- und auch die deployed löschen
- Im Verzeichnis ?:\kieselstein\dist\apache-tomcat-8.5.93\webapps
- Alle Dateien mit den Dateiendung war löschen
- Alle Verzeichnisse mit kieselstein-rest##. löschen
- im Verzeichnis ?:\kieselstein\dist\clients alle gz Dateien löschen
- Im Verzeichnis ?:\kieselstein\dist\wildfly-12.0.0.Final\standalone\deployments
- Dist-Packet über die bestehende Installation entpacken (In der Windows Eingabeaufforderung cmd.exe)
tar -xvf <pfad-zum-dist-packet>.gz -C ?:\kieselstein\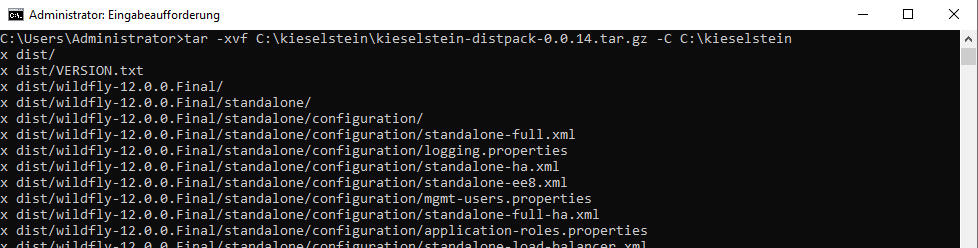
- Client-Scripte anpassen
- Es muss geprüft werden, ob es manuelle Änderungen im Client-Paket für die Startskripte gab und diese eventuell bei den neuen Startscripten nachzeihen (Hostname und Splashscreen zum Beispiel).
- Alte Client-Scripte löschen oder klar markieren als OLD (Siehe im Verzeichnis ?:\kieselstein\dist\clients)
- TODO Scripte Pfade müssen noch angepasst werden.
- Wenn im dist-Verzeichnis mehrere Tomcat oder Wildfly Versionen enthalten sind prüfen welche verwendet wird und die alten löschen
- Prüfen welche Tomcat-Version verwendet wird:
cat ?:\kieselstein\dist\bin\launch-kieselstein-rest-server.sh- Suche nach Zeile: export CATALINA_HOME="${KIESELSTEIN_DIST}/apache-tomcat-x.x.x", diese Tomcat Version wird verwendet die andere(n) müssen gelöscht werden.
- Prüfen welche Wildfly-Version verwendet wird:
cat ?:\kieselstein\dist\bin\launch-kieselstein-main-server.sh- Suche nach Zeile: wildfly_bin_dir=${KIESELSTEIN_DIST}/wildfly-x.x.x.Final/bin, diese Wildfly Version wird verwendet die andere(n) müssen gelöscht werden.
- Achtung Aktuell sind im Wildfly noch die Report-Dateien enthalten so wie eventuelle Anwender-Reports.
- Es müssen wenn sich die Wildfly Version ändert vor dem Löschen des alten Wildfly Ordners alle Anwender-Reports in den neuen Wildfly kopiert werden.
- ?:\kieselstein\dist\wildfly-*.Final\server\helium\report*\anwender
- Prüfen welche Tomcat-Version verwendet wird:
Datenbankmigrationen durchführen
Hinweis: Wenn Kieselstein Version kleiner als 0.0.13 ist:
Muss die initiale Migration gemacht werden.
Das gilt auch für den Start mit den Demodaten.
Installation Liquibase
Für die Datenbankmigrationen, muss das Tool liquibase installiert werden.
Akutelle Liquibase Version vom git Repository runterladen:
https://github.com/liquibase/liquibase/releases
Hier biss zu den Assets runterscrollen und dann den passenden (Windows-)Installer auswählen. Z.B.: liquibase-windows-x64-installer-x.x.x.exe
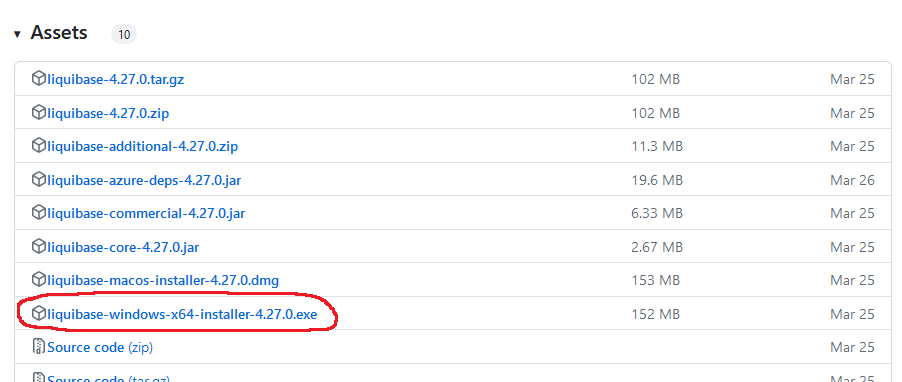
Den Installer am Server ausführen und durchklicken.
Bitte darauf achten, dass Add Liquibase to PATH angehakt bleibt.
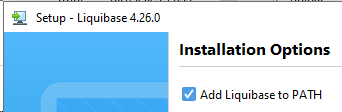
Achtung nach der Installation von Liquibase müssen für die weiteren Arbeiten neue Eingabeaufforderungen (cmd) gestartet werden! Ein Neustart des Servers ist nicht erforderlich.
ACHTUNG
Das Liquibase ergänzt die Pfad-Angabe nur Benutzer spezifisch.Das bedeutet, wenn du danach das Update unter einem anderen Benutzer machst, hast du keinen Zugriff. Unsere Empfehlung. Verschiebe die Pfad-Ergänzung von den Benutzervariablen in die Systemvariablen.
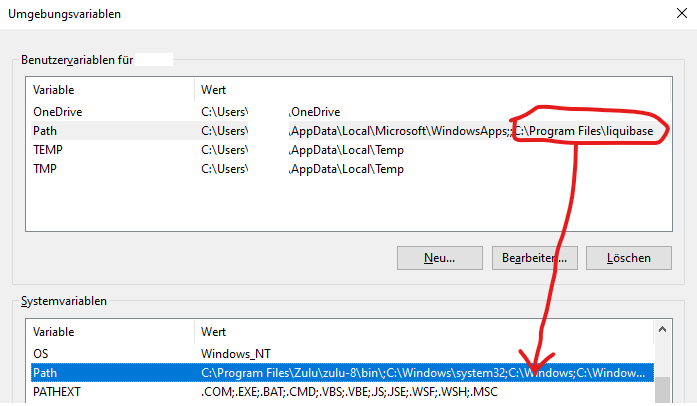
Initial-Migrationen setzen
- In der Windows Eingabeaufforderung cmd.exe
- In das Verzeichnis wechseln
cd ?:\kieselstein\dist\bootstrap\liquibase- Bestehende Datenstrukturen als bereits migriert markieren
liquibase changelog-sync --label-filter="0.0.12"
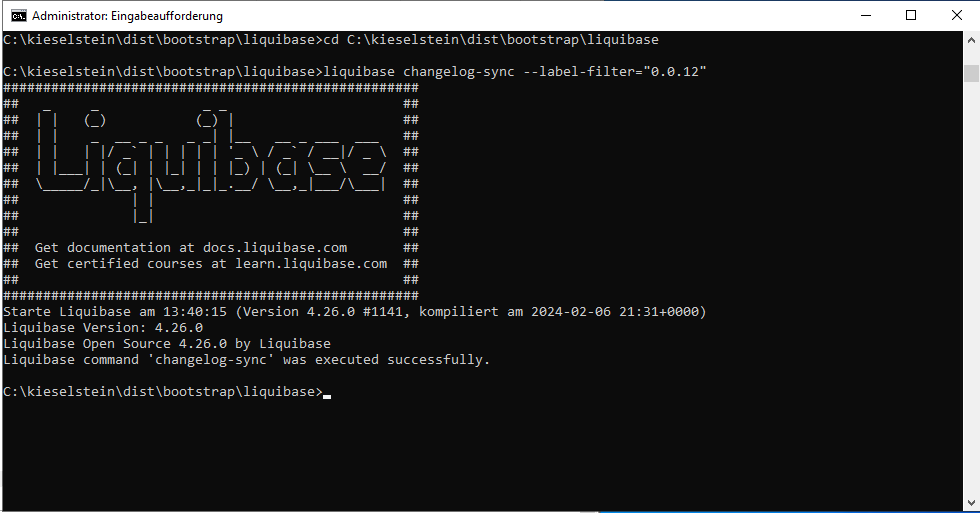
- In das Verzeichnis wechseln
ACHTUNG Wenn die Datenbank von der Default-Installation abweicht müssen in der ?:\kieselstein\dist\bootstrap\liquibase\liquibase.properties Datei die Verbindungseinstellungen angepasst werden:
liquibase.command.url=jdbc:postgresql://localhost:5432/KIESELSTEIN
liquibase.command.username=postgres
liquibase.command.password=postgres
Datenbank Updaten
In der Windows Eingabeaufforderung cmd.exe
cd ?:\kieselstein\dist\bootstrap\liquibase
liquibase update
Hinweis
Sollten hier lange Listen von kryptischen Befehlen kommen, funktioniert das Datenbankupdate nicht.Prüfen ob das Update funktioniert hat
In der Praxis hat sich bewährt, dass man, vor dem Start der Dienste, zumindest den Main-Prozess als “Programm” startet.
Idealerweise wechselst du dazu in das Verzeichnis ?:\kieselstein\dist\bin und startest launch-kieselstein-main-server.bat.
Dieser muss problemlos durchlaufen.
Sollte hier eine Meldung ähnlich nachfolgender kommen:

"(" kann syntaktisch an dieser Stelle nicht verarbeitet werden
so fehlt in deinen Pfaden der Zugriff auf die postgresQL Runtime Programme.
Trage diese in den Pfaddefinitionen ein.
- Problemlos durchlaufen bedeutet, dass der Startschirm angezeigt werden muss. Dieser sieht unter Windows wie folgt aus:
Wenn der Start durchgelaufen ist, was je nach Performance der Maschine auch mal ein paar Minuten dauern kann, so kommt danach die Anzeige des sogenannten Shoptimers

Damit siehst du, dass dein Server läuft. Nun kannst du diesen mit Strg+C stoppen und den Dienst wieder aktivieren.
Nachtragen PostgresQL Runtime Pfad
- Rechtsklick auf das Windows Start-Symbol
- System
- suche nun erweiterte Systemeinstellungen. Je nach Windows-Version ist dies optisch an einem anderen Platz, aber immer unter System Info zu finden
- Umgebungsvariablen anklicken
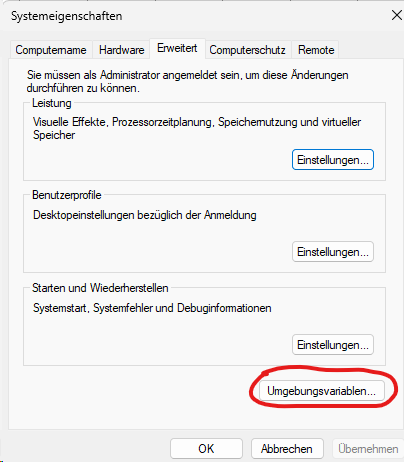
- Suche nun im unteren Bereich (Systemvariablen) die Variable Path
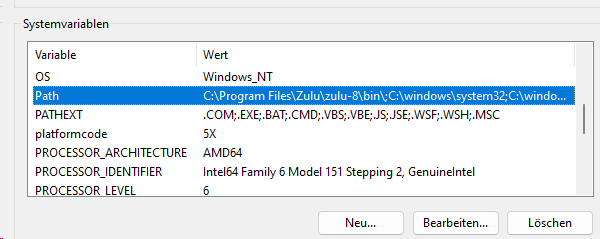 und klicke auf bearbeiten
und klicke auf bearbeiten 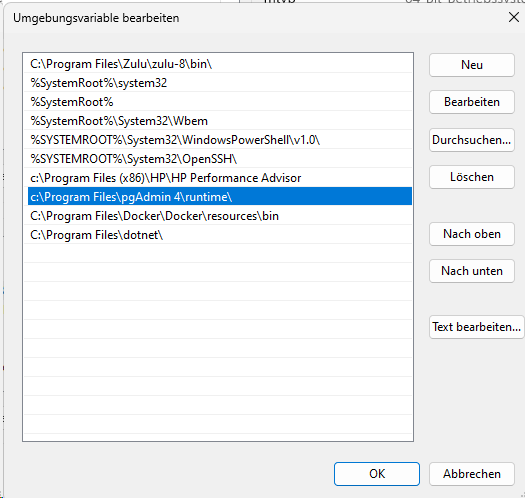 Hier muss nun, abhängig von der verwendeten pgAdmin Version der Pfad auf die pgAdmin runtime eingetragen sein. Bei pgAdmin 4 V7 ist dies “c:\Program Files\pgAdmin 4\v7\runtime”. Bei pgAdmin 4 V8 ist dies “c:\Program Files\pgAdmin 4\runtime”.
Hier muss nun, abhängig von der verwendeten pgAdmin Version der Pfad auf die pgAdmin runtime eingetragen sein. Bei pgAdmin 4 V7 ist dies “c:\Program Files\pgAdmin 4\v7\runtime”. Bei pgAdmin 4 V8 ist dies “c:\Program Files\pgAdmin 4\runtime”.- Wenn alles eingetragen ist, beende zumindest den Umgebungsvariablen und den Systemeigenschaften Dialog.
- starte ein neues CMD-Fenster und gib psql (+ Enter) ein. Es muss die Abfrage des psql nach dem Benutzerpasswort kommen. Kommt eine Meldung mit *Der Befehl “psql” ist entweder falsch ….. *so ist deine Pfad-Definition falsch, womit auch der Serverstart nicht funktionieren wird.
Funktioniert dies, würde ich mit der oben beschriebenen Prüfung fortfahren.
Dienste wieder aktivieren
- Beide Kieselstein Dienste (Kieselstein Main Server & Kieselstein REST Server) starten
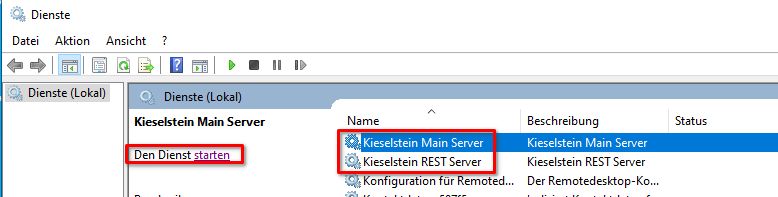
Aktualisieren der Clients
Siehe hierfür bitte Installation Clients.
Verlagerung der Anwenderreports
Bis inkl. der Version 0.2.14 wurden die Anwender-Reports innerhalb des Reportverzeichnisses unter anwender abgelegt.(?:\kieselstein\dist\wildfly-12.0.0.Final\server\helium\report..)
Ab der Version 1.0.3 (die dazwischen solltest du nicht verwenden) gibt es die Trennung in Dist und Data. Details siehe bitte
Probleme / Lösungen
Nachfolgend eine Sammlung von bisher bekannten Problemen und deren Lösungen beim Updateprozess. Vom Grundgedanken her gelten diese Dinge für beide Betriebssysteme, auch wenn die Aufrufe und die erforderlichen Betriebssystemspezifischen Rechte durchaus unterschiedlich sein können.
Liquibase meldet Checksum Konflikt
Während des Liquibase Updates kommen Fehlermeldungen. Wie z.B.:
Starte Liquibase am 08:47:40 (Version 4.28.0 #2272, kompiliert am 2024-05-16 19:00+0000)
Liquibase Version: 4.28.0
Liquibase Open Source 4.28.0 by Liquibase
ERROR: Exception Details
ERROR: Exception Primary Class: ValidationFailedException
ERROR: Exception Primary Reason: Validierung war nicht erfolgreich:
Bei 1 ChangeSets stimmt die Prüfsumme nicht mehr mit der Historientabelle überein.
changelogs/0.1.1/punkt_ist_dezimaltrenner_parameter.xml::add-parameter::KSE was:
> 9:2e4dc472a79dcf110b919b796195b677 but is now: 9:ff143e7c43a38123ddfb731c38d613c9
Siehe dazu 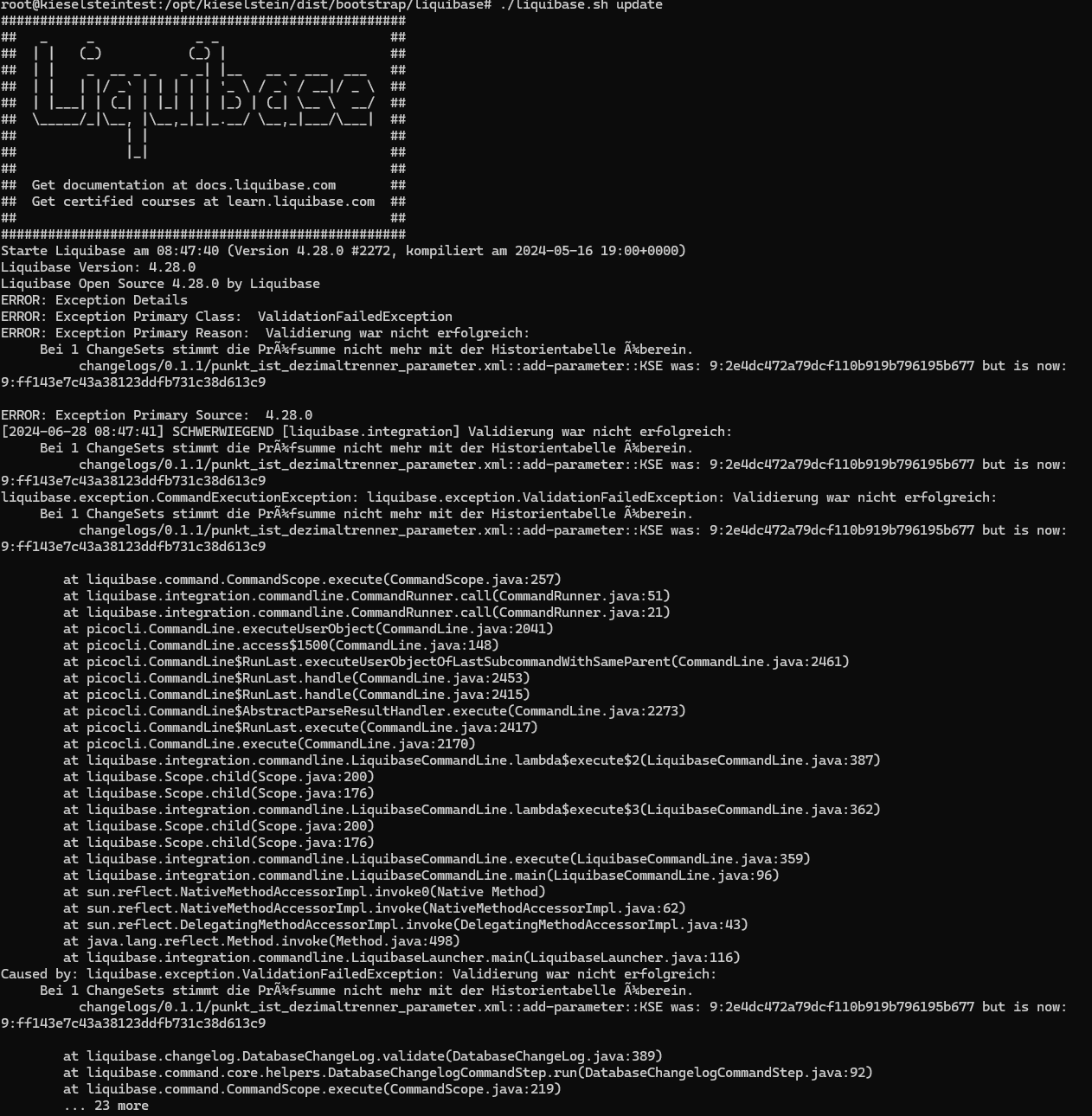
bzw.
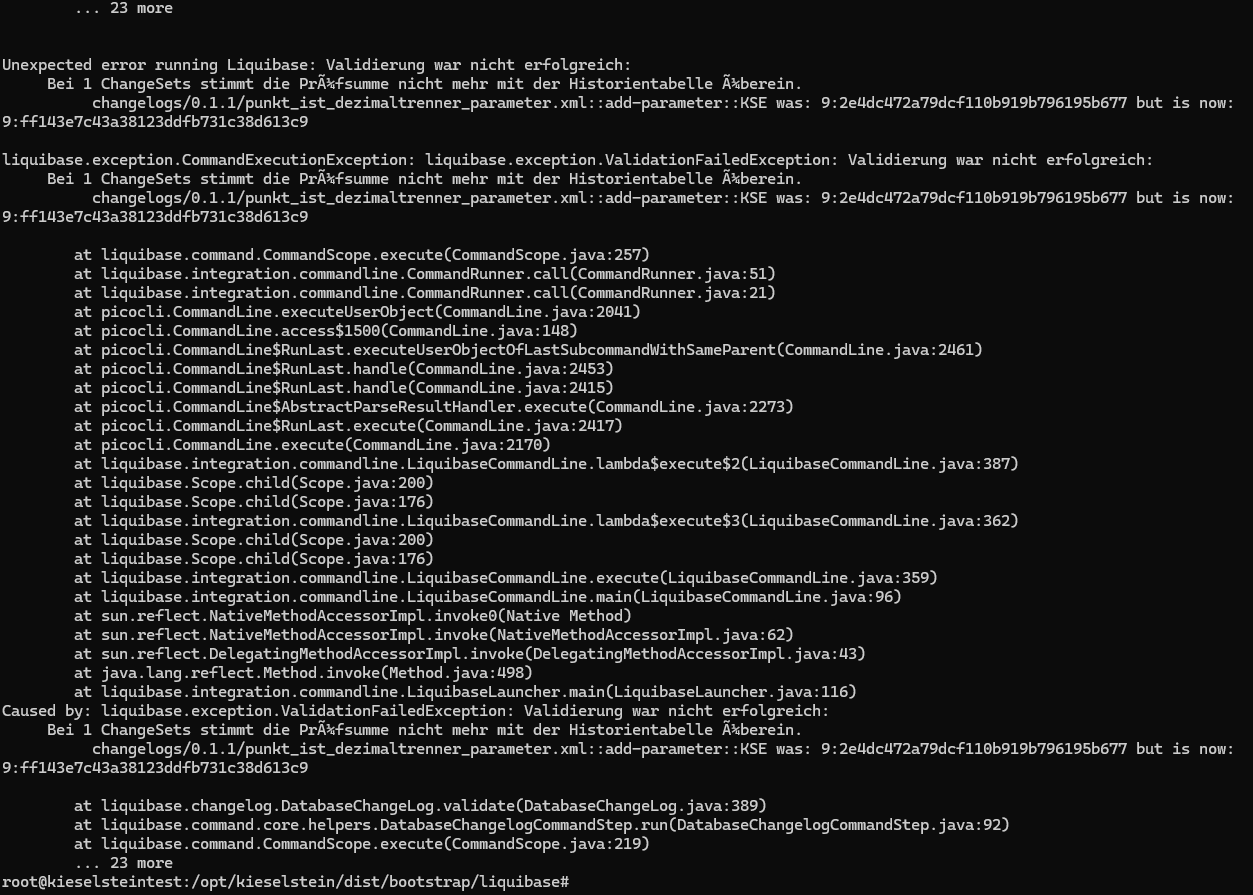
Clear Checksums
run-liquibase.bat clear-checksums (für Linux ./liquibase.sh clear-checksums)
Um eventuell falsche Checksums zu löschen und damit weiter zu kommen.
Aufruf von ?:\kieselstein\dist\bootstrap\liquibase\ aus
Siehe zusätzlich auch –help
Die Checksum in der Tabelle manuell richtig stellen
Ich habe dafür folgendes Script verwendet. Dieses ist sicherlich nicht vollständig und muss gegebenenfalls auf die aktuelle Situation angepasst werden. Die Vorgehensweise sollte damit aber klar sein.
ACHTUNG:
Ob diese Vorgehensweise die Konsistenz deiner Daten bzw. die Konsistenz deiner Datenbank zerstört, kann hier nicht geklärt werden. Achte auf die Inhalte der Liquibase Änderungsscripte. Es gilt dies auch für das Clear Checksums
– korrigieren der checksum der zwischenversion der 0.1.1
update databasechangelog set md5sum = ‘9:ff143e7c43a38123ddfb731c38d613c9’ where md5sum=‘9:2e4dc472a79dcf110b919b796195b677’;
update databasechangelog set md5sum = ‘9:ff143e7c43a38123ddfb731c38d613c9’ where md5sum=‘9:67af6ebc94a79ccc6073d7044b4fe2dc’;
Spalte ist bereits vorhanden
Es kommt beim Update eine Meldung dass die Spalte xy bereits in der Datenbank eingetragen ist.
 Wenn man sich sicher ist, dass in der Tabellen Spalte KEINE Einträge sind, kann man diese einfach löschen und danach das Update erneut ausführen.
Wenn man sich sicher ist, dass in der Tabellen Spalte KEINE Einträge sind, kann man diese einfach löschen und danach das Update erneut ausführen.
Ist dem nicht so, so kann man das betreffende XML entsprechend auskommentieren. Die Update-XMLs, welche Versionsweise organisiert sind, findest du unter
?:\kieselstein\dist\bootstrap\liquibase\changelogs\Versionsnummern
Hier das betreffende XML heraussuchen und z.B. die Extension mit .nix ergänzen. Danach das Update erneut ausführen.
Passend zu obiger Fehlermeldung:
?:\kieselstein\dist\bootstrap\liquibase\changelogs\0.0.14\los_material_vollstaendig_parameter.xml
Kurzfassung des Updatevorgangs
Wenn auf deinem Kieselstein bereits die Liquibase Version installiert ist, also ab 0.1.0 so hat sich folgende Vorgehensweise bewährt:
- herunterladen des aktuellen Releases
- stoppen der Dienste kieselstein-rest-server, kieselstein-main-server
- kopieren des ..\kieselstein\dist Verzeichnises auf die bisherige Versionsnummer (siehe d:\kieselstein\dist\VERSION.txt)
- Ausführen des loeschen.bat
- kopieren des im kieselstein-distpack-0.2.4.tar.gz enthaltenen dist auf das (bereinigte) dist Verzeichnis. Überschreiben aller vorhandenen Dateien.
ACHTUNG: Es werden damit (Stand Juni 2024) alle ev. speziell angepassten fremdsprachigen Reports durch den Standard überschrieben. Änderung ist geplant. - Update der Datenbank durch inital.bat
- Anpassen der Clientdateien
- üblicherweise gibt es im d:\kieselstein\dist\ ein client.zip mit den aktuellen Daten für die Clients.
- das lib löschen
- aus ?:\kieselstein\dist\clients\kieselstein-ui-swing-0.2.4.tar.gz das lib in obiges client.zip einkopieren
- im bin das kieselstein-ui-swing.bat die Zeile mit set CLASSPATH=%APP_HOME%\lib\kieselstein-ui-swing-0.2.4.jar; …….. in dein speziell auf deine Installation angepasstes kieselstein-ui-swing.bat übernehmen.
- Dienste starten und gegebenenfalls unter d:\kieselstein\dist\wildfly-12.0.0.Final\standalone\deployments prüfen, dass der Wildfly tatsächlich startet.
Gegebenenfalls auch den Start des RestAPI Servers (Tomcat) durch Aufruf der RestAPI Dokumentation prüfen. - Nun den Client am Server starten -> sollte gehen
- Infos an die Anwender, dass neuer Client zu installieren ist.
1.9 - Anforderungen Kieselstein ERP Server
Anforderungen an den Kieselstein ERP Server
Die Anforderungen an den Kieselstein ERP Server sind von verschiedenen Eckpunkten abhängig. Im wesentlichen sind dies Benutzeranzahl und Betriebssystem.
Server
Windows
Die Verwendung eines 64Bit Betriebssystems ist heutzutage selbstverständlich.
Bei Verwendung von Windows gehen wir davon aus, dass dieses, auch für den Testbetrieb, ordnungsgemäß lizenziert ist.
| Eigenschaft | Betriebssystem | Datenbank | Kieselstein appServer |
je Power User | je std. User |
|---|---|---|---|---|---|
| Kerne | 1 | 1 | 1 | 0,5 | 0,1 |
| Ram [GB] | 4 | 2 | 2 | 0,1 | 0,01 |
| Platte [GB] | 100 | 70 | 70 |
Ganz wesentlich in die Geschwindigkeit des Gesamtsystems geht die Zugriffsgeschwindigkeit der / auf die Festplatten ein. Wir raten, auch wenn es teuer ist, zu SSD Platten. Sollte dies nicht möglich sein, zu Raid10.
ACHTUNG: Bei Virtualisierung kommt es immer wieder vor, dass die Platten zwar sehr schnell sind, aber da alle virtuellen Maschinen auf die gleiche Hardware zugreifen, ist im Endeffekt der Festplattencontroller der Flaschenhals. Hier ist zusätzlich zu bedenken, dass die Zugriffe oft mit kleinen Datenmengen erfolgen. D.h. die in der IT üblichen Geschwindigkeitsmessungen haben keine Aussagekraft (die Optimierungsalgorithmen der VM’s greifen leider nicht).
Die Größe der Platten hängt auch an der Verwendung der Dokumentenablage. Kann also, bei intensiver Nutzung, was im Sinne des Systems ist, auch deutlich darüber hinaus anwachsen.
In dieser Betrachtung ist der, für das unumgängliche zumindest tägliche Backup benötigte Platz, nicht berücksichtigt. Auch dies hängt von der Datenmenge der Installation ab. So beginnen Neuinstallationen bei einigen wenigen GB und wachsen danach schon mal auf 150GB oder mehr an.
Eine wesentliche Frage in diesem Zusammenhang ist das Thema des Backups bzw., wie alt dürfen die Daten bei einem eventuellen Ausfall sein. Das geht bis hin zu gespiegelten Datenbankservern.
Diese Dinge klären wir am Besten in einem persönlichen Gespräch.
ACHTUNG: Es muss am Server IMMER der doppelte Speicherplatz wie dein Datenbankbackup belegt frei sein.
Welche Windows Betriebssysteme können genutzt werden?
Auch das hängt vom Einsatzbereich ab.
Für eine anfänglich kleine Installation mit 2Usern reicht auch mal ein Windows11 (Windows 10 wird nicht mehr lange zur Verfügung stehen). Für den Einsatz in einem Unternehmen mit 5 Usern oder mehr, raten wir zum Einsatz eines Server Betriebssystems. Da der ganze grafische Overhead auf dem Server nicht benötigt wird, gerne auch Linux, Debian.
In jedem Falle aber bitte ausschließlich 64Bit-Systeme.
Benötigte Werkzeuge für den Server
Postgre-SQL Datenbank
Es werden die Version 14 oder 15 der PostgreSQL Datenbank unterstützt. Siehe Downloads unter: https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
Liquibase Migrationstool
Für die Datenbankmigrationen wird das Liquibase Tool benötigt. Die Aktuelle Liquibase Version kann vom git Repository heruntergeladen: https://github.com/liquibase/liquibase/releases werden. Hier biss zu den Assets runterscrollen und dann den passenden (Bsp.: Windows-)Installer auswählen. Z.B.: liquibase-windows-x64-installer-x.x.x.exe
Java-Version
ACHTUNG Java Version 11 ist erst ab der Kieselstein-Version 1.0.0 und höher unterstützt vorher bitte Java-Version 8 verwenden!
Es wird für den Server die Azul-Java Version 11 benötigt.
Siehe dazu www.azul.com, klick auf Downloads 
runterscrollen und Java11 LTS, (das jeweilige Betriebssystem auswählen), x86 64.bit, JDK FX auswählen.
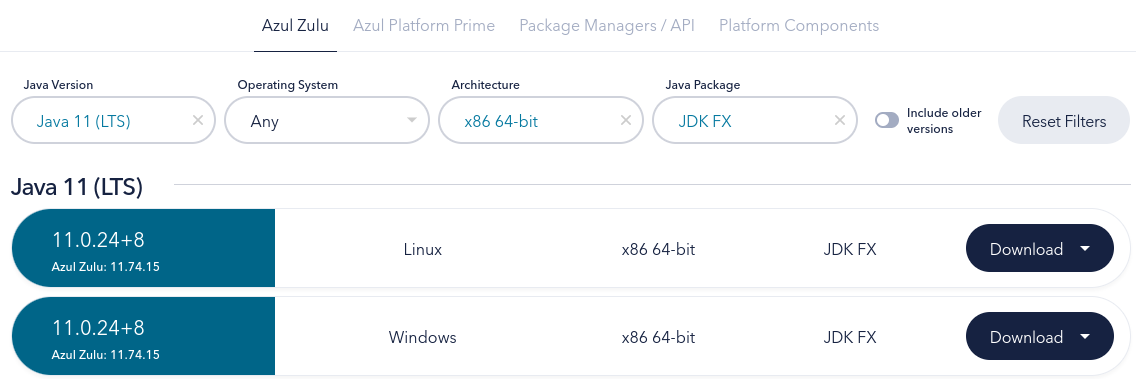
Nginx Webserver
Wenn die REST-Schnittstelle oder andere Dienste über das Internet zur Verfügung stehen sollen, dann sollte dies über einen Nginx-Webserver werden. Es wird für die Installation eine Default-Konfiguration (unter Kieselstein/dist/bootstrap/) mit ausgeliefert wo der Port 8280 ohne SSL vorkonfiguriert ist (wie es bei früheren Versionen mit dem Tomcat durchgeführt wurde).
Unter nginxtutorials.com ist auch beschrieben wie ein Lets Encrypt-SSL-Zertifikat erstellt werden kann mit Nginx.
Alternativ kann natürlich auch ein Selbstsigniertes Zertifikat für SSL mit Nginx verwendet werden.
weitere Last am Server
Es gibt inzwischen noch eine Anzahl von Funktionen / Zugriffen auf den Server, die für jeden Zugriff mehr oder weniger Serverlast ziehen. Auch diese sind in den obigen Überlegungen zu berücksichtigen.
- RestAPI, je nach Intensität der Nutzung
- ZE-Terminals je nach Buchungshäufigkeit. Es ist ein entsprechender Unterschied ob nur Kommt/Geht (Anwesenheitszeit) gebucht wird, oder die papierlose Fertigung mit Zeichnungen, Auswahllisten usw. verwendet wird. Insbesondere die Zeitverteilungsberechnungen können entsprechende Serverlast erzeugen.
- Anwesenheitsliste(n) Auch hier macht es einen großen Unterschied, ob 10 Terminals im 30Sekunden Takt jeweils eine neue Liste anfordern, oder ob diese ober den Anwesenheitslisten Proxy eigenständig aufbereitet werden.
- die Listenauswertungen per Web-Pages. Auch diese Auswertungen brauchen entsprechende CPU Leistung
Client
Hier reichen heutzutage (2023) übliche Standard PC’s, mit mindestens 64Bit Betriebssystemen und 8GB Ram (wenn nur der Kieselstein-ERP Client läuft). Empfohlen 16GB Ram, gerne mehr.
Auch hier raten wir zur Verwendung von SSD Platten, da auch diese massiv in das Geschwindigkeitsverhalten eingehen.
1.10 - Datensicherung
Einige Gedanken zur Datensicherung
Da wir in der Praxis immer erleben, dass die Datensicherung zwar angeblich gemacht wird, aber dann doch nicht funktioniert, hier einige Gedanken dazu.
Wozu überhaupt Datensicherung?
Wie hoffentlich allgemein bekannt ist, ist gerade die IT nicht vor Fehlern gefeit. D.h. deine Daten und diese sind heutzutage das Herzstück deines Unternehmens, müssen in jedem Falle “jederzeit” zur Verfügung stehen.
Solltest du anderer Meinung sein, schalte PC und Handy aus, was geht dann für dich noch?
Wo aufbewahren?
Die Datensicherung muss mechanisch vom Rest der IT getrennt sein.
D.h. die Bänder, Kassetten dürfen nach der durchgeführten Datensicherung auch elektrisch nicht mehr mit dem Rest der IT verbunden sein. So werfen RDX Laufwerke bzw. Streamer am Ende des positiv abgeschlossenen Sicherungsvorganges die Kassette aus.
Üblicherweise ist das so organisiert, dass eine Bürokraft sich um die tägliche Sicherung kümmert und wenn das Medium nicht ausgeworfen wurde, die Verpflichtung hat die zuständige Stelle zu informieren.
Dass zumindest die Monatssicherung außer Haus gebracht wird, ist selbstverständlich. Wenn du Tagessicherungen machst, was für eine Produktionsunternehmen eher die Regel ist, so gilt dies für die Wochensicherungen. Das außer Haus bringen kann ein Bank-Safe sein, oder deine weit genug entfernte Privat-Wohnung. Der Gedanke hier ist immer, wenn jemand / etwas, beide Daten(stämme) zugleich stiehlt, angreift, also z.B. den Server klaut und deine Kassetten aus dem Privathaus, so hast du sowieso ein anderes Problem.
Wieviele Medien brauche ich?
Um diese Frage zu beantworten, muss man sich überlegen, wie oft ich eigentlich sichern muss.
Der Schlüssel dafür ist für mich:
- wenn zur letzten Sekunde des gerade durchgeführten Backups, welches noch nicht vollständig ist, das System ausfällt, so sind meine (gesamten) Daten weg.
- kann ich diese wiederherstellen?
- wie lange dauert die Nacherfassung?
D.h. wenn ich die Daten wiederherstellen kann und ich diese innerhalb einer Wochenendaktion nacherfassen kann, so ist der Zeitraum für den ich das mache der Zeitraum für den ich meine Sicherung machen muss. Ich würde jedoch immer für jede Woche eine Sicherung machen (man vergisst zu viel). Die Frage ist eher, ob eine Tagessicherung ausreicht, oder ob es stündliche Sicherungen von Teilen sein müssen, oder ob es gespiegelte Server braucht, welche in der Regel nur eine Datenbanktransaktion hinten sind.
Man sollte das auch nicht übertreiben. Wenn ich in fünf Jahren, die Zeitdaten eines Tages von meinen 150Mitarbeiter:innen nicht exakt habe, wird mich das nicht umbringen.
Das ist doch alles so teuer?
Ja das stimmt. So kostet aktuell eine 1TB RDX Kassette ca. 180,- €. Davon brauche ich, bei wöchentlicher Sicherung und Monatsbackup 4 + 12 Stk -> 2.880,- €.
Setzt man nun für die Nacherfassung einen Stundensatz von 80,- € (Inkl. aller Nebenkosten) an, so sind das 36Std, also 4Menschtage!
Dazu kommt: Ein IT-Systemausfall ist komplett versicherbar, die Datenwiederherstellung aus einem guten Backup ist darin enthalten, aber das Herzaubern von Daten ist nicht versicherbar.
Wie lange kann ich mir einen Systemausfall leisten?
Heutzutage ist alles in der IT gespeichert. Also z.B. auch die Telefonnummern in der Telefonanlage, welche ja auch ein IT System ist. Fällt nun die IT aus, woher weißt du die Telefonnummern der Kunden die du anrufen solltest?
Es gibt schon sehr lange Statistiken, die besagen eine dreitägige Nicht-Verfügbarkeit des IT-Systems haben einen Großteil der Unternehmen nicht überstanden.
Desaster Recovery Time
Zu obigem Thema kommt auch dazu, wie lange brauche ich um überhaupt die Daten wiederherstellen zu können. Es ist ja wunderbar wenn alles, in der Regel in Images gesichert ist. Braucht man nun eine einzelne Datei daraus, so muss man, je nach Backupsystem, das gesamte Image zurücksichern (wo findet man schnell mal 500GB freien Platz) um dann die eine Datei mit 2GB daraus extrahieren zu können. Oder eben auch, das Image ist gesichert, muss aber über die Internetleitung übertragen werden. Diese ist im Moment aber gut ausgelastet bzw. die Übertragung von großen Datenmengen ist noch immer problematisch, muss über eine geeignete Software gemacht werden.
Bedenke dies alles mit, auch wie kommt man zu den verschiedensten Passwörtern usw. Wer hat die Daten, wo sind sie? Der/diejenige ist gerade in Urlaub, im Krankenhaus. Woher weiß ich überhaupt von wann (Zeitpunkt) das Backup ist, das ich einspielen möchte.
Wir raten mach dir einen definitiven Plan, wie im Falle des Falles vorzugehen ist. Das beginnt bei der Beschaffung eines neuen Servers (im nächsten Computershop) und endet bei den Zeiten die für die verschiedensten Restores benötigt werden. Schreib diese Tabelle mal zusammen und lass diesen schlimmen Fall dann am 24.12. um 16:30 auftreten. Wie sieht der Zeitablauf aus. Wenn du dann auch noch einen Datenverlust hast, denk an die dann sehr kurzen Fristen der DSGVO. Ich wünsche uns allen, dass wir das nie brauchen.
Reicht es wenn ich Veränderungen sichere?
Diese Frage kommt immer bei entsprechend großen Datenmengen, also wenn die Nacht für die Sicherung zu kurz wird.
Unsere Erfahrung. Nur Veränderungssicherungen sind extrem gefährlich. Denn im Falle der Rücksicherung braucht nur ein Medium in der Kette defekt zu sein und das Restore ist nicht mehr möglich. Daher muss in den Sicherungskonzepten immer ein aktuelles und vollständiges Backup auf dem Sicherungsmedium gespeichert sein.
Wie oft muss ich die Sicherung prüfen?
Reicht wenn ich schaue dass die Files erzeugt werden?
Bitte achte bei der Erzeugung der Backupdateien darauf, dass das Ende des Backups rechtzeitig vor dem Weiterkopieren auf das Sicherungsmedium abgeschlossen ist. Du solltest das monatlich überprüfen.
muss ich das Restore prüfen
Bitte nimm dir die Zeit, auch den Restore der Daten regelmäßig zu prüfen. Regelmäßig bedeutet in diesem Falle, zumindest jedes halbe Jahr, besser öfter. D.h. wirklich in das Testsystem die Backupdaten reinspielen. Es müssen die Daten des letzten Tages, also des Tages der Datensicherung im Zugriff stehen.
Es kommt leider zu oft vor, dass nur Filezuwachs und Datum geprüft werden, aber in der langen Kette irgend etwas nicht stimmt und du im Falle des Falles, dann doch keine Daten hast.
ich mache das alles Online
ACHTUNG: Im Falle eines Verschlüsselungstrojaners ist die Gefahr, dass durch einen Fehler / Irrtum in der Konfiguration, der Trojaner auch dein Backup verschlüsselt, extrem hoch. Nur sehr sehr versierte IT-Betreuer sind in der Lage dies richtig aufzusetzen.
Daher unser Rat, immer mechanisch getrennt aufbewahren. Und auch außer Haus. Denkt an Hochwasser, Blitzschlag, generelle Überspannung, Feuer, Diebstahl.
Ich habe persönlich noch keinen IT-Betreuer kennengelernt der das wirklich beherrscht. Daher rate ich lieber ein paar Euro mehr für die Sicherheit auszugeben.
Für umfassende Desaster Recovery Szenarien, wendet euch gerne an uns.
Zum Thema Angriffe siehe auch: Real-Time DDoS Attack Map | NETSCOUT Omnis Threat Horizon, https://horizon.netscout.com/
1.11 - IT-Betreuung
Was sind die Aufgaben deines IT-Betreuers
Nachfolgend eine lose Aufstellung der Aufgaben deines IT-Betreuers für den Betrieb deines Kieselstein ERP-Systems, welche nicht vollständig ist.
Es sollte dies dazu dienen, den Umfang einer verantwortungsvollen IT-Betreuung zu skizzieren. Ergänzungen dazu sind willkommen.
Bitte beachte auch, dass dein Kieselstein ERP zwar die IT massiv nutzt. Die Betreuung deiner IT ist aber in keinster Weise die Aufgabe der Genossenschaft bzw. der Techniker:innen der Consultants, auch wenn das andere Firmen anders handhaben mögen. Siehe dazu auch Update
Welche Aufgaben sollte die IT-Betreuung nun übernehmen:
- Zur Verfügungstellung eines geeigneten ERP-Servers
- Prüfung der Performance des Servers, zur Verfügungstellung einer ausreichenden Performance
- Einrichten der Updates sowohl Clients als auch Server
- Netzwerk-Zugriffssicherheit
- Datensicherung inkl. Überprüfung
- WLan Access
- Planung von Erweiterungen (lieber ein geplanter Stillstand als ungeplantes Chaos)
- ist bei Problemen innerhalb von xx Std verfügbar, zumindest an Arbeitstagen und an normalen Wochenenden und ….
- weiß auch, wie man ein Kieselstein ERP installiert und die Datenbanken wieder herstellt.
Anmerkung:
Wenn du diese Betreuung selbst übernimmst, gehen wir davon aus, dass eine entsprechende Qualifikation gegeben ist. Du also auch die Verantwortung dafür übernimmst / übernehmen kannst.
Von der Verfügbarkeit des Backups (zu jeder Zeit) bis zu Updates usw..
Für die Einrichtung der Zugangsdaten des (externen) Betreuers siehe
1.12 - File orientierte Dokumente Datenbank
Wo werden meine Dokumente gespeichert
Dein Kieselstein ERP hat grundsätzlich zwei Datenbanken.
- Die reinen ERP-Daten, klein, schlank, schnell. Hier sind die ganzen “Zahlen” gespeichert.
- Die Dokumente-Datenbank. Hier sind die Dokumente abgelegt.
Diese gibt es wiederum in zwei Ausführungen.- Default als Datenbank-Tabelle. D.h. die “Bilder” der Dokumente (Ausgangsrechnungen, Eingangsrechnungen, Spezifikationen) werden als sogenannter BLOB direkt in der Dokumentendatenbank gespeichert. Das bewirkt wiederum, dass im Laufe der Jahre diese Datenbank immer größer wird, einige zig GByte sind normal, und so das tägliche Backup dieser Daten immer länger dauert. Je nach Installation kann es auch dazu kommen, dass die Nacht (12Std) zu kurz wird und somit kein konsistentes Backup mehr gegeben ist.
- Daher gibt es als Alternative die sogenannte File orientierte Dokumentendatenbank.
Idealerweise wird diese bereits bei der Installation deines Kieselstein ERP eingerichtet. Es müssen dafür nur zwei Konfigurationsdateien im Kieselstein-ERP Wildfly configuration ausgetauscht / angepasst werden. Du benötigst dafür die angepasste: - kieselstein.xml
- kieselstein_jackrabbit.xml
Hier wird der eigentliche Pfad auf die binären Daten unter <DataStore ….. festgelegt.
Der Vorteil ist, dass die eigentliche Dokumente nur immer neue Daten sind und somit, z.B. mit rsync, nur eine Veränderungs (Erweiterungs) Sicherung gemacht werden muss und damit die dafür benötigte Zeit wesentlich kürzer ist. Es muss allerdings diese zusätzliche Sicherung auch eingerichtet werden.
Ein Wort zur Veränderbarkeit in den Dokumenten-Daten
Da diese Frage immer wieder kommt, also kann ein Super Spezialist die Daten der Dokumente verändern? Hierzu muss man folgendes wissen:
- die Dokumente werden als BLOB Binary Large OBject abgelegt. Dies ist nichts anderes als eine Verkettung von Dateiblöcken in denen die eigentlichen Daten hintereinander eingereiht sind. D.h. das herausfinden einer einzelnen Datei, ist schon ziemlich aufwändig und man muss schon sehr genau wissen was man sucht.
- Nun werden z.B. die Ausgangsrechnungen als Jasper-Objecte (in Dateiform) abgelegt.
- werden nun Daten eingefügt (aus 100 wird 1.000) oder Daten verändert, aus einer 0 wird eine 1 so stimmt die Filegröße nicht mehr und oder die Checksumme stimmt nicht mehr. Damit ist die gesamte Dokumentendatenbank unbrauchbar.
Ob man dies nun, mit einer entsprechend kriminellen Energie auch richtig stellen könnte, ist mir nicht bekannt. Hier kommt mit dazu, dass die Person die dieses macht, physikalisch auf deinen Kieselstein ERP Server Zugriff haben muss (root). Wenn das alles gelingt, hast du ein anderes Problem.
Daher betrachten wir diese Daten als unveränderbar.
2 - Installation Client
Installationsbeschreibung für die Ausrollung des Kieselstein ERP Clients
Voraussetzung: Du hast auf den jeweiligen Rechnern ausreichende Installationsrechte und bist mit den Arbeiten mit Programm-Files und allem was so dazu gehört vertraut. Für Unterstützung wende dich als Mitglied der Kieselstein-ERP eG gerne an eine:n der Consulter:innen
Ab der Version 0.0.0.8 deines Kieselstein ERP können die erforderlichen Installationsdateien über einen Weblink geladen werden. Gehe dazu in einem Browser auf http://IPADRESSE_KIESELSTEIN_ERP:8080.
für Clients ab der Versionsverwaltung (>0.0.14) siehe
Klicke nun auf download clients 
Hier findest du nun die vom Installationsverantwortlichen zusammengestellten Dateien zum Download zur Auswahl.
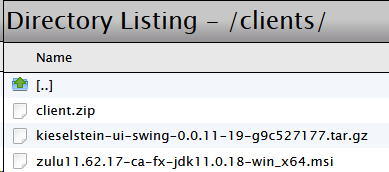
Es sind dies alle Dateien die in deinem Kieselstein-ERP im Verzeichnis
?:\kieselstein\dist\clients abgelegt sind.
Es ist Aufgabe des/der installierenden hier alle richtigen Dateien zusammenzustellen. Das bedeutet aktuell auch, dass nach jedem Update die Dateien anzupassen sind.
Das Kieselstein-Desktop-Icon findest du hier
In der Client.zip sind die beiden Verzeichnisse für die Installation enthalten. Lade diese herunter und kopiere diese z.B. auf c:\kieselstein\client.
Im bin Verzeichnis findest du drei Dateien:
In Windowssystemen richte dir eine Desktop-Verknüpfung auf die kieselstein-ui-swing.bat ein. Dieser gibst du das Icon Kieselstein.ico.
In Linux bzw. MAC-OS verwendest du die kieselstein-ui-swing.
Nun benötigst du noch das passende Java (wenn nicht schon installiert), welches ebenfalls im Browser als Download zur Verfügung steht (zulu ….).
Java mehrfach vorhanden?
Wichtig: Sollte Java auf dem Client bereits für andere Programme benötigt werden, ist die weitere Vorgehensweise zu klären. Ersetzen oder parallel.Üblicherweise kann ein / alle eventuell vorhandenes(n) Java entfernt werden. -> EMPFOHLEN
Installiere nun das Azul Java mit den default Einstellungen. Einzig bei der Frage nach dem Java Home wähle  immer Verfügbar. Details siehe
immer Verfügbar. Details siehe
Nun kannst du deinen Kieselstein ERP Client starten.
Benutzername und Passwort erhältst du von deinem/r Kieselstein ERP in Haus Verantwortlichen.
Hinweis:
Sollte nach eine Neuinstallation von Java, das java trotzdem nicht zur Verfügung stehen (prüfen z.B. aufmachen des CMD (Command-Shell) und Java -version), so hilft unter Umständen, gerade bei komplexen Berechtigungen, ein Neustart des Rechners.
Hinweis:
Es hat sich bewährt, auf den Rechnern der Poweruser auch einen Teamviewer (https://www.teamviewer.com/de/download/windows/) installiert zu haben. Wir gehen davon aus, dass jeder ERP Anwender den Teamviewer starten kann und darf.
Von Kieselstein ERP verwendete Ports siehe bitte Server
Hinweis
Für Verbindungen von extern raten wir dringend gesicherte Verbindungen (VPN = Virtual Private Network) zu verwenden.Java
Wir setzen zur Zeit folgende Versionen voraus:
Gerade im Clientbereich kann es vorkommen, dass andere Versionen eingesetzt werden. Bitte beachte, dass wir für das richtige Verhalten der Software ausschließlich die unten von uns zur Verfügung gestellte OpenJDK8 verwendet werden sollte. Bitte beachte bei der Verwendung von original Oracle Java 8/11 Versionen, dass diese Lizenzkostenpflichtig sind.
Der Basis-Link für das erprobte Zulu Java findest du unter https://www.azul.com/downloads/?package=jdk#zulu Hier dann Java 11 mit jdk-FX auswählen.
Den Download einer freien OpenJDK Version mit Java 11 für deinen Client finden man unter:
https://www.azul.com/downloads/?version=java-11-lts&os=windows&package=jdk-fx
Achte bei der Installation des Javas darauf dass:
- keine weiteren Java Versionen installiert sind. ACHTUNG: solltest du für andere Programme bestimmte Java Versionen benötigen, lässt sich auch das einrichten. Bitte wende dich an deinen Kieselstein ERP Betreuer
- bei der Installation muss das Java Home gesetzt werden, also:
Alternativ kann seit der Kieselstein Version 1.0.0 der Client auch mit einer OpenJDK Version 11 starten. Hinweis: bei einem Mac mit Apple Silicon Prozess wird die Java-Zulu FX Version vorausgesetzt.
Client startet nicht
Wenn unter Windows der Client nur kurz durchläuft und sich dann wieder automatisch beendet, so ist der Pfad in dem deine eigentlichen Clientdateien stecken zu lange. Mache diese kürzer.
Wir raten dies unter ?:\Kieselstein\Client einzurichten
Fehler beim Drucken von Barcodes
Es werden viele Fehler in der Client-Console angezeigt.
Die Barcode sind zerstückelt.
Beim Drucken von Artikeletiketten erscheint das Vorschau-Fenster nicht. Fährt man mit der Maus über den Client erscheinen teilweise die “Bilder” des Druck-Vorschau-Fensters.

Bitte prüfe, ob das aktuelle Java installiert ist.
Es muss 
angezeigt werden. Wird ein älteres Java angezeigt, kann es zu den beschriebenen Effekten kommen. Wichtig eben auch, nur Java mit der FX Erweiterung.
Sollte die Anzeige trotzdem so “spinnen”, dann ist dies ein Problem der Grafikkarte bzw. des Treibers.
Das kann auch auftreten, wenn der Rechner ohne Bildschirm installiert ist und man nur per Fernwartung (Teamviewer, Remote Desktop, …) zugreift.
Fehlermeldung beim ersten Ausführen
Starten man unter Windows den Batch zum ersten Mal kommt
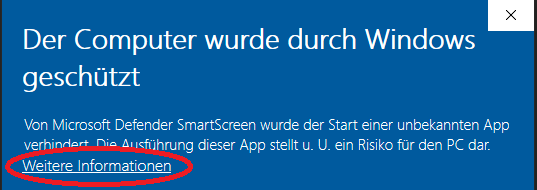
So auf Weitere Informationen klicken und dann
Auf den Trotzdem ausführen Button klicken.
Dies bleibt bis zum nächsten Update / Erneuerung des Batch erhalten.
Client in Start / Taskleiste bringen
Hat man, wie oben beschrieben den Client.bat (eigentlich die ?:\kieselstein\dist\client\bin\kieselstein-ui-swing.bat ) als Verknüpfung auf den Desktop gelegt, so wünscht man sich oft, diese auch in den Start bzw. die Taskleiste zu bringen.
Der Trick dafür geht wie folgt:
- In den Eigenschaften der Verknüpfung vorne das Ziel um C:\Windows\System32\cmd.exe /c ergänzen.

- Nun Rechtsklick auf die Verknüpfung.
- Im Windows 10 sieht man nun
An Start anheften bzw. an Taskleiste anheften, womit man das Start-Icon in den gewünschten Bereich bringen kann. Es sollte die Verknüpfung auf das Desktop-Icon vor dem Verschieben gemacht werden. - Im Windows 11 wählt man vorher noch
 Weitere Optionen anzeigen und kann damit dann An Start anheften bzw. an Taskleiste anheften auswählen.
Weitere Optionen anzeigen und kann damit dann An Start anheften bzw. an Taskleiste anheften auswählen.
- Im Windows 10 sieht man nun
Wird auch Windows 7 unterstützt?
Da Windows 7 schon seit etlichen Jahren nicht mehr supported wird und alleine schon aus diesem Titel dies eine grobe Verletzung der DSGVO darstellt, wird Windows 7 nicht unterstützt. Bitte verwende aktuelle Betriebssysteme, gegebenenfalls auch in einer VM (Virtual Machine) z.B. mit Virtual Box.
Geschwindigkeit, langsamer Client
Neben der reinen Netzwerk-Zugriffs-Geschwindigkeit (siehe Hauptmenüleiste, Hilfe, Info) ist unter Umständen auch der Back-Call des Servers an den Client für die Geschwindigkeit, meist auch für die Langsamkeit verantwortlich.
D.h. es müssen sowohl der Server vom Client aus, als auch der Client vom Server aus, mit ihren Netzwerk-Namen als auch mit den IP Adressen problemlos und schnell erreicht werden können. Ist dem nicht so, dauert das Blättern zwischen den Modulreitern entsprechend lange.
Gerade in Linux-Systemen oder bei VPN Verbindungen werden hier gerne Konfigurationsfehler gemacht.
In anderen Worten, es muss der DNS Name immer auf einen internen DNS Server zeigen, dann ist zumindest von dieser Seite her die Geschwindigkeit entsprechend optimiert.
Für Windows-User siehe Eigenschaften der Netzwerkverbindung
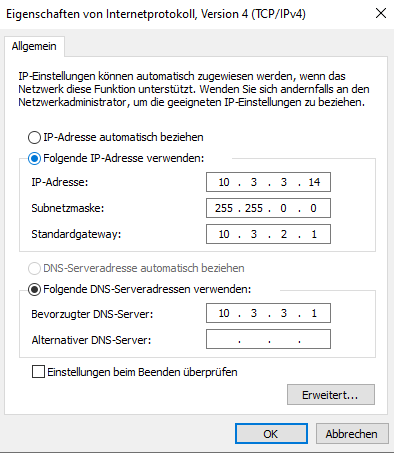
Client-Updates
Nachfolgend eine kleine Beschreibung der Besonderheiten beim Update der Clients, von aus älteren Versionen.
Alter Server
Manchmal will man die Installation vorab testen.
hier ist wichtig zu wissen, dass die neueren Clients, z.B. 0.1.1, bereits beim Starten, bevor noch irgend eine Oberfläche angezeigt wird, den Server um die Versionsnummer (der Datenbank und des Servers) abfragen.
Das bedeutet wenn du mit einem neuen Client gegen einen alten Server testest, wird dies nicht funktionieren. Der optische Eindruck ist, dass der Client nicht startet. Startes du den Client aus der Commandshell, ohne javaw.exe so siehst du
Got Exception No such EJB method org.jboss.ejb.client.EJBMethodLocator@bc7b26d3 found on lpserver/ejb/SystemFacBean java.lang.IllegalArgumentException: No such EJB method org.jboss.ejb.client.EJBMethodLocator@bc7b26d3 found on lpserver/ejb/SystemFacBean
Das bedeutet, der Client konnte zwar eine Verbindung zum Server herstellen, aber die Abfrage nach der Versionsnummer ist bereits fehlgeschlagen.
Hier hilft nur den Server auch zu aktualisieren.
Sprachsteuerung bei Anmeldung
Üblicherweise wird beim Start des Clients auch die Sprache vorgeschlagen die für den Anwender die richtige ist. Diese Definition findest du unter
?:\Kieselstein\client\bin\kieselstein-ui-swing.bat
Hier steht (ca. in Zeile 37)
´´´
set DEFAULT_JVM_OPTS="-XX:PermSize=64m" “-XX:MaxPermSize=256m” “-Djava.naming.factory.initial=org.wildfly.naming.client.WildFlyInitialContextFactory” “-Djava.naming.provider.url=remote+http://192.168.100.14:8080” “-Dloc=sl_ " “-Dsun.java2d.dpiaware=false”
´´´
mit dem Parameter -Dloc= kann gesteuert werden, welche Sprache vorgeschlagen wird. Bitte beachte: sollte die hier eingetragene Sprache in deinem Kieselstein ERP nicht aktiviert sein, so wird die nächstliegende Sprache verwendet.
Für die aktuell unterstützten Sprachen müssen folgende Einträge gemacht werden. Welche Einträge in aktiviert sind, findest du in der lp_locale.
| locale | Sprache |
|---|---|
| deAT | Deutsch mit österreichischer Sprachausprägung |
| deCH | Deutsch mit schweizer Sprachausprägung |
| deDE | Deutsch mit deutscher Sprachausprägung |
| enGB | Britisches Englisch (nicht vollständig übersetzt) |
| enUS | Amerikanisches Englisch |
| itIT | Italienisch |
| plPL | Polnisch |
| sl | Slowenisch. Bitte beachte dass die Definition des Locales mit sl_< >< > mit zwei nachfolgenden Spaces erfolgen muss. Ist eigentlich Englisch, aber um die Zahlen wie in Europa üblich darzustellen als Slowenisch definiert |
Weitere Details siehe
2.1 - Installation Kieselstein ERP Client unter Debian
Installation eines Kieselstein ERP Clients unter Debian
Den Kieselstein ERP Client auf einem frischen Debian installieren
-
pgadmin installieren –» siehe Clientbeschreibung siehe https://www.itzgeek.com/how-tos/linux/debian/how-to-install-pgadmin-on-debian-11-debian-10.html sudo apt update sudo apt install -y apt-transport-https ca-certificates software-properties-common curl
Debian 11
curl -fsSL https://www.pgadmin.org/static/packages_pgadmin_org.pub | sudo gpg –dearmor -o /usr/share/keyrings/pgadmin-keyring.gpg
Debian 11
echo “deb [signed-by=/usr/share/keyrings/pgadmin-keyring.gpg] https://ftp.postgresql.org/pub/pgadmin/pgadmin4/apt/bullseye pgadmin4 main” | sudo tee /etc/apt/sources.list.d/pgadmin4.list
sudo apt update sudo apt install -y pgadmin4-desktop Das Programm einfach unter Aktivitäten, Anwendungen (die Punkte unten) und pgadmin4 eingeben (rechtsklick, zu Favoriten)
Wenn man auch die WebObefläche nutzen will (was ich persönlich nicht mag) sudo apt install -y pgadmin4-web (ist das wirklich erforderlich?)
sudo /usr/pgadmin4/bin/setup-web.sh
pgadmin EMail Adresse postgres@wa-consulting.at pw: postgres
Frage nach Installation des Webservers mit y beantworten und dann restart Apache Webserver und dann http://127.0.0.1/pgadmin4
2.2 - Installation Kieselstein ERP Client unter Ubuntu
Installation Client zu Kieselstein ERP Server unter Ubuntu
Siehe bitte allgemeine Client Beschreibung
Um das passende Java11 FX zu bekommen sind folgende Schritte erforderlich:
apt-key adv –keyserver hkp://keyserver.ubuntu.com:80 –recv-keys 0xB1998361219BD9C9
apt-add-repository ‘deb http://repos.azulsystems.com/ubuntu stable main’
apt update
apt install zulu-11
Danach das Java Home manuell hinzufügen:
nano /etc/environment
JAVA_HOME="/usr/lib/jvm/zulu-11-amd64"
source /etc/environment
echo $JAVA_HOMEOutput: /usr/lib/jvm/zulu-11-amd64
Bzw. Herunterladen des Java FX Packages
- FX Download
- https://www.azul.com/core-post-download/?endpoint=zulu&uuid=e021b654-4fb0-4ad7-ab0a-f261a933fd71
mit dpkg installieren, einmal apt install -f, dann nochmal installieren!
2.3 - Installation Client zu Kieselstein ERP unter Windows(r)
Installation Client zu Kieselstein ERP Server unter Windows(r)
Siehe bitte allgemeine Client Beschreibung
Abschalten der Einrichtemeldung
Windows 10
Übernommen aus obigem Artikel.
Nach jedem Neustart schlägt Windows vor, das Einrichten des Geräts zu beenden. Um dies unter Windows 10 abzuschalten gehe bitte folgendermaßen vor:
- Start, Einstellungen, System, Benachrichtigungen und Aktionen
- Deaktiviere unter Benachrichtigungen das Kontrollkästchen neben Möglichkeiten vorschlagen, wie ich mein Gerät so einrichten kann, dass Windows optimal genutzt wird.
Windows 11
- Start, Einstellungen, System, Benachrichtigungen
- ganz nach unten scrollen und zusätzliche Einstellungen aufklappen
- ich persönlich entferne alle drei Häkchen
2.4 - Installation Client zu Kieselstein ERP unter macOS
Installation Client zu Kieselstein ERP Server unter macOS
Installation des Clients unter macOS
Du kannst den Client deines Kieselstein ERP auch unter macOS betreiben.
Wichtig ist von Anfang an zu unterscheiden, mit welchem Prozesser dein MAC ausgestattet ist. Entweder X64 oder Arm. Diese Information findest du unter Apfel, über diesen MAC

und dann
Der Apple M1 ist das erste Arm-basierte System-on-a-Chip (SoC) von Apple für seine Mac-Computer. Wikipedia
Das benötigte Java findest du unter https://www.azul.com/downloads/?version=java-11-lts&os=macos&package=jdk-fx#zulu
Hier:
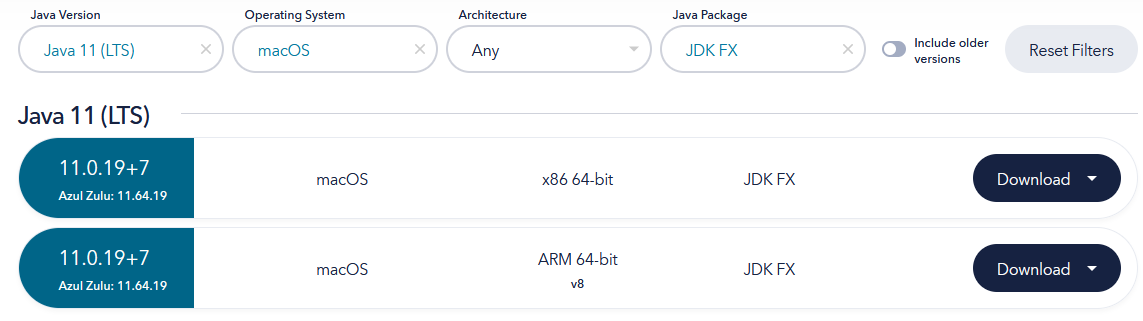
Nun das entsprechende Paket auswählen,
in der Regel .dmg.
In die Downloads gehen und
mit einem Doppelklick das JDK11 von Azul installieren.

Du kannst nun prüfen ob die soeben installierte Javaversion auch richtig installiert wurde. Dazu ein Terminal öffnen und Java -Version eingeben.

Starte nun den Safari / deinen Browser gehe dazu auf http://IPADRESSE_KIESELSTEIN_ERP:8080.
gehen. Hier wird von der Kieselsteininstallation
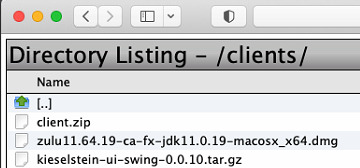
bereitgestellt.
Die Client.zip rechts anklicken und und herunterladen.
Als Ort den Schreibtisch auswählen.
Mit einem Doppelklick entzippen.
Ausführenberechtigung setzen:
Mit dem Terminal (Programme, Dienstprogramme, Terminal)
in das Verzeichnis wechseln.
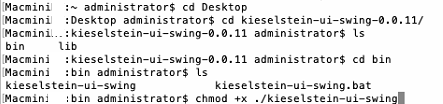
mit 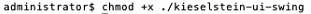
chmod +x ./kieselstein-ui-swing
die Ausführenberechtigung für das Shellscript setzen.
Nun im Finder in das Verzeichnis (Schreibtisch, Kieselstein, bin) wechseln und
rechte Maustaste, Öffnen mit, Andere

Hier bei aktivieren Alle Programme auswählen und das Immer öffnen mit anhaken.
Nun das Terminal auswählen.
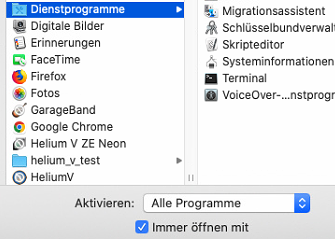
Die nun folgende Sicherheitsmeldung mit öffnen bestätigen.
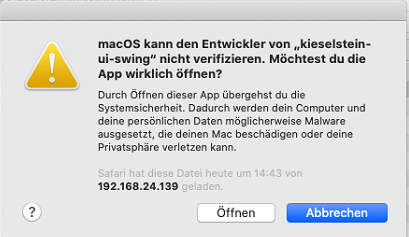
Wichtig
Wenn vom Betriebssystem Fragen kommen, ob denn nun der Zugriff auf den Drucker oder die Filestruktur erlaubt werden sollte, nicht blind den default bestätigen, sonder genau lesen und in der Regel erlauben. Du willst ja deine Files nutzen.3 - Installation RestAPI
Installation der RestAPI für Ihren Kieselstein ERP Server
Damit kann ein entsprechender Zugriff über die RestAPI auf deinen Kieselstein ERP Server erfolgen. Dieser basiert wiederum auf Tomcat / Apache.
In der Standard Installation des Kieselstein ERP Servers wird automatisch der Rest-Server mit installiert.
Für die Dokumentation zu den aktuell verfügbaren RestAPI Calls siehe
4 - Installation unter Docker
Docker nutzen, insbesondere für Tests
Gerade für die Tests neuer Versionen empfiehlt die Technik Docker zu nutzen.
Docker ist eine Art Container in dem dann die spezifischen Einstellungen für diesen Container gemacht werden können, welche die Einstellungen der anderen Docker-Container nicht berühren. So kann man ganz praktisch die verschiedensten Varianten testen.
Man kann sich das auch wie eine weitere virtuelle Maschine vorstellen, aber ohne das Betriebssystem mehrfach zu benötigen.
Windows
Die Installation in einer Hyper-V VM ist nur in besonderen Ausnahmefällen möglich. Von Docker wird empfohlen, dies NUR auf einer physikalischen Maschine einzurichten.
Download
siehe https://docs.docker.com/desktop/install/windows-install/
Dafür muss WSL (Windows Subsystem for Linux) eingerichtet sein.
- CMD as Administrator starten
- wsl –install
Richtet ein quasi Ubuntu parallel zum Windows ein
Dauer insgesamt: ca. 15 Minuten
Internet: eine gute Leitung erforderlich
Reboot des Rechners: mehrfach erforderlich
Download: Docker Desktop for Windows
Danach Docker ausführen und einen entsprechenden Linux User anlegen (Empfehlung gleich wie unter deiner Hauptmaschine)
Laden des Docker Files:
- Gitlab, Kieselstein-docker, Base-Verzeichnis
- Dockerfile herunterladen
- Ein Verzeichnis Docker anlegen und das heruntergeladene Dockerfile in dieses reinkopieren
Docker Desktop starten
- Create a Dev Environment
- Locales Verzeichnis (Docker) angeben und Continue
- nun werden alle abhängigen Dateien usw. in diesen Dockercontainer geladen. Dauer einige wenige Minuten
Dafür braucht man auch noch das Windows Admin Center, für das man sich wiederum registrieren muss.
5 - Installation KES-ZE-Terminal
Installation des Kieselstein ERP Zeiterfassungsterminals
Mit dem Kieselstein ERP Zeiterfassungsterminal steht ein praktisches Erfassungsgerät zur Verfügung um mit verschiedenen Lesern die Anwesenheitszeiten und auch die Zeiten auf Losen, Aufträgen, Projekten für Menschen und Maschinen in deren vielfältiger Form zu erfassen.
Wichtig: Auf deinem Kieselstein ERP Server muss auch die RestAPI laufen, was ab Version 0.0.0.8 in der Regel gegeben ist und natürlich musst dein Server über den Port 8280 (https ist in Vorbereitung) erreichbar sein.
Anmerkung:
Ab der Serverversion 1.x.x ist die REST-API im Wildfly integriert. Daher wird hier der Port 8080 verwendet. Es ist dafür die Version 0.0.30.x oder höher der mobilen App erforderlich.
Betriebssysteme
Derzeit steht die KES-ZE-App für Windows und Android zur Verfügung. Eine Erweiterung auf Linux Betriebssysteme ist angedacht.
Bitte beachte, dass du für die Installation auf Windowsrechnern administrative Rechte benötigst. Es werden aktuell nur Home und Pro (jeweils Win10/11) unterstützt. Ev. andere Versionen, vor allem die die den Entwicklungsmodus nicht unterstützen, können nicht verwendet werden.
Wichtig
Dass das Windows-Betriebssystem deines Terminal-PC’s auf aktuellstem Stand ist, setzen wir als selbstverständlich voraus.Programmversion
Programmtechnisch sind das Zeiterfassungsterminal und die mobile (Inventur)-App identisch. Es wird automatisch anhand des Gerätes, auf welchem das Programm ausgeführt wird, entschieden welche Anwendung nun ausgeführt wird.
| Gerät | Anwendung | Bemerkung |
|---|---|---|
| Windows PC | Zeiterfassungsterminal | mit seriellen Lesern |
| Android Tablett | Zeiterfassungsterminal | NFC Leser erforderlich |
| Android Phone | mobile App | Barcodescann über die Kamera, NFC Leser wenn verfügbar, Bluethooth Barcodescanner |
| Memor1 | mobile App | Barcodescann über die Scann-Engine, kein NFC Leser |
| Mobile App siehe |
Installation
Herunterladen der neuesten Version von https://gitlab.com/kieselstein-erp/sources/kieselstein-terminal-maui/-/releases
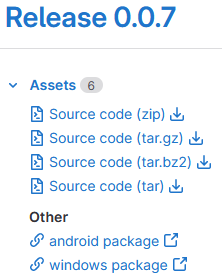
Hier je nach Betriebssystem das passende Package auswählen.
Anmerkung:
Die weitere Beschreibung geht von Windows aus.
WICHTIG: eine eventuell bereits vorhandene Version vorher entfernen -> siehe unten.
Klick auf Download, die heruntergeladene Datei und
- die neueste Version kopieren und z.B. nach ?\install kopieren.
- den Zielordner notieren.
- Starttaste (Windowstaste) und Eingabe von Power
Windows Powershell aufrufen und als Administrator ausführen.
In das notierte Zielverzeichnis wechseln.

Install.ps1 starten.
Sollte nun nachstehende Fehlermeldung kommen

so sind die Ausführungsrechte für Powershell Scripts nicht gesetzt.
Kommt die Fehlermeldung ist nicht signiert so siehe.
Um diese zu setzen, im PowerShell
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned
eingeben und die Frage nach

mit A (Ja für alle) und anschließendem Enter beantworten.
(Tipp einfach den Text kopieren und mit Strg+V in Powershell einfügen.)
Wichtig: Insbesondere das ändern der Policy erfordert Administrator Rechte. Kommt nach dem Ausführen obigen Befehls wieder die gleiche Abfrage, hast du zuwenig Rechte.
WICHTIG:
Nun Powershell beenden und in normalen Modus starten. Dies ist insbesondere für das Update zukünftiger Versionen wichtig. Siehe aber auch Berechtigungsfehler
Danach die Installation erneut mit .\Install.ps1 starten.

und die Frage mit A (Immer ausführen) und Enter beantworten.
Bei der ersten Installation erscheint nun die Aufforderung den Entwicklermodus zu aktivieren.
D.h. schalte den Entwicklermodus auf Ein / On und beantworte die nachfolgende Frage

mit Ja. Danach bitte das Einstellungenfenster schließen (Klick auf das X rechts oben)

Auch diese Frage mit J (Ja) beantworten.
Am oberen Rand des Powershell Fensters erscheint nun die Fortschrittsanzeige.

Zum Ende der Installation erscheint

Klicke nun auf den Start-Button und füge die neu installierte App zum Start hinzu.
Damit kannst du jederzeit, z.B. zum Testen den Terminal manuell starten.
Zusätzlich kannst du damit das Terminalprogramm auf den Desktop ziehen (aus dem Start auf den Desktop).
.Net Framework
Ab der Terminalversion 0.0.20 ist ein aktuelles DotNet Framework erforderlich. Dies kann hier heruntergeladen werden.
Die Aufforderung zur Installation erscheint beim ersten Start des Terminalprogramms.
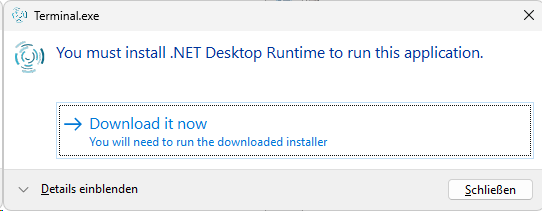
Je nach Einstellung des Browsers auf deinem Terminal wird
das zu installierende Framework sofort herunter geladen.
Bitte installieren. Du benötigst dafür entsprechend administrative Rechte.
Wichtig:
Die Terminalsoftware muss unter dem dann verwendeten Benutzer eingerichtet werden. Je nach Firmenpolitik hilft manchmal folgender Trick.
Gib vorab dem Terminalbenutzer lokale Administrations Rechte (Domain Admin) um die Terminalsoftware installieren und einrichten zu können. Nach der Installation und fertigem Einrichten, kann dieses Recht wieder entfernt werden.
Beachte immer, dass vor einem Update, das Betriebssystem des Terminals aktuell ist.
Einrichten des Terminals
Starten des Terminals über Start
Beim ersten Start kommt in der Regel die Fehlermeldung, dass sich das Terminal nicht verbinden kann.
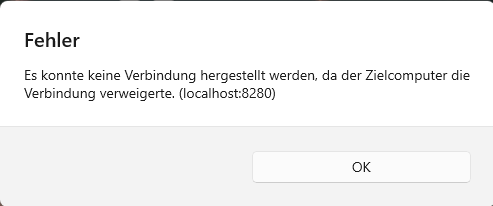
Bestätige diese Meldung und wähle anschließen das Setup des Terminals durch Klick auf

Eintragen des ComPorts
Feststellen welcher Comport für den Barcodescanner / den RFID Leser zur Verfügung steht, über den Gerätemanager (Rechtsklick auf den Startbutton) 
Hier findest du unter
 den Comport für das / die angeschlossenen Eingabegeräte. In unserem Falle nun Com4 für den Barcodescanner.
den Comport für das / die angeschlossenen Eingabegeräte. In unserem Falle nun Com4 für den Barcodescanner.
Hinweis: Die Nummer des Comports hängt auch vom gewählten USB Anschluss ab. D.h. wenn der Standort des Terminals verändert wird, sollten bei der Aufstellung am neuen Standort die Geräte exakt an den gleichen USB Port angeschlossen werden, anderenfalls muss die Konfiguration wieder neu gemacht werden.
Wichtig: Damit der Comport überhaupt zur Auswahl steht, muss vor dem Start des Terminalprogrammes der Barcodescanner / der RFID Leser bereits angeschlossen sein und im Gerätemanager aufscheinen. Sollte der Scanner beim Scannen eines Barcodes ein grgr Geräusch von sich geben, bedeutet dies, dass der Scanner erkennt, dass er logisch betrachtet nicht angeschlossen ist.
Trage nun die abgefragten Parameter ein:
Danach Klick auf speichern und anschließend Anwendung beenden um danach das Terminal neu zu starten.
Kommt nun die Meldung
so sind folgende Fehlermöglichkeiten gegeben, stimmen folgende Werte nicht zu deiner Kieselstein ERP Installation.
- es muss den Benutzer Terminal, terminal geben mit entsprechenden Rechten (siehe unten)
- es muss das Logon Locale mit dem Locale das Mandanten übereinstimmen
- es muss der Logon Mandant mit dem gewünschten Mandanten übereinstimmen Bitte beachte, dass die Sprache des Terminals nur für die Anzeige der verschiedenen Texte (Kommt, Geht usw.) verwendet wird.
Wenn Korrekturen am Setup gemacht wurden, so diese speichern und das Terminal neu starten.
BEACHTE
Wenn deine Sprachdefinition nur zwei Zeichen hat, müssen danach zwei Leerstellen eingetragen werden. Es werden sonst die Sprachen nicht erkannt, was sich bis dahin auswirken kann, dass keine Buchungen, wegen fehlender Sprachen, durchgeführt werden.Ein guter Test ist auch die Anzeige der Kommt / Geht -Buchungen zu nutzen. Diese müssen in der gewünschten Sprache, wenn sie am Client bereits übersetzt sind, erscheinen.
Nach einem erfolgreichen Neustart, erscheint in der oberen Statuszeile

Abschalten der Leser
Es kommt immer wieder die Frage, wie man die Leser, die man z.B. zu Testzwecken aktiviert hat, deaktivieren kann. Dazu ganz einfach auf den jeweiligen Port klicken und einen leeren Port zuordnen. Sollte sich aus irgend einem Grund, dieser nicht zuordnen lassen, so bitte die Terminal App deinstallieren
Zeiten buchen
Scann der Ausweisnummer. Bei einer gültigen Ausweisnummer (siehe Personal, Journal, Personalliste, Barcodeliste) wird der Name angezeigt und die derzeit möglichen Funktionen dargestellt.

Wähle nun deine Buchung. Nach erfolgreicher Buchung erscheint kurz die Meldung

In deinem Zeiterfassungsclient findest nun diese Buchung mit der aktuellen Uhrzeit in in der Quelle den Computernamen des erfassenden Rechners.
Wenn Offline angezeigt wird, also das Terminal keine Verbindung zu deinem Kieselstein ERP hat, wird der Status wird alle 30" geprüft. D.h. wenn man alles eingestellt hat, sollte es nach 30" gehen
Wie sieht man auf welchem Terminal gebucht wurde?
Im Modulzeiterfassung, bei der jeweiligen Person sieht man unter Quelle den PC-Name / Hostnamen des Rechners von dem aus gebucht wurde. So kann man mit einer sprechenden Namensvergabe sehr leicht die Zuordnung wo denn der Mitarbeiter / die Mitarbeiterin gebucht hat treffen.

Hinweis:
Wir raten dazu, jedem Terminal, egal ob unter Windows oder Android einen eindeutigen und für dich lesbaren Namen zu geben.
- Unter Windows, System, diesen PC umbenennen
- im Android, Einstellungen, Über das Telefon, dann Gerätename und diesen entsprechend benennen. Die genaue Benennung ist je nach Android Betriebssystem unterschiedlich. Im Gegensatz zu Windowsrechnern, haben alle Androidgeräte eines Herstellers die den gleichen Namen. Damit vom Android diese Gerätennamen übertragen werden, ist die Version 0.0.30 oder höher erforderlich.
Rechte
Für das Terminal sollten (nur) die unten angeführten Rechte vergeben werden. In Kombination mit der VDA-SCANN-App ergeben sich daraus folgende Einstellungen:
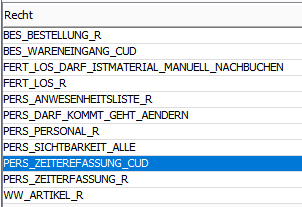
ACHTUNG: Hier fehlt das Recht: PERS_ZEITERFASSUNG_MONATSABRECHNUNG_DRUCKEN ohne diesem spinnt die Saldo Darstellung im Terminal, was man aktuell nur im LogFile sieht.
Bitte beachte, dass für das Terminal auch die Zuordnung unter Benutzermandant gegeben sein muss. Auch hier bitte nur die unbedingt notwendigen Rechte vergeben. Also:
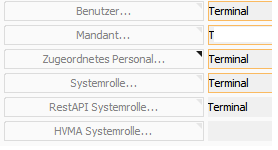
Denke daran auch die Zuordnung für die RestAPI Systemrolle einzutragen.
Hinweis1: Werden die Rechte für das Terminal angepasst, ist kein Neustart des Terminal-Programms notwendig.
Hinweis2: Wurde die Darstellung der Personen aktiviert, also Anmeldeseite und beim Start des Programms werden keine Personen angezeigt, so fehlen die Rechte für die Personen.
Diese Rechte sind nur für das Zeiterfassungsterminal erforderlich
Also dann, wenn das Terminal nur für die Anwesenheitszeiterfassung verwendet wird.
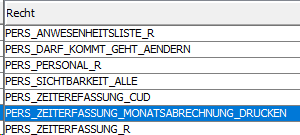
Diese Rechte sind zusätzlich für die Fertigung erforderlich
Wird das Terminal auch für die Buchung der Fertigungsbegleitscheine verwendet, so sind zusätzlich nachfolgnede Rechte erforderlich.
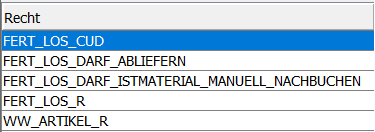
Denke daran, dass bei Material Buchungen bzw. Ablieferbuchungen auch Rechte auf das Lager vergeben werden müssen. Also für die Rolle Terminal auch im Reiter Lager zumindest
Recht um auf Aufträge zu buchen
Sollte mit dem Terminal auf Aufträge gebucht werden, so muss das Terminal auch das Recht haben um auf den Auftrag Zeiten zu buchen. Also
Einrichten Autostart des Terminals
Damit dein Zeiterfassungsterminal immer startet, den Autostart einrichten.
Hier muss zwischen Windows 10 und Windows 11 unterschieden werden.
Windows 10
- Die Verknüpfung zum Terminalprogramm muss am Desktop eingerichtet sein.
- Windows-Taste + R und shell:startup
- Windows Explorer mit Autostart öffnet sich
- Die Verknüpfung vom Desktop in den Autostartordner ziehen / bzw. mit Strg kopieren.
Windows 11
Idealerweise bringst du zuerst das Terminal Starticon auf den Desktop. Da diese Applikation als versteckte App betrachtet wird, den Windows-Explorer starten (Windowstaste + E) dann in die Adressleiste
%windir%\explorer.exe shell:::{4234d49b-0245-4df3-b780-3893943456e1} einkopieren (danke an Netzwelt). Hier findest du eine Liste ALLER Applikation die auf dem Rechner installiert sind.
Hier nach dem Kieselstein-ERP Terminalsuchen und dieses auf den Desktop ziehen. Weiter mit:
- Windows-Taste + R und shell:startup
- Windows Explorer mit Autostart öffnet sich
- Die Verknüpfung vom Desktop in den Autostartordner ziehen / bzw. mit Strg kopieren.
Daran denken
Bitte denke daran, dass für den Terminalrechner in der Regel jeglicher Standby Betrieb deaktiviert werden sollte. D.h. gerne können sich die Festplatten usw. abschalten, aber die normale Bedienung wie Bildschirm müssen aktiv bleiben.
Bitte denke auch daran, dass das Terminal so eingestellt sein muss, dass es nach einem eventuellen Stromausfall sofort wieder startet.
Einstellungen des Terminals sind Benutzerrechte
Idealerweise installierst du das Terminal unter dem Benutzer unter dem auch das Terminalprogramm laufen sollte. Wenn du aus verschiedenen Gründen das unter einem anderen Benutzer installieren musst, denke daran, dann für den Terminalbenutzer die Konfiguration erneut durchzuführen.
Neuerungen mit der Version 0.0.8
Mit der Version 0.0.8 des Terminals stehen zusätzlich

- Anmeldeseite anzeigen
- Saldo Button anzeigen
zur Verfügung.
Anmeldeseite anzeigen
Damit werden alle Personen die im Personalstamm eingetragen sind und eine Ausweisnummer eingetragen haben in Form einer Buttonliste angezeigt.

Durch Tipp auf den Button gelangt man weiter zur Buchungsseite des Terminals.
Saldo Button anzeigen
Wird der Saldo Button angezeigt, so wird neben Kommt, Pause, Geht auch noch Saldo angezeigt. Mit Tipp auf Saldo wird der aktuelle Zeitsaldo des laufenden Monates ermittelt und angezeigt.
Tippt man nun auf Detail wird die Monatsabrechnung des aktuellen Monates angezeigt.
Hinweis1: Die Stunden des Zeitsaldos werden immer vom letzten des Vormonates errechnet. D.h. damit diese stimmen, müssen auch die Monatsabrechnungen ausgedruckt worden sein.
Hinweis2: Wird nach dem Klick auf den Saldo Button nichts angezeigt / es erfolgt keine Reaktion, dann fehlt bei der Person das Eintrittsdatum, womit keine Berechnung von gültigen Stunden erfolgen kann.
Neuerungen der Version 0.0.9
Mit der Version 0.0.9 des Terminals stehen zahlreiche weitere Funktionen, vor allem im Bereich Barcode-Scann zur Verfügung. Die wesentlichste Neuerung ist allerdings die offline Fähigkeit. D.h. es können, auch wenn das Terminal vorübergehend keine Verbindung zum Kieselstein ERP Server hat, die wesentlichsten Buchungen zwischengespeichert werden. D.h. diejenigen Buchungen, die ohne Antwort vom Server nur gespeichert werden müssen, werden im Terminal gespeichert. Steht die Serververbindung dann wieder zur Verfügung, werden innerhalb kurzer Zeit die Buchungen an den Server übertragen.
Weitere Funktionsbeschreibungen siehe
Neuerungen der Version 0.0.10
- Anzeige der Maschinenliste mit Datum, sowie Korrektur kleinerer Bugs
- Reconnect des Barcodescanners, falls während des Betriebes die Verbindung verloren gegangen ist (was leider manchmal bei Stromschwankungen und ähnlichem passiert).
Netzwerkverbindung
Für das Terminal muss eine Netzwerkverbindung, also mehr wie ein lokales Netz (nur auf dem einen Rechner) verfügbar sein, damit das Terminal dieses Netzwerk als gültige Verbindung ansieht. Localhost wird speziell behandelt.
Hintergrund: Gerade für die mobilen Geräte, muss man sehr rasch erkennen können, ob noch
eine Netzwerkverbindung da ist oder nicht. Es würde sonst das Netzwerk-Timeout jeweils 4-5Minuten dauern, was sehr unpraktisch wäre.
Weitere Funktionen
Die Konfiguration ist mittels Passwort geschützt
Wenn du auf die Konfiguration klickst, so erscheint gegebenenfalls die Abfrage nach einem Passwort.
Hier muss das hinterlegte Passwort eingegeben werden. Bitte entsprechend ändern / sorgfälltig behandeln.
Löschen falscher Comport Zuordnungen
Gerade bei den Tests am Terminal verwendet man schon auch mal andere Erfassungsgeräte. Entfernt man nun diese, z.B. den Barcodescanner, so kommt beim nächsten Start des Terminals Comport xy ist nicht vorhanden. Um diese Meldung abzuschalten, in die Einstellungen gehen und bewusst den Comport z.B. des Barcodescanners auswählen und danach auf speichern tippen. Damit ist die Zuordnung gelöscht.
Die Meldungsbuttons sind zu klein
Je nach Größe des Terminal-Gerätes sind schon mal die Knöpfe bei den Meldungen zu klein. Abhilfe schafft man hier dadurch, dass man über das Betriebssystem die default Darstellung / Vergrößerungsfaktor höher dreht.

Die Monatsabrechnung hat mehr wie eine Seite
Wenn die Monatsabrechnung mehr wie eine Seite hat, so wird trotzdem nur die erste Seite dargestellt. Bitte gestalte den Report so, dass er auf einer Seite Platz hat. Denke bitte dabei auch an deine / eure Mitarbeiter die am Terminal den Report lesen wollen. Hier ist meist weniger mehr. Tipp: Stelle den Report auf Hochformat oder wenn wirklich erforderlich auf ein noch höheres Format, sodass alles auf einer Seite dargestellt werden kann.
Timeouts der verschiedenen Anzeigen
Wir haben uns vorerst dazu durchgerungen, die Timeouts auf den verschiedenen Anzeigen nicht zu implementieren. Die bisherigen Erfahrungen haben gezeigt, dass diese immer zu lange oder zu kurz, aber sehr selten richtig sind. Es gibt anstatt dessen einen Button zurück, mit dem man wieder in die normale Erfassung, des Ausweises, kommt.
Einrichten auf einem Windows PC
Mit der Version 0.0.9.0 kann das Terminal auch im Vollbildmodus betrieben werden. Damit auch im Vollbildmodus die Meldungen des Terminals angezeigt werden, muss der Benachrichtigungsmodus entsprechend eingestellt werden.
Windows 10
Windows 10:
“System” - “Benachrichtungsassistent” - “Automatische Regeln”: Wenn ich eine App im Vollbildmodus verwende" auf “AUS” setzen.
Für englische Terminals “System” - “Notifications & actions” - “Focus assist” - “Automatic rules” “When i’m using an app in full-screen mode” is switched to “OFF”
Windows 11
- Benachrichtigungen generell ein
- im Bitte nicht stören, den Haken bei Bei Verwendung einer App im Vollbildmodus … -> raus
- und noch zusätzlich die Benachrichtigung der App Kieselstein-ERP Terminal, einschalten
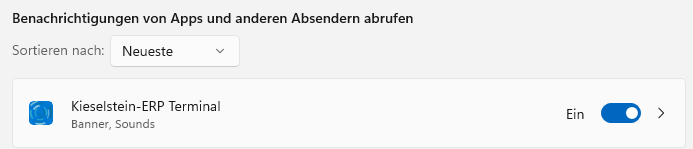
Solltest du ein Terminal in englisch nutzen, so findest du diese Einstellungen unter
bzw. dann weiter unten

Hinweis zur Bildschirmtastatur:
Diese steht nur zur Verfügung, wenn auf dem Gerät keine physikalische Tastatur angeschlossen ist. Das gilt auch, wenn eine Fernwartungssitzung zum Terminal aktiv ist. D.h. idealerweise NACH der Fernwartungssitzung den Terminal-PC komplett neu starten (diese Tastatureinstellungen werden nur beim Betriebssystemneustart übernommen).
Unter Windows 10:
- Einstellungen, System, Tablet
- Wenn ich das Gerät als Tablet verwende, immer in den Tablet Modus wechseln
- dann weiter zu:
- Zusätzliche Tablett Einstellungen
- Bildschirmtastatur anzeigen, wenn keine Tastatur angeschlossen ist.
- Zusätzlich: Tablet Modus aus.

oder

Unter Windows 11
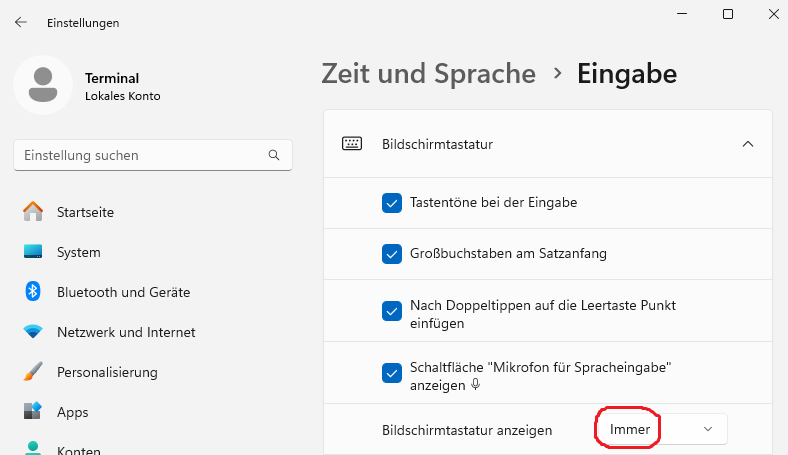 Stelle idealerweise die Bildschirmtastatur auf immer aktiv.
Stelle idealerweise die Bildschirmtastatur auf immer aktiv.
Bedienung der Tastatur
Es ist oft praktisch nur eine kleine Tastatur eingeblendet zu haben.
Dazu einfach rechts oben auf die Tastatur mit Pfeil nach unten tippen, bzw. dann auf die Tastatur mit dem Pfeil nach oben.
Um die Bildschirmtastatur zu aktivieren, müssen folgende Einstellungen getroffen werden:
- Einstellungen, Zeit und Sprache
- auf Eingabe klicken
- Bildschirmtastatur erweitern und Bildschirmtastatur anzeigen auf immer stellen.
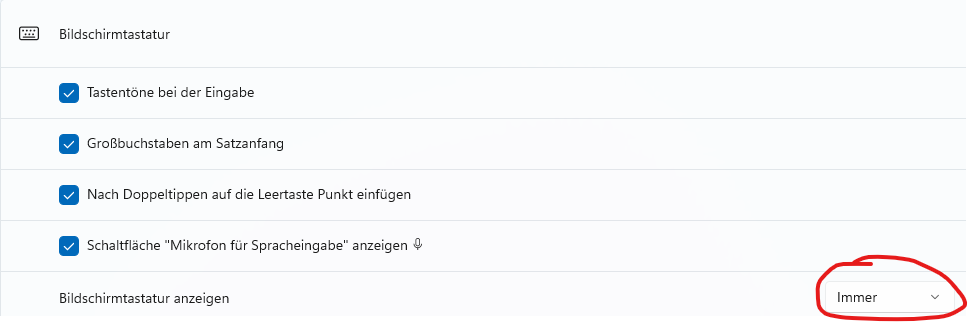
Swipe Modus abschalten
Wenn das Terminal im Vollbildmodus betrieben wird und man verhindern will, dass durch wischen von den Ecken das sogenannte Windows Action Center aktiviert wird und damit der Benutzer auf das Betriebssystem kommt, muss diese Funktionalität über die Registry abgeschaltet werden. Dazu sowohl in Windows 10 als auch 11 im Key
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\PolicyManager\default\LockDown\AllowEdgeSwipe
den Wert auf 0 setzen und danach neu starten.
Weitere mögliche Einstellungen
Manche Anwender haben gerne noch weitere Anpassungen. Siehe dazu
eine bestehende Installation aktualisieren
Lade wie beschrieben die aktuelle Version herunter.
Entpacke die Datei in ein Verzeichnis deiner Wahl, z.B. d:\kieselstein\terminal\Terminal_0.0.9.0_Test. Hier findest du nun die Datei Terminal_0.0.Version.0_x64.msix. Diese starten und aktualisieren wählen.
Dies sollte unter dem Terminalbenutzer erfolgen.
eine bestehende Installation entfernen
Bevor du eine neue Version des Terminals installierst ist es derzeit erforderlich die bestehende Installation zu beenden. Dazu, Start, Einstellungen, Apps, und dann durch Eingabe der Anfangsbuchstaben die Kiesel.
Ab der Version 0.0.10 ist das Entfernen nicht mehr erforderlich.
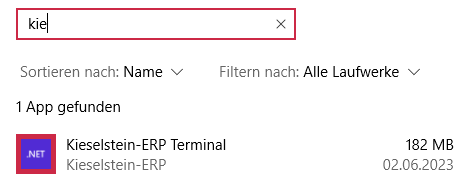
das Terminalprogramm anzeigen und anklicken und dann
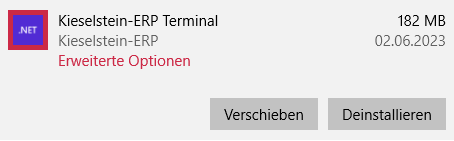
Deinstallieren auswählen.
Tipps & Tricks
Wenn das Terminal nicht startet, z.B. mit Verbindung verweigert, so prüfe ob du vom Terminal-Rechner aus die Rest-API-Doku anzeigen kannst. Das Terminal nutzt die Restapi für die Buchungen. Ist diese nicht gestartet, ist natürlich keine Verbindung möglich.

Log-File
Die Terminal-App schreibt auch ein Logfile, in dem wesentliche Schritte z.B. beim Programmstart protokolliert werden. Dieses findest du unter:
c:\Users\Terminalbenutzer\AppData\Local\Packages\cce53e67-e463-4746-bede-e7cae70f832a_5wc6556p9s44j\LocalCache\KieselsteinTerminalLogs
Anstatt des Terminalbenutzer bitte durch den für das Terminal verwendeten Benutzer ersetzen.
Welches Terminal ist das?
Gerade wenn mehrere Terminals im Einsatz sind und man mit den verschiedensten Parametrierungen kämpft, ist es praktisch zu wissen welches Terminal was ist. Auch wenn es z.B. um die Einrichtung des automatischen Ausdruckes von Ablieferetiketten geht.
Du findest diese Info in der Titelleiste des Konfigurationsmenüs.

Uhrzeiten synchronisieren
Zertifikats-Fehler
Kommt unmittelbar beim Start der Installation die Fehlermeldung:
Fehler: Das Paket bzw. Bundle ist nicht digital signiert, oder die Signatur ist beschädigt

so sollte herausgefunden werden, was die eigentliche Ursache für den Fehler ist. Üblicherweise kommt der Fehler von einem defekten Download oder einer alten Installation unter falschen Benutzerberechtigungen. In diesem Falle raten wir zu folgender Vorgehensweise:
- Terminal-App komplett deinstallieren
- Terminal-App neu herunterladen
Sollten nun der Fehler trotzdem bestehen, kannst du versuchen die Ursache warum das Zertifikat nicht installiert werden kann manuell herauszufinden. Dazu in das Installationsverzeichnis der Terminalsoftware gehen und das Zertifikat manuell installieren:
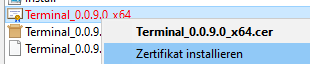
Dann am Besten
Lokaler Computer auswählen.
Danach alles default installieren.
Man sollte dann anhand der Fehlermeldung erkennen können, was die eigentliche Ursache ist, warum die Installation nicht geht. Dann eben diesen Fehler entsprechend abstellen.
Berechtigungs-Fehler
Erscheint bei der Installation des Terminals

so hast du zuwenig Rechte um die App zu installieren.
Hier ist wichtig zu wissen, auch wenn du als Administrator angemeldet bist, aber das Powershell nicht mit als Administrator ausführen gestartet hast, hat das Powershell unter Umständen zu wenig Rechte um die Installation vorzunehmen. Daher dann, entgegen obiger Beschreibung das PowerShell für die Terminal-Installation mit “als Administrator ausführen”  starten.
starten.
Der Nachteil (der auch ein Vorteil sein kann): Neuinstallationen / Updates müssen auch entsprechend gleich ausgeführt werden.
Fehlermeldungen
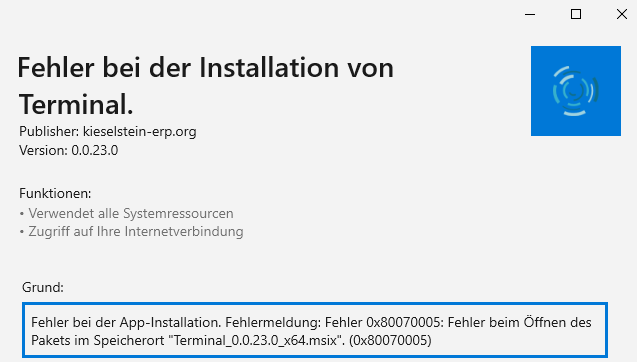
Deutet darauf hin, dass vom Sys-Admin keine Rechte sind um die Software unter diesem User zu installieren.
Prüfe zusätzlich ob das Betriebssystem deines Terminals auf aktuellem Stand ist. Oft sind Fehler dieser Art auf fehlende Updates zurückzuführen und natürlich: Denke daran, nach diversen Einstellungsversuchen die Terminal Hardware auch mal durchzustarten.
Stromversorgung
Üblicherweise erwarten sich die Mitarbeiter, dass Zeiterfassungs-Terminals 24/7 verfügbar sind. Daher sind diese auch Offline-fähig programmiert. Das bedeutet aber auch, dass die Stromversorgung für das jeweilige Terminal entsprechend stabil gegeben sein muss.
Freie Positionierung des Terminalfensters
Wird das Terminal in der Konfiguration so eingestellt, dass Vollbildmodus aus und das Verschiebbar ein ist,
 ,
,
so kann in der Mitarbeiter Erfassungsmaske die Position des Terminalfensters festgelegt werden und mit Klick auf  Terminal Fensterposition speichern, diese Position für den nächsten Aufruf gespeichert werden.
Terminal Fensterposition speichern, diese Position für den nächsten Aufruf gespeichert werden.
Um die Position des Fensters horizontal zu verschieben, wählt man den linken Rand des Terminalfensters, bis die Maus zum Doppelpfeil <-> wird. Dann links Klick mit der Maus und an die gewünschte Position ziehen. Analog mit der vertikalen Position am oberen Rand umgehen.
Die Breite / Höhe wird in der Konfiguration fix eingestellt.
Daran denken, gegebenenfalls die Position zu speichern .
Terminal AddOns
Bildschirmschoner mit Anwesenheitsliste
Proxyserver für Anwesenheitsliste
Wenn du mehr wie 2Terminals im Einsatz hast und ev. viele MitarbeiterInnen, bzw. eine komplexe Anwesenheitsliste. Verlagert die Abfragedauer auf den Proxyserver, wodurch dein Terminal auf den Bildschirmschoner wesentlich schneller reagiert.
Offline Lese Stifte
5.1 - Windows Einstellungen zum KES-ZE-Terminal
mögliche Einstellungen unter Windows für dein Kieselstein ERP Zeiterfassungsterminal
Für manche Anwender haben sich folgende Einstellungen bewährt / als praktisch herausgestellt.
Bitte beachte, dass diese Einstellungen von der jeweiligen Windowsversion abhängig sind und sich jederzeit ändern können / eine andere Auswirkung haben (oder auch keine mehr)
Einstellungen Windows 11
WLAN abschalten
System - Benachrichtigungen:
Bitte nicht stören automatisch aktivieren -> Bei Verwendung einer App im Vollbild…
Ausschalten
System - Sound:
- Die Datei message-notification-103496.wav nach Windows\Media kopieren, Lautstärke -> 100
- Erweitert - weitere Soundeinstellungen -> alter Dialog öffnet sich
- Reiter Sounds:
- Benachrichtigung: Datei auswählen: message-notification-103496
- Button Speichern unter -> als kieselstein speichern
- Übernehmen und OK
- Fenster schließen
- Anmerkung: Testen klappt nicht immer wenn das Fenster geöffnet
- Anmerkung: Manchmal braucht es einen Neustart damit auch bei der Benachrichtigung aus der App der Sound kommt
Zeit und Sprache - Eingabe:
- Bildschirmtastatur
- Schaltfläche Mikrofon -> ausschalten
- Bildschirmtastatur anzeigen -> Immer
Personalisierung
- Farben:
- Modus auswählen -> Dunkel
- Texteingabe:
- Design -> Dunkel
- Bildschirmtastatur -> Tastaturgröße 150, Textgröße mittel
- Taskleiste:
- Taskleistenelemente:
- Suchen -> Ausblenden
- AktiveAnwendungen -> Aus
- Widgets -> Aus
- Symbole in der Taskleiste
- Bildschirmtastatur -> Immer
- Taskleistenelemente:
- Andere Taskleistensymbole:
- Alle auf Aus
- Verhalten der Taskleiste:
- Taskleistenausrichtung -> Links
Windows Update
- Erweiterte Optionen
- Nutzungszeit 4:00 - 22:00
Bildschirmtastatur:
- Tastaturlayout -> klein
Neben dem Passwortdialog positionieren, ca. 1 Tastenbreite Abstand
EdgeSwipe sperren:
Regedit aufrufen und Wert ändern bei:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\PolicyManager\default\LockDown\AllowEdgeSwipe
change “Value” from 1 to 0
Einstellungen Screensaver:
- Wartzeit 2 Min
- Einstellungen:
- Application Server: IP-Adresse deines Kieselstein-ERP Servers oder alternativ des Proxy Servers
- Port: 8080
- Updateintervall: 30
- Zoomfaktor: 1,3
5.2 - Barcodesimulator
Einrichten eines Barcodesimulators für das Kieselstein ERP Zeiterfassungsterminals
Barcodesimulator
Zum Testen des Kieselstein ERP Zeiterfassungsterminals ist es oft praktisch die zu erzeugenden Barcodes nicht immer ausdrucken zu müssen, sondern diese entsprechend mit einem Programm zu generieren und an das Terminal zu senden.
Dafür benötigst du die Entwicklungsumgebung für die MAUI App.
Hier kann nun im Projektmappenexplorer (rechter Rand)
der BarcodeSimulator ausgewählt werden.
Rechtsklick auf den BarcodeSimulator und Debuggen auswählen.
Es wird damit auch die Exe erzeugt, die du auch eigenständig starten kannst. Du findest diese unter c:\Users\BENUTZERNAME\source\repos\kieselstein-terminal-maui\BarcodeSimulator\bin\Debug\net7.0-windows\BarcodeSimulator.exe
Kurze Beschreibung:
- Im Feld rechts oben kannst du den zu sendenden Barcodeinhalt angeben
- mit Add wird er in die Liste der zur Verfügung stehenden fertigen Barcodes mit aufgenommen
- Doppelklick auf den Barcode aus der Liste übernimmt diesen in das Textfeld um somit weitere Kommandos zu erzeugen
- Unten muss der Comport über den gesendet wird ausgewählt werden
- Klicken auf Send sendet das aus der Liste gewählte Kommando
Nullmodem Software
Um nun am gleichen Gerät eine Verbindung zwischen dem Barcodesimulator und deinem Terminal herzustellen, benötigst du eine Software die die Funktionalität eines Null-Modemkabels bietet.
Dafür kannst du diese Software aus dem angegebenen freevirtualports.com verwenden und
eine lokale Bridge einrichten.
Damit stellst du ein virtuelles serielles Verbindungskabel zwischen dem Barcode Simulator und deinem Terminal her. D.h. der eine Com_Port ist der Simulator und der andere ist das Terminal.
Somit ist in diesem Beispiel
| Simulator | Verbindung | Terminal |
|---|---|---|
| Com2 | <–> | Com1 |
Alternativ kann anstelle des freevirtualports z.B. auch den Nullmodem-Emulator von
www.sourceforge.net/projects/com0com/ verwendet werden.
Ist dieser installiert, so siehst du dies im Gerätemanager unter Serialport Emulator.
5.3 - Leseeinheiten zum KES-ZE-Terminal
Leseeinheiten zum Kieselstein ERP Zeiterfassungsterminals
Für das Kieselstein ERP Zeiterfassungsterminal stehen verschiedene Erfassungsgeräte zur Verfügung.
Derzeit werden folgende Geräte unterstützt:
Barcodescanner
Alle die eine COM-Schnittstelle simulieren und den gescannten Code 1:1 an die COM weitergeben und diesen mit CR abschließen.
Ob der gescannte Code nun ein eindimensionaler Barcode oder ein QR Code ist, ist für das Terminal unwesentlich.
RFID Leser
Es werden verschiedene RFID Leser unterstützt, mit denen in weitere Folge die unterschiedlichsten RFID-Tags gelesen werden können
TWN3
TWN4
Der TWN4 ist zwar nicht ganz billig, aber der Leser mit dem derzeit noch alle Arten von RFID Chips gelesen werden konnten. Von Mifare über Legic bis … . Einzig Siemens VOS ist damit nicht lesbar.
Im Terminal als TWN3 einstellen.
Die Programmierung und damit die Auswahl welche Tags gelesen werden können, muss in einer eigenen App durchgeführt werden. Die grundsätzliche Vorgehensweise ist wie folgt:
Vor dem Beginn der Arbeiten, den Reader an USB anschließen
- Starten Appblaster
- Button “configurable project”
- Multi CDC auswählen => CDC steht für ComPort
- Links Action Item auf Transponder Types und dann Categorie Legic
- Create Image -> damit schreibt er die Config auf die Platte und dann
- Programm Image damit wird das Device programmiert
Im Gerätemanager muss er Serial RFID Device anzeigen
Man kann, um herauszufinden welche Art von Tag das ist, alle Tags in die Active Transponder Types übernehmen und sukzessive herauslöschen.
Am Einfachsten dazu den Leser auf Wedge stellen = Application Templates Multi Keyboard
Das Konfigurationsprogramm findest du unter TWN4DevPack406.zip
Mifare OEM
PROMAG_PCR300
6 - Installation KES-App
Installation der Kieselstein ERP mobilen App
Mit der Kieselstein ERP App steht ein praktisches mobiles Erfassungsgerät zur Verfügung
Wichtig: Auf deinem Kieselstein ERP Server muss auch die RestAPI laufen, was ab Version 0.0.0.8 in der Regel gegeben ist und natürlich musst dein Server über den Port 8280 (https ist in Vorbereitung) erreichbar sein.
Anmerkung:
Ab der Serverversion 1.x.x ist die REST-API im Wildfly integriert. Daher wird hier der Port 8080 verwendet. Es ist dafür die Version 0.0.30.x oder höher der mobilen App erforderlich.
Betriebssysteme
Derzeit steht die KES-App für Android zur Verfügung.
WICHTIG: Wenn du die Identifizierung mit NFC Karten verwenden möchtest, ist eine doppelte Identifizierung (keine zwei Wege App) erforderlich.
Dafür müssen für die Benutzer spezielle Rechte zweistufig eingerichtet werden.
Wenn du dies nutzen musst, wende dich bitte derzeit an die Technik.
Installation
Neben der Installation über GitLab stellen wir gerne auch das APK (Android Package Kit) direkt zur Verfügung. Üblicherweise installieren wir dies über den Totalcommander für Android. Da die direkte Installation aufgrund von Google Regeln nicht mehr möglich ist, hat Herr Ghisler unter https://www.totalcommander.ch/android/appinstaller110.apk einen eigenen Installer  zur Verfügung gestellt.
zur Verfügung gestellt.
Alternativ dazu kannst du auch vom GooglePlayStore Files by Google herunterladen.
 und damit die Installation durchführen.
und damit die Installation durchführen.
Welche mobile Barcodescanner werden unterstützt?
Aktuell werden folgende Barodescanner unterstützt.
Die Definition dazu findest du auch im Quellcode ganz am Ende, DeviceInfo.Platform
| Hersteller | Gerät | ab App-Version | Verfügbarkeit |
|---|---|---|---|
| Datalogic | Memor 1 | 0.0.10 | wird vom Hersteller nicht mehr geliefert |
| Zebra Technologies | TC 21 bzw. TC26 | 0.0.20 | |
| Zebra Technologies | TC 22 bzw. TC27 | 0.0.32 |
Installation am Memor
- WLan einrichten (Einstellungen, WLan)
- Einstellungen, Geräteinfo, ganz unten, Build Nummer
7 x Antippen um den Entwicklermodus einzuschalten
Dann in die Entwickleroptionen, USB-Debugging einschalten
Zusätzlich, Einstellungen, verbundene Geräte, auf USB tippen und Datei übertragen anhaken - Micro USB Kabel, Verbindung PC, Memor herstellen
- App-Installer herunterladen (Link siehe oben) und installieren
- Dieser App Vertrauen und dann wieder zurücknehmen
- Konfiguration des Memor Scanners
- Einstellungen, ganz unten System, Scannersettings
- Wedge aus
- Prefix entfernen
Hinweis: Wenn die App sich nach dem ersten Scann automatisch beendet, so ist wahrscheinlich das Wedge-Interface des Scanners nicht deaktiviert.
- Einstellungen, ganz unten System, Scannersettings
Konfiguration
Beim ersten Start der App erscheint bereits der Anmeldebildschirm. Tippe hier auf  das Zahnrad um in die Konfiguration zu gelangen.
das Zahnrad um in die Konfiguration zu gelangen.
- Stelle hier die entsprechende Serveradresse deines Kieselstein ERP Servers ein.
- Für das Lesen eines NFC Tags aktiviere den NFC-Leser
- definiere danach die Anmelde Sprache (Logon Sprache) Diese siehst du auch in deinem Kieselstein ERP Client in der Titelleiste

- Gib danach den Mandanten ein, diesen siehst du ebenfalls in der Client Titelleiste
- wenn gewünscht kannst du noch ein Passwort definieren und
- die Sprache in der du deine Kieselstein ERP mobile App bedienen möchtest definieren. Es stehen derzeit die Sprache Englisch, drei Dialekte Deutsch, Italienisch und Polnisch zur Verfügung.
Tippe nun auf Speichern. Daran anschließend bitte die App beenden (wie auf deinem Gerät üblich) und neu starten.
Dass du eine WLan-Verbindung zu deinem Kieselstein ERP Server benötigst ist selbstverständlich. Sollte die Verbindung nicht funktionieren, so prüfe von deinem Gerät aus, ob du eine Verbindung zur RestAPI herstellen kannst.
Einloggen / Anmelden
Hier stehen zwei Möglichkeiten zur Verfügung
- mit Benutzernamen
achte auf GROSS-klein Schreibung und Passwort und tippe anschließend auf Ok.
Verwende hier den dir zugewiesenen Benutzernamen und das entsprechende Passwort.
Wichtig: Um einen Zugriff zu bekommen muss im Benutzermandant auch die RestAPI Systemrolle vergeben sein. - Alternativ kannst du durch Scannen
 des Login-Barcodes die Anmeldung deutlich vereinfachen. Beachte, dass dieser Barcode deine Identifikation darstellt und somit nicht in falsche Hände kommen sollte. Den Barcode bekommst du im Kieselstein ERP Client, Benutzer, dann auf den gewünschten Benutzer gehen und auf das Drucker-Symbol
des Login-Barcodes die Anmeldung deutlich vereinfachen. Beachte, dass dieser Barcode deine Identifikation darstellt und somit nicht in falsche Hände kommen sollte. Den Barcode bekommst du im Kieselstein ERP Client, Benutzer, dann auf den gewünschten Benutzer gehen und auf das Drucker-Symbol  klicken.
klicken.
Nun dein Passwort angeben, dieses wird nicht gespeichert und verschlüsselt im Barcode angegeben. Nun kannst du durch scannen dieses Barcodes dich ebenfalls am System anmelden.
Damit erscheint nun das Hauptmenü der mobilen Erfassung.

Connection Failure
Kommt bei der Anmeldung unmittelbar Connection Failure, so stimmt die IP Adresse nicht.
Eine weitere Fehlermöglichkeit ist, dass die Sprache nicht zu deiner Kieselstein ERP Installation passt. Stelle auch hier verfügbare Sprachen ein.

Ein weitere möglicher Fehler ist, wenn bei der sich anmeldenden Person keine Ausweisnummer im Personal / Detail hinterlegt ist. Dann kommt

Info: Die Ausweisnummer wird aus Gründen der Struktur der RestAPI in jedem Falle benötigt, auch wenn der Benutzer keine Zeiterfassung macht.
Es stehen folgende Funktionen zur Verfügung:
Abmelden
Mit Abmelden kommst du wieder zurück zur Anmeldung. Dies solltest du machen, wenn das Gerät nicht dein persönliches Gerät ist und es von den verschiedensten KollegInnen für unterschiedliche Aufgaben verwendet wird.
Inventur
Mit Tipp auf Inventur kommst du in das Auswahlmenü der Inventuren. Sollte die Fehlermeldung Sie verfügen nicht über die erforderlichen Benutzerrechte kommen, so diese bitte entsprechend nachtragen. Siehe
Inventur auswählen
Hier siehst du eine Liste der angelegten Inventuren, welche noch nicht abgeschlossen sind und auf deren Lager du entsprechende Zugriffsrechte hast.

Wähle nun die gewünschte Inventur aus, womit du in der Inventurerfassung bist.
Hier stehen folgende Möglichkeiten zur Verfügung.
Lagerort Scannen oder eingeben
Scanne durch tipp auf Scannen oder betätigen des Scannknopfes deines Memor den gewünschten Lagerplatz. Alternativ kannst du diesen auch eingeben.
Hinweis: Um einen Lagerplatz verwenden zu können muss dieser in der Liste der Lagerplätze eingetragen sein. Drucken der Lagerplätze siehe
Beachte: Ist ein Lagerplatz definiert, wird für jede Inventurbuchung dem gewählten Artikel dieser Lagferplatz zugeordnet. Dies solange bis ein anderer Lagerplatz definiert wird bzw. der Lagerplatz in der Erfassung wieder gelöscht (nicht definiert) wird.
Artikel scannen
Scanne nun den gewünschten Artikel. Je nach Inhalt des Barcodes werden Menge und Chargen- bzw. Seriennummer entsprechend aus der Etikette übernommen.
Es werden derzeit folgende Barcodekombinationen unterstützt:
| Barcodeinhalt | Bedeutung / Wirkung |
|---|---|
| Identnummer direkt als String | Artikel wird gewählt und angezeigt. Menge und ev. Chargennummer muss angegeben werden |
| $Iidentnummer|ChargebzwSnr | Identnummer mit nachfolgender Chargen bzw. Seriennummer. Die Menge muss eingegeben werden |
| VDA4992 | Identnummer, Menge, Chargen bzw. Seriennummer werden übernommen. Wenn die Menge geändert werden sollte, so tippe nach dem Scann auf das Plus rechts unten und gib die Menge ein und bestätigen mit Ok. |
| Ident<Tab>Menge<Tab>Charge@ | wie VDA4992 |
Wichtig: Üblicherweise, muss bei einer Inventur die Menge von der zählenden Person eingegeben werden. Wenn nun in deinen Barcodes, z.B. VDA4992 o.ä. die Menge bereits enthalten ist, so muss durch den Lagerbewirtschaftungsprozess sichergestellt sein, dass die Menge in der Verpackung(seinheit) mit der am Etikett / im Barcode angegebenen Menge übereinstimmt. Üblicherweise erkennt man das auch daran, dass bei Artikeln die mehrfach eingelagert wurden, zahlreiche Verpackungsetiketten, mit unterschiedlichen Mengen, übereinander kleben.
Daher übernehmen wir bei der Inventurerfassung die im Barcode enthaltenen Menge automatisch. Korrekturen können wie oben beschrieben vorgenommen werden.
Um die Inventurbuchung durchzuführen, tippst du auf Buchen. Wenn du die erfasste Menge bzw. Serien- oder Chargennummer geändert hast, kann es praktisch sein auch die Artikeletikette mit auszudrucken. Stelle dafür den Schalter auf ein (drucken). Beachte: Dies bleibt solange aktiv, bis du ihn deaktivierst bzw. die App neu startest.
Nach dem Buchen bist du wieder in der Erfassungsmaske und kannst mit dem nächsten Artikel deine Inventur fortsetzen.
Gibt es für den Artikel und gegebenenfalls die Serien / Chargennummer bereits einen Eintrag in der Inventurliste, so erscheint die Frage wie damit verfahren werden sollte.
- Hinzufügen: D.h. die Menge wird zur Buchung addiert
- Korrektur: D.h. die bestehende Inventurbuchung wird gelöscht und durch deine neue Buchung ersetzt
- Abbrechen: Kehrt zur Erfassungsmaske zurück
Artikeletikett mitdrucken
Um ein Artikeletikett ausdrucken zu können, muss der Arbeitsplatzdrucker entsprechend eingerichtet sein.
Rechte für die Inventur
- Rollenrechte
- erlaubte Lager für die Rolle
Fertigung
Los-Nummer eingeben, gerne auch nur einen Teil davon oder natürlich idealerweise scannen Nach der Eingabe erscheint eine Liste der gefundenen Losnummern. Das gewünschte Los durch antippen auswählen.
Losgröße ändern durch tippen auf den Stift
Los abliefern mit Seriennummer / Chargennummer (wenn erforderlich) durch jeweiliges antippen und Eingabe der Menge und gegebenfalls auch der Chargennummer (je nach Artikel) oder auch der Seriennummer.
Los auswählen
Eingabe der Losnummer bzw. eines Teiles davon.
Nach der Eingabe erscheint eine Liste der gefunden Lose. Wähle das für dich richtige Los durch antippen aus. Damit kommst du in die Bearbeitung des Loses mit verschiedenen Funktionen.
Durch Scannen der LosNummer ($L) gelangst du direkt in die Bearbeitung des Loses.
Los Abliefern

Zeiterfassung
- Kommt
- Geht
- Pause
- Saldo
- Anträge -> Urlaubsantrag, Zeitausgleichsantrag, Krankenstandsantrag in Halbtag oder Ganztag(en)
Urlaubsantrag erfassen
Einstellungen für den TC 21 C
-
rechts oben am Rahmen ist der Eintaster

-
wischen nach oben bringt alle Apps -> da findest du ach die Einstellungen
-
unter Display und dann erweitert
- Display automatisch drehen, abschalten
- Display automatisch abschalten -> auf 2Minuten / wie gewünscht einstellen
- Tipp auf den rechten Button, das gefüllte Rechteck, bringt alle aktiven Apps. hier nach rechts wischen bringt die Möglichkeit alle Apps zu schließen -> für den Restart der Kieselstein ERP App
Es gibt für den TC21C auf einen Pistolengriff, der sehr praktisch ist.
-
Einstellungen nach oben wischen, Einstellungen
- WLAN Netzwerk & Internet WLAN
Verbindungs / Ladekabel
USB-C erforderlich
Rechte
-
Für die Ablieferbuchungen
-
Welche Rechte muss der Benutzer für die Zeiterfassungsbuchungen haben?
7 - Nach der Installation
Arbeiten nach der Installation Ihres Kieselstein-ERP-Systems
Nach der Installation
Dinge die nach der erfolgreichen Installation deines Kieselstein ERP Systems zu machen sind. Hier findest du auch Infos, zu häufig auftretenden Fehlern, die einem einfach passieren.
a.) Kann mich anmelden, es lässt sich kein Modul öffnen
Beim Neustart eines Modules kommt ein schwerer Fehler. Dies Fehler kommt bei allen Modulen.
Voraussetzung: In deinem Kieselstein-Server-Verzeichnis sind alle drei Module deployed.
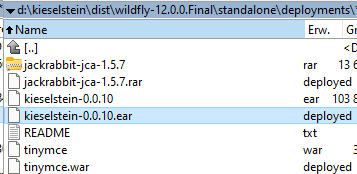
Der Client startet, du kannst dich mit Admin, admin anmelden. Es sind alle Module als Buttons in der Hauptmenüleiste sichtbar.

Beim Klick auf irgend ein Modul kommt:
Im Detail steht “nur”

Im Server.log (?:\kieselstein\dist\wildfly-12.0.0.Final\standalone\log\server.log) steht ziemlich weit unten (am Ende)
- Caused by: java.sql.SQLException: IJ031070: Transaction cannot proceed: STATUS_MARKED_ROLLBACK
- davor: Caused by: org.hibernate.exception.GenericJDBCException: could not prepare statement
- und einige weitere Error-Einträge davor:
Caused by: org.postgresql.util.PSQLException: FEHLER: Datum/Zeit-Feldwert ist außerhalb des gültigen Bereichs: »14/7/2023 11:51:58.567« Hinweis: Möglicherweise benötigen Sie eine andere »datestyle«-Einstellung.
Das bedeutet, dass der datestyle in der “?:\Program Files\PostgreSQL\14\data\postgresql.conf” falsch eingestellt ist. Es muss dieser auf:
datestyle = ‘iso, dmy’
eingestellt sein. D.h. die postgresql.conf richtigstellen und dann den postgresql neu starten. Natürlich vorher den wildfly stoppen und wenn der postgresQL läuft, den Wildfly wieder starten.
b.) Kann keine neuen Artikel anlegen
Du meldest dich an Kieselstein ERP an und die Benutzersprache ist nicht Deutsch Österreich, sondern irgend eine andere, z.B.  Deutsch Deutschland.
Deutsch Deutschland.
Nun ist im Artikelmodul kein Neu-Button sichtbar  .
.
Hintergrund: Der gewählte / definierte Mandant und damit die Mandantensprache, ist in einer anderen Kommunikationssprache als deine Clientkommunikationssprache. Info: Kieselstein ERP kommt default in de AT = Deutsch Österreich. D.h. du wechselst in das Modul System  , unterer Reiter Mandant
, unterer Reiter Mandant  , den vorgeschlagenen Mandanten verwenden und in den Reiter 2 Kopfdaten wechseln.
, den vorgeschlagenen Mandanten verwenden und in den Reiter 2 Kopfdaten wechseln.
Hier  auf ändern klicken und dann die Kommunikationssprache zu deiner gewünschten Mandantensprache ändern.
auf ändern klicken und dann die Kommunikationssprache zu deiner gewünschten Mandantensprache ändern.
Nun musst du noch deinen Kieselstein ERP Client neu starten.
Wichtig
Du solltest diese Änderung nur wenn unbedingt notwendig durchführen. Auf jeden Falle aber bevor Artikel, Textmodule, Grunddaten usw. erfasst wurden.Musst du dies bei bereits existierenden Daten machen, wende dich an einen Kieselstein ERP Betreuer.
c.) die HTML BDE geht nicht
Wenn man die HTML BDE aufruft, kommt im Browser eine Fehlermeldung:

Die bedeutet, dass der verdeckte Benutzer lpwebappzemecs in deiner Installation fehlt.
d.) In der Monatsabrechnung beginnt die Woche mit Sonntag

Ursache: Deine Installation läuft auf amerikanisch! Wir wollen aber Europa haben.
Man sieht das auch unter Hilfe, Info, Server - Java Info

Man sieht das auch im Server.log dass user.country = US eingetragen ist und dass user.language = en eingetragen ist. Es muss beides umgestellt werden. Wichtig auch: Bitte dies auch in der Datenbank Konfiguration richtigstellen. Idealwerweise läuft dein Server in Deutsch. Leider geht das nicht immer, weil z.B. die Konzernsprache englisch ist.
Prüfe auch die server.log. In den Starteinstellungen, muss:
- user.country = DE
- user.language = DE
- user.timezone = Europe/Berlin (gerne auch Wien oder Zürich) stehen.
Prüfe zusätzlich die Einstellungen deiner Datenbank in der postgresql.conf. Hier muss unter:
- log_timezone = ‘Europe/Berlin’
- timezone = ‘Europe/Berlin’ stehen.
Die Wildfly-Einstellungen kannst du in der
- ?:\kieselstein\dist\bin\launch-kieselstein-main-server.bat bzw. der .sh übersteuern.
Hier ergänzt du die MAIN_SERVER_OPTS hinten um -Duser.timezone=Europe/Berlin -Duser.country=DE -Duser.language=DE
Analog solltest du dann auch die Rest-Server Einstellungen analog anpassen. D.h. in der
- ?:\kieselstein\dist\bin\launch-kieselstein-rest-server.bat bzw. .sh
ergänzt du die set CATALINA_OPTS hinten um -Duser.timezone=Europe/Berlin -Duser.country=DE -Duser.language=DE
Danach Rest, Wildfly, Postgres stoppen und in umgekehrter Reihenfolge starten.
Es muss im Server.log die oben angeführten user…. stehen.
Im Client siehst du nun

Damit kommt auch die Monatsabrechnung und viele andere Auswertungen in der Wochenbetrachtung richtig. Also: 
————— old
Nach der Installation von Kieselstein ERP sollten Sie folgende Schritte durchführen / prüfen
- Ändern Sie das Passwort des Datenbank Administrators auf ein sicheres Passwort ab.
- Prüfen Sie die Einstellungen des Mandanten und korrigieren Sie diese gegebenenfalls
- Einrichten des Datenbank Backupscripts.
- Prüfen Sie, dass der Administrator das Recht PERS_SICHTBARKEIT_ALLE hat.
- Prüfen Sie, dass der Administrator das Recht PERS_ZEITEINGABE_NUR_BUCHEN nicht hat.
- Prüfen Sie, dass der Administrator Zugriff auf alle Läger hat.
[Beachten Sie bitte unbedingt die Anweisungen zum Update von Betriebssystem und Datenbank.](../Installation/Update_Einspielen.htm#Update von Betriebssystem und Datenbankversionen)
Wir empfehlen das Verzeichnis (…)/server/helium und das Verzeichnis der Datenbank vom Virenscanner auszuschließen um Geschwindigkeitseinbußen zu vermeiden.
Bitte richten Sie keine Freigaben für Verzeichnisse des Kieselstein ERP-Servers ein!
Eine Ausnahme ist hier das Verzeichnis der Reports, falls Sie selbst Reportanpassungen vornehmen.
Kieselstein ERP Administrator-Handbuch
Mit diesem Administrator Handbuch wollen wir Ihnen eine Hilfestellung zum “Am Laufen halten” Ihrer Kieselstein ERP Installation geben. Wie allgemein üblich, liegt die Verantwortung für die Sicherheit aller EDV Komponenten bei Ihnen, d.h. in der Verantwortung des Anwenders. Das betrifft sowohl die Zugriffssicherheit, als auch so Dinge wie Datensicherheit und Ähnliches. Etwaige Ansprüche aus Titeln dieser Art werden von uns grundsätzlich abgelehnt.
Was sollte der Kieselstein ERP Administrator regelmäßig prüfen?
-
Log-Files Wildfly checken, Anzahl der Exeptions ??? nur kritische suchen
-
Log-Files Kieselstein ERP durchsehen
-
Speicherbedarf des Wildfly (im Taskmanager) prüfen, ob er markant ansteigt. Ca. wöchentlich vergleich mit Startmemory
-
Regelmäßig Datenbanken sichern, täglich, stündlich
-
Datensicherung muss geprüft werden, sowohl Bandsicherung als auch DB Backup
-
Größen der DB Transaktion-Logs, Aktualität der Sicherung. Hier muss zusätzlich auf die Unterschiede zwischen MS-SQL, PostgresQL geachtet werden.
-
Prüfen des freien Platzes sowohl auf dem Laufwerk/Volume der Datenbank, also auch auf der Datenbanksicherung und dem JBoss Laufwerk. Hier muss ausreichend Platz für den Betrieb sein. Also jeweils mindestens 10GB freier Plattenplatz.
-
Admin muss die DBs einspielen / zurücksichern können
-
Kieselstein ERP Dienste müssen gestoppt und gestartet werden können, welche Dienste sind das?
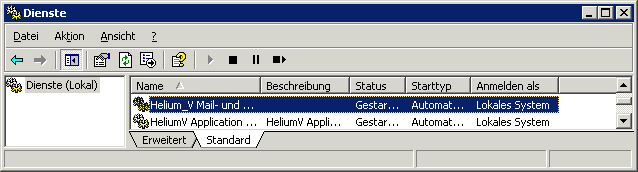
-
Starten des Wildfly, vor allem in Mehr-Rechner-Systemen und vor allem auch wenn die Datenbank deutlich länger zum Starten braucht als der JBoss. Sowohl unter Linux, MAC als auch unter Windows.
Was sollte der Kieselstein-ERP-Admin können?
- Selbständig Patches einspielen können, DB Updates einspielen.
- Client Installieren
- Wissen über die eigene EDV Infrastruktur, insbesondere Netzwerk-Auslastung und Kieselstein-ERP-Serverauslastung
- Servernamen und Ports, netstat -a muss ein Begriff sein
- Grundwissen über Reports, Baumstruktur, Reports neu Compilieren
- FAQ-Anwender muss beherrscht werden Login, Netzwerk, Passwort, ….
- Drucker installieren und einrichten, Druckformulare definieren Insbesondere das Thema Etiketten drucken.
- Prüfung der USV für jeden Server
- Server starten und vor allem kontrolliert herunterfahren
- Wildfly und Datenbankserver stoppen und starten
- zumindest monatliche Prüfung, dass die Backups zeitgerecht in der globalen Sicherung laden. Dass Sicherungsmedien physikalisch von der IT getrennt sind ist selbstverständlich. Auch selbstverständlich ist, dass jegliche Sicherung außer Haus gebracht wird und dass zumindest die Monatssicherungen auf der Bank o.ä. liegen.
Sollte der Backup-Job nicht laufen / Fehler melden, so finden Sie Fehlerhinweise in der Job-History.
Achten Sie auf ein tägliches Backup. Siehe dazu auch [Datenbankserver](../Installation/Datenbankserver.htm#Sicherung der Datenbank).
Herunterfahren des Linuxservers, bzw. Durchstarten
Um einen Linuxserver herunter zu fahren verbinden Sie sich bitte mit Putty auf den Server. Melden Sie sich mit root und dem bekannt gegebenen Passwort am Linux Server an. Nun geben Sie: shutdown -h now
zum Herunterfahren und ausschalten ein und
shutdown -r now
zum Reboot.
Startet nach dem Start des Linuxservers der Wildfly nicht, z.B. da die Datenbank erst reorganisiert werden musste und dadurch deutlich länger als vorgesehen dauerte, so muss der wildfly per Hand gestartet werden. Bitte wiederum mit Putty verbinden und
systemctl start wildfly
eingeben.
Warten Sie nun einige Minuten und verbinden Sie sich dann mit dem Kieselstein ERP Client auf den AplikationsserverJBoss. Können Sie trotzdem keine Verbindung aufbauen, so wenden Sie sich bitte an Ihren Betreuer.
Erstellen eines Datenbankbackups unter Linux
Verbinden Sie sich bitte mit Putty auf den Server. Geben Sie nun
pg_backupdb
ein. Damit wird ein aktuelles Backup der Datenbank erzeugt und üblicherweise auf /home/postgres geschrieben. Stellen Sie sicher, dass dieses Backup regelmäßig / täglich automatisch erzeugt wird und dass diese Dateien gesichert werden.
Sicherung der Anwenderreports
Stellen Sie sicher, dass auch Ihre Anwenderreports im täglichen Sicherungsjob mitgesichert werden. In den Reports steckt oft sehr viel Detailarbeit an der optimalen Umsetzung Ihrer Unternehmensprozesse. D.h. wenn diese verloren gingen, z.B. durch versehentliches Überschreiben, würde ein entsprechender Mehraufwand entstehen.
Auch diese Reports sollten in der täglichen Datensicherung enthalten sein.
Mein IT Betreuer möchte Zugriff
Nachdem man üblicherweise die Betreuung seiner IT-Systeme vertrauensvoll in die Hände eines fähigen Betreuers legt, wird diese, z.B. monatlich, sich um das Update deiner IT-Systeme kümmern. Nun will ein gute Betreuer natürlich nach allen Updates auch wissen, ob denn nun die Systeme auch wieder laufen.
Für Kieselstein stehen dafür zwei Funktionalitäten zur Verfügung:
- a.) es wird über die RestAPI ein Systemping auf den Server gemacht und geprüft ob eine entsprechende Antwort mit Versionsnummer und relativ aktueller Uhrzeit kommt
- b.) dein IT-Betreuer meldet sich über den Client an.
In zweiten Fall benötigt er zumindest soweit einen Account, dass auch die Anmeldung durchgeführt werden kann. D.h. du legst z.B. einen User IT-Service an und legst eine Rolle IT-Service an.
Der Trick liegt nun darin, dass du der Rolle keine Rechte gibst, somit kann sich dein Betreuer anmelden, sieht aber keine ERP Daten. Er kann damit feststellen, dass das gesamte Kieselstein ERP läuft, in diesem Falle ohne RestAPI.
Für den IT-Betreuer: Es kommt leider immer wieder mal vor, dass nach einem Systemupdate, der Datenbankserver deutlich länger als gewöhnlich benötigt und damit der Wildfly-Service auf dem das Kieselstein ERP aufbaut nicht richtig startet. Sollte dies der Fall sein, haben bisher folgende Schritte geholfen.
- Stopp des Rest-Server-Dienstes
- Stopp des Main-Server-Dienstes
- Neustart des Main-Server-Dienstes
- Neustart des Rest-Server-Dienstes
- ca. 5Minuten warten.
In jedem Falle so lange bis unter ../kieselstein/dist/wildfly-12.0.0.Final/standalone/deployments für alle drei Dateien .deployed oder .failed steht.
Bei deployed ist alles gut gegangen und du kannst dich anmelden, bei failed ist eventuell der Datenbankserver noch immer nicht gestartet. D.h. nun könntest du ev. ein Blick in das Log-File mit mehr Infos werfen, bzw. kann man gerne auch - die beiden Stopp durchführen
- danach den PostgresQL-Server-Dienst stoppen und neu starten (restart)
- danach die beiden Dienste (Main und RestAPI) wieder starten
Danach wie oben beschrieben auf deployed oder failed warten. Wenn erneut failed kommt, versuche dich über den PGAdmin anzumelden. Geht auch das nicht, hast du ein Problem mit der Datenbank. Das kann auch an zu wenig freiem Speicher liegen. Du solltest mehr als das doppelte der Größe deiner Datenbanken an freiem Festplatten-Speicher haben.
Eventuell hilft auch einfach das System / deinen Kieselstein ERP Server noch einmal durchzustarten.
Einrichten des EMail-Versandes
Damit der EMail Versand durch den IT-Betreuer eingerichtet werden kann, gib einfach obiger Rolle ein schreibendes Recht auf System. Wenn der EMail Versand dann eingerichtet ist, entfernst du dieses Recht wieder.
7.1 - Nach der Installation
Tipps und Tricks rund um dein Kieselstein ERP
Tipps und Tricks
Mit dieser Seite wollen wir zusätzliche Hilfestellung beim Einsatz von Kieselstein ERP leisten.
Kieselstein ERP Server ist nach IP Änderung nicht mehr erreichbar?
Wird die IP des Rechners mit dem Kieselstein ERP Server geändert, so muss der Kieselstein ERP Server neu gestartet werden.
Ich habe zwei Grundeinstellungen bei meinem Drucker, zwischen denen ich laufend hin- und herschalten muss
z.B. für den Ausdruck von firmeninternen und -externen Dokumenten (Papier mit Firmenlogo)
Bei lokalem Drucker:
- Start > Einstellungen > Drucker und Faxgeräte öffnen
- Drucker hinzufügen
- den selben Drucker auswählen, ihm einen anderen Namen zuweisen
- die Einstellungen ändern
- Ab jetzt werden “beide” Drucker in Kieselstein ERP zur Auswahl stehen
Bei einem Netzwerkdrucker muss er zuerst am Server eingerichtet werden:
- beim Server einen neuen lokalen Drucker anlegen, den gleichen Port, wie beim bestehenden Drucker auswählen
- Namen sprechend wählen
- richtig konfigurieren
- bei Workstations anlegen
- Drucker bei den Workstations einzeln konfigurieren
Es wurden Änderungen an den Fußzeilen vorgenommen, seither kommt nur mehr OK und die Fußzeilen fehlen.
Hier ist der Hintergrund, dass der für die Fußzeilen(=Subreport) im Ausgangsreport vorgesehene Platz zu gering ist. Üblicherweise ist der vorgesehene Platz nicht hoch genug.
Bestimmen Sie anhand des Fußzeilen-Subreports die erforderliche Höhe und korrigieren Sie den Ausgangsreport.
Hinweis: Achten Sie bei Subreports auch darauf, dass Sie die Höhe und Breite so wie auch im Ausgangsreport definieren. Hinweis: Es wird für die Fußzeilen nur mehr die Fuss.jrxml verwendet.
Siehe dazu unbedingt auch ..\wildfly-12.0.0.final\standalone\log\server.log
Ich will in den Auswahllisten auch die rundherum befindlichen Daten sehen
Manchmal ist es praktisch z.B. bei Rechnungen nicht nur die eine Rechnung Nr: 06/0000001 zu sehen, sondern auch die rundherum befindlichen Rechnungen. Um dies darzustellen gibt es einen Trick.
- Bestimmen Sie mit dem Direktfilter den gesuchten Datensatz. Z.B. Rechnung 06/0000001. Nun löschen Sie die Eingabe des Direktfilters wieder ohne Enter zu drücken. Nun wechseln Sie z.B. in die Kopfdaten oder in die Positionen und wechseln sofort wieder zurück in den Auswahlfilter. Durch die Logik, dass Kieselstein ERP auf dem ausgewählten Datensatz stehen bleibt, befinden Sie sich auf dem gewünschten Datensatz. Da aber die Filterbedingung inzwischen entfernt wurde, werden alle Rechnungen angezeigt.
Nach meinem Client-Update erhalte ich beim Start des Kieselstein ERP Clients ein Fehlermeldung
Could not find main class.
Dies bedeutet, dass auf Ihrem PC eine falsche Java-Version installiert ist. Siehe
Übersetzung von Texten
In Kieselstein ERP können alle Lables (Beschriftungen der Knöpfe, Eingabefelder usw.) dynamisch übersetzt werden. Bei der Verwendung einer PostgresQL Datenbank ist zu berücksichtigen, dass die eingetragenen C_TOKEN OHNE endende Leerstellen eingegeben werden.
Richtige Einstellung der Mehrwertsteuersätze für Deutschland
Da in Deutschland seit 1999 einige Mehrwertsteueränderungen waren, hier die richtige Einstellung der Mehrwertsteuersätze für allgemeine Waren. Eine Luxussteuer, wie sie in Österreich bekannt ist, gibt es in Deutschland derzeit nicht.

Markieren von mehreren Zeilen bei Auswahlmöglichkeiten
In den Modulen von Kieselstein ERP (z.B. Finanzbuchhaltung, Stücklistendruck, etc.) können Sie mehrere Zeilen markieren.
Gehen Sie dazu wie folgt vor:
Mit Klick auf eine Zeile markieren Sie diese.
Halten Sie die Strg-Taste gedrückt um weitere Zeilen zu markieren.
Bestätigen Sie die Auswahl mit Enter.
Sollten Sie mehrere Zeilen, die sich hintereinander befinden, markieren wollen, so gehen Sie wie folgt vor:
Markieren Sie die erste Zeile und halten die Shift (“Groß/Kleinschreib”)-Taste gedrückt, nun klicken Sie auf die letzte zu markierende Zeile.
Mit Drücken der Strg-Taste und A markieren Sie alle Zeilen. Zum Beispiel, wenn Sie durch Filter schon alle gewünschten Zeilen zur Auswahl stehen.
Um die gesamte Markierung wieder aufzuheben klicken Sie ohne Tastendruck auf eine andere Zeile.
Um nur eine Zeile wieder aus der Markierung zu nehmen, halten Sie die Strg-Taste gedrückt und klicken auf die Zeile bei der Sie die Markierung aufheben möchten.
Tipps zur Verwendung von Etikettendruckern
Für den Ausdruck von Etiketten empfehlen wir den Einsatz von Druckern der Firma Zebra. Für langjährigen Gebrauch ist die Serie Z4 bzw. S4 zu empfehlen.
Für manche Anwendungen mit sehr geringem Etiketten-Aufkommen werden auch die Drucker der Fa. Dymo eingesetzt. Dazu ist anzumerken, dass dies reine Einzelplatzdrucker sind. Die Einrichtung im Netzwerk ist aus unseren Erfahrungen nicht stabil. Dazu kommt, dass das Preis-Leistungsverhältnis nur für ein sehr geringes Etikettenaufkommen optimal ist. Ab ca. 1000 Etiketten im Jahr sind die kleinen Zebradrucker in den Gesamtkosten deutlich günstiger.
Da es natürlich auch zu den Zebradruckern immer wieder Fragen gibt, hier eine kleine Sammlung von Fragen und Antworten.
Der Drucker druckt ein Etikett und schiebt dann mehrere Etiketten nach
Führen Sie die Kalibrierung durch. Auf Windowsrechnern am einfachsten über die Eigenschaften des Druckers. Hier finden Sie in den Extras unter Aktion, Kalibrierung ausführen. Alternativ kann die Kalibrierung auch direkt am Drucker über das Druckmenü aufgerufen werden.
Der Drucker druckt ein Etikett und meldet dann “Paper out”
Stellen Sie sicher dass das Papier wie im Deckel des Druckers aufgezeichnet richtig eingelegt ist. Wichtig ist hier auch, dass die seitliche Papierführung sehr knapp aber leichtgängig eingestellt ist. Beachten Sie, dass sowohl die seitliche Führung der Etikettenrolle als auch die Führung des Papierbandes unmittelbar vor dem Thermotransferkopf möglichst exakt ist.
Vor dem Thermotransferkopf ist auf der Innenseite auch der Papiersensor angebracht. Dieser muss sauber sein.
Das Druckbild ist sehr schlecht
Führen Sie bitte die Kalibrierung durch.
Weitere allgemein Tipps zur Verwendung von Kieselstein ERP
Nach einem Stromausfall startet der Kieselstein ERP Server nicht mehr, es gibt unkontrollierte Fehler
Bei unkontrolliertem Abschalten des Kieselstein ERP Servers kann es vorkommen, dass temporäre Dateien, welche eventuell auch teilweise zerstört sein können, stehen bleiben.
Dies wirkt sich dann so aus, dass z.B. der Kieselstein ERP Server nicht mehr startet, bei manchen Auswertungen Class not found Exceptions bringt usw..
Wenn dies der Fall ist, so stoppen Sie den Kieselstein ERP Server
Nun löschen Sie aus dem Verzeichnis des Kieselstein ERP Servers die Unterverzeichnisse tmp und work.
Nun starten Sie den Kieselstein ERP Server wieder
Benötige ich für den Kieselstein ERP Server eine unterbrechungsfreie Stromversorgung?
Selbstverständlich.
Manche Anwender sind zwar der Meinung dass gespiegelte Platten, eine Datensicherung oder ähnliches ausreichen.
Wir weisen hier ausdrücklich darauf hin, dass jeder Kieselstein ERP Server und natürlich auch eventuell eigenständige Datenbankserver mit einer USV (unterbrechungsfreie Stromversorgung) ausgestattet sein müssen.
Wir können dazu von einem Anwender berichten, der ebenfalls der Meinung war, dass eine richtig installierte USV Luxus sei und bei dem ein Ausfall des Servers die Datenbank zerstört hat. Da dies am Abend eines intensiven Tages war, war es enorm wichtig, dass die Daten inkl. des Tages restauriert werden. Wir konnten die Daten mit einem Aufwand von ca. 3x24 Stunden zum Großteil retten. Wir waren jedoch ganz knapp daran aufzugeben.
Bedenken Sie die Kosten für einen derartigen Reparaturversuch und diese Kosten inkl. dem Datenverlust sind nicht versicherbar. Alleine um die Kosten für den Reparaturversuch bekommen Sie drei sehr gute unterbrechungsfreie Stromversorgungen.
Der Client meldet immer Zeitdifferenzen zum Server.
Stellen Sie sicher, dass Ihr Kieselstein ERP Server synchron zur internationalen Atomzeit ist. Wenden Sie sich dazu bitte gegebenenfalls an Ihren Kieselstein ERP Betreuer.
Nun empfiehlt es sich, dass jeder Client gegen den Kieselstein ERP Server synchronisiert wird. Siehe
Der Kieselstein ERP Client schließt sich immer wieder automatisch
Der Anwender hatte das Problem, dass immer bei einer längeren Pause, z.B. über Mittag, der Kieselstein ERP Client die Verbindung zum Kieselstein ERP Server verloren hat.
Mögliche Ursache I: Es geht die Netzwerkverbindung zwischen Client und Server verloren. Damit wird die Sitzungs-ID des Kieselstein ERP Clients ungültig, wodurch die Verbindung abbricht.
Was ist zu tun?
Schalten Sie bitte den Energiesparmodus in der Netzwerkkarte ab. Bitte wenden Sie sich an Ihren zuständigen EDV Betreuer der Ihre Geräte kennt.
Mögliche Ursache II: Im Bildschirmschoner war eingestellt, dass der Rechner nach einer gewissen Zeit in den Standbymodus wechselt. Auch dadurch geht die Netzwerkverbindung zwischen Client und Server verloren. Damit wird die Sitzungs-ID des Kieselstein ERP Clients ungültig, wodurch die Verbindung abbricht.
Weitere Möglichkeiten:
- Ein Bildschirmschoner der den Rechner in eine Art Ruhezustand versetzt.
- Die Netzwerkkarte ist defekt und fordert nach einiger Zeit immer wieder eine neue DHCP-Verbindung an
- Eventuell sollte auch im Ereignislog nachgesehen werden, ob hier weitere Hinweise auf Verbindungsabbrüche, Speicherfehler und ähnliches zu finden ist.
Wie kann die Geschwindigkeit von Kieselstein ERP bestimmt / gesteigert werden ?
Die Geschwindigkeit von Kieselstein ERP, aus der Sicht des Anwenders, der vor dem Client sitzt, hängt von verschiedenen Faktoren ab.
Wir haben versucht hier eine Aufstellung der Punkte zusammenzustellen mit denen eine Abschätzung der Geschwindigkeit insbesondere die Abschätzung von Geschwindigkeitssteigerungen als ungefährer Richtwert, der bitte völlig unverbindlich ist, möglich werden sollte.
-
Geschwindigkeit der Datenbank Diese hängt wiederum von:
- Geschwindigkeit der CPU -> steht eine eigene CPU nur für die Datenbank zur Verfügung
- Wieviel kann im Ram gepuffert werden -> das hängt wiederum vom
- verfügbaren Ram,
- der Größe der Transaktionen,
- der Menge an Schreiboperationen ab
- Die Geschwindigkeit der Platten. Dies ist laut unserer Erfahrung für die Datenbank der kritischste Punkt, Speicher ist meistens ausreichend vorhanden. Wir raten aktuell zum Einsatz von Server SSD Platten im entsprechenden Raid Verbund. Auch wenn das unter Umständen etwas Geld kostet, in Summe ist es die effizienteste Lösung.
-
Geschwindigkeit des Applications-Servers
- Geschwindigkeit der CPUs -> da der Application Server ein reines Java Programm ist, ist hier die Geschwindigkeit der CPUs ein wesentlicher Faktor. Mit dazu kommt, dass für die unterschiedlichen Aufgaben, weitere Threads gestartet werden. Diese können auf unterschiedlichen CPU-Kernen laufen. Man kann sich das so ähnlich vorstellen, dass jeder Client einen eigenen Thread bekommt.
Daher ist neben der reinen Taktzeit der CPUs auch die Frage: wieviele CPU Kerne stehen für den Application Server zur Verfügung wichtig.
Hier kommt mit dazu, steht die CPU nur für Kieselstein ERP zur Verfügung oder ist der Server mit anderen Aufgaben belastet. Wenn es um Geschwindigkeit geht, so stellen Sie sicher dass der Rechner ausschließlich für Kieselstein ERP (und den Datenbankserver) zur Verfügung steht.
Hier ist ein weiterer wichtiger Punkt die interne Struktur der Rechner / des Motherboards. Wir haben hier dramatische Geschwindigkeitsunterschiede bei den verschiedensten Herstellern festgestellt. - Größe des für den Applicationserver zur Verfügung stehenden Rams.
Je mehr Ram genutzt werden kann, desto weniger muss auf die Festplatte ausgelagert werden. Zuviel Ram würde jedoch bewirken, dass der Garbage Collector (das ist die Funktion die übriggebliebenen Speicher wieder hergibt und zyklisch in Java Programmen aufgerufen wird) seltener zusammen räumt, aber dafür zu lange dafür braucht. Hier kann durch Parametrierung des verwendeten Speichers (der wiederum unterschiedliche Arten hat) eine Optimierung vorgenommen werden. - Geschwindigkeit der Verbindung zwischen Applicationserver und Datenbankserver
Ist diese intern, also raschest möglich, oder geht sie über eine externe (Netzwerk-)Verbindung - Anzahl und Art und Weise bzw. Größe der laufenden Transaktionen.
D.h. einerseits,
- wie ist Kieselstein ERP programmiert
Bei der Programmierung sind wir von einer pesimistischen und transaktionsorientierten Betrachtung ausgegangen. Pesimistisch: D.h. wenn Sie einen Kunden ändern, so geht dies nur, wenn Sie den Kunden für sich selbst, für diesen einen Client sperren können.
Transaktionsorientiert: D.h. wenn ein Artikel vom Lager in den Lieferschein gebucht wird, so wird dies in einer Transaktion durchgeführt. Sollte es zu Abbrüchen, warum auch immer kommen, so ist dadurch der Zustand vor der Transaktion gegeben. Während der Dauer der Transaktion sind die Daten für die anderen Benutzer gesperrt. D.h. eine angepasste Arbeitsweise trägt zur Geschwindigkeit bei.
Im Zweifelsfalle haben wir die Verarbeitung in einer Transaktion gewählt. Unter Umständen kann bei manchen Aktionen dies entfernt werden.
Hier sind wir gerne bereit auf Ihre Vorschläge einzugehen und gegebenenfalls die Transaktions-Verarbeitungs-Art insoweit zu ändern, dass bei gleicher Sicherheit eine schnellere Verarbeitung erreicht wird. - wie arbeiten Sie mit Kieselstein ERP Werden z.B. am Morgen alle Auswertungen auf zig parallel laufenden Clients gestartet, oder werden umfangreiche Auswertungen / Berechnungen z.B. Bestellvorschlag, Stichtagsbetragungen des Lagers usw. hintereinander gestartet.
- wie ist Kieselstein ERP programmiert
- Was wir immer wieder feststellen mussten:
Es werden heutzutage immer mehr Server in virtuellen Umgebungen installiert. Testet man die Geschwindigkeit von Kieselstein ERP am Wochenende / Alleine, so ist diese vollkommen ausreichend. Im laufenden Betrieb während des Tages bricht die Performance deutlich ein.
Die Ursache liegt hier meist daran, dass:- Die IO Geschwindigkeit der Platten/des Plattencontrollers in der virtuellen Maschine völlig überlastet ist und “oben” ansteht. Bitte prüfen Sie dies mit einem geeigneten Programm, z.B. Performance Manager
- Die Belastung des Netzwerkcontrollers immer auf 100% ausgelastet ist und daher die Netzwerkpakete im Stau steckenbleiben. Bitte auch überprüfen.
- und natürlich, gerade für Datenbank intensive Aktionen, die Geschwindigkeit der Festplatten. Wir raten hier zur Verwendung von SSD Platten. Am Server im Raid 1, Raid10 Verbund. Und natürlich geeignete Serverplatten.
- Geschwindigkeit der CPUs -> da der Application Server ein reines Java Programm ist, ist hier die Geschwindigkeit der CPUs ein wesentlicher Faktor. Mit dazu kommt, dass für die unterschiedlichen Aufgaben, weitere Threads gestartet werden. Diese können auf unterschiedlichen CPU-Kernen laufen. Man kann sich das so ähnlich vorstellen, dass jeder Client einen eigenen Thread bekommt.
-
Geschwindigkeit des Clients Da auch der Kieselstein ERP Client ein reines Java Programm ist, gelten auch hier grundsätzlich die Forderungen an Java Programme.
- D.h. je schneller die CPU(s) desto schneller läuft der Client Teil.
- Und natürlich: Wieviel Speicher steht für den jeweiligen Kieselstein ERP Client zur Verfügung. Rechnen Sie hier mit einem Speicherbedarf je Kieselstein ERP Client von mindestens 256 MB (im Ram). Hier kommt noch der Bedarf für das Betriebssystem hinzu, welches üblicherweise nicht unter 512MB angesetzt werden kann (das war einmal zu Zeiten von WinXP. Rechne für Win11 mit mindestens 4GB Ram für das Betriebssystem!). D.h. wenn nur Betriebssystem und ein Kieselstein ERP Client laufen und sonst nichts (kein Word, kein Outlook) empfehlen wir mindestens 8GB Ram im Client Rechner zu haben.
- Werden mehrere Kieselstein ERP Clients parallel eingesetzt, so gehen Sie davon aus, dass für jeden Kieselstein ERP Client zusätzlich mindestens 256MB Ram zur Verfügung stehen sollten.
- Wichtig ist auch die Größe und die Auflösung des Bildschirms bzw. die verwendete Darstellungsgröße Ihres Kieselstein ERP Clients. Je größer die Bildschirmfläche des genutzten Kieselstein ERP Clients (Bitte in Pixel), desto mehr muss vom Layoutmanager verwaltet werden (trotz Vektor orientierten Grafikkarten). D.h. wenn rein die Mindestauflösung von 1024x768 verwendet wird ist der Client schneller und stabiler, als wenn sie in maximaler Fenstergröße auf einem 1920x1080 arbeiten.
- Entscheidender Faktor ist die Netzwerkanbindung zum Kieselstein ERP Server. Genauer gesagt die sogenannten Latenz-Zeiten. Je schneller die einzelne Paketanfrage vom Client zum Server und wieder zurück gelangt, desto schneller kann der Client reagieren. Hier ist die richtige Netzwerkparametrierung oft der entscheidende Faktor. Zusätzlich kommt hinzu, dass der eingesetzte Netzwerkswitch die geforderte Performance bringen muss. Setzen Sie manageable Switch ein um feststellen zu können, bei welchen Verbindungen Verbesserungsbedarf besteht.
- Auch der Client greift immer wieder auf die Festplatte zu. D.h. auch hier hat sich die Verwendung von SSD Platten sehr bewährt.
Wie hängt nun dies alles zusammen?
Im Client werden einerseits Daten des Servers abgefragt und angezeigt. Hier greift sowohl die Geschwindigkeit des Datenbankservers, des Applikationsservers, der Netzwerkverbindung und auch des Clients. Andererseits werden am Client Daten erfasst, von diesem vorverarbeitet und an den Server gesandt.
Ein Sonderfall sind Auswertungen wie z.B. der Druck einer Rechnung bzw. eine Lagerstandsliste zum Stichtag. Diese Journalauswertung wird komplett am Applikationsserver errechnet und grafisch im Speicher aufbereitet und erst danach an den Client zur Anzeige und zum Ausdruck gesandt. Daraus sieht man, dass auch hier alle drei (mit dem Netzwerk eigentlich vier) Komponenten im Spiel sind und zur gegebenen Geschwindigkeit beitragen.
Je mehr gleichzeitige Benutzer auf Kieselstein ERP arbeiten, desto mehr beeinflussen diese auch das Geschwindigkeitsverhalten.
Noch ein wichtiger Punkt:
Das “Abwürgen” des Clients, z.B. bei einer lange dauernden Lagerstandsberechnung, bricht den dadurch gestarteten Serverjob nicht ab. Der Server merkt erst am Ende der Berechnung, dass die Daten eigentlich nicht mehr benötigt werden. Lassen Sie daher den Client weiter laufen und starten Sie gegebenenfalls einen zweiten Client. Dieser wird bei gleichem Rechner und gleichem Benutzernamen nicht als zusätzlicher User gewertet.
Netzwerk-Geschwindigkeit messen
Um die Netzwerkgeschwindigkeit, genauer die Round Tripp Zeit zu messen, nutze aus dem Hauptmenü, Hilfe, Info. Hier wird in der letzten Zeile die sogenannte Roundtripp Zeit angezeigt. Also die Zeit die Netzwerktechnisch verbraucht wird, wenn der Client einen Request zum Server sendet, diese eine winzige Operation am Server macht und die Antwort wieder an den Client zurücksendet.

Typische Zeiten sind:
| Round-trip | Bemerkung |
|---|---|
| < 10ms | Internes Netzwerk, gutes Arbeiten möglich |
| < 25ms | WLan Anbindung, Arbeiten möglich |
| < 40ms | WLan Anbindung, Arbeiten bereits mühsam, aber für wenige Aktionen noch möglich |
| > 60ms | schlechte Anbindung, Arbeiten faktisch nicht mehr möglich |
Was kann eine Aufrüstung des Servers bringen
Die Geschwindigkeit von Kieselstein ERP, aus der Sicht des Anwenders, der vor dem Client sitzt, hängt von verschiedenen Faktoren ab. Als Einleitung siehe bitte obige Aufstellung.
Da immer wieder gefragt wird, was denn ein neuer Server bringen kann, hier eine kurze Zusammenfassung mit unverbindlichen Richtwerten / Faktoren wie sich eine Änderung gegenüber dem Verhalten auswirken kann:
- Mehreren CPU Kerne werden sich auswirken, insbesondere wenn gleichzeitig mehrere Benutzer darauf arbeiten. Ich würde (als Gefühl) einen Faktor von 0,5 je CPU Kern rechnen. Beispiel: altes System 2 Kerne, neues System 4Kerne, Steigerung ca. 50%
- Eine schnellere Taktfrequenz der CPU wird sich auswirken, ich würde auch hier von 0,5 ausgehen. CPU Takt alt: 2GHz, CPU Takt neu 3GHz, Steigerung auf ca. 30%
- Was sich deutlich auswirkt ist, wenn der Server NUR für Kieselstein ERP zur Verfügung steht.
- Schnelleren Platten z.B. SSD und bessere Hardwarestruktur (North & South-Bridge, Rambus usw.) tragen ebenfalls dazu bei
Eine Bremse für die gefühlte Geschwindigkeit können, besonders für die Anwender, “mangelnde” Speicher für die Anzahl Benutzer für gleichzeitige Nutzung auf Terminal Servern sein.
Wichtiger Hinweis:
Wir gehen hier von idealen Netzwerkbedingungen aus. Leider mussten wir in der Praxis immer wieder feststellen, dass viel Zeit und Geld in die Hardware investiert wird, aber grundsätzliche Dinge wie interne Domainstrukturen, ordentliche Netzwerkinfrastruktur, Netzwerkverkabelungen die tatsächlich vermessen sind, der Einsatz von Netzwerkswitch, die auch die geforderte Performance bringen hintangestellt wird. Denken Sie hier auch daran, dass manche Rechner ganz versteckt verseucht sein können. Dies finden Sie nur durch eine umfassende Netzwerkanalyse. Bemerkt wird es oft nur dadurch, dass die Mitarbeiter über ein langsames Verhalten klagen.
Was kann eine Aufrüstung des Clients bringen ?
Für eine Abschätzung gehen Sie einerseits bei der Steigerung der Verarbeitungsgeschwindigkeit für CPU und Speicher von den für Server angeführten Punkten aus.
GigaBit Netzwerke und Performance der Switch wirken sich eklatant in der gefühlten Verarbeitungsgeschwindigkeit aus.
Zu Geschwindigkeitsvergleichen generell.
Gehen Sie hier nur von reproduzierbaren Messergebnissen aus.
Als Mensch hat man sich an die bessere Geschwindigkeit sofort gewöhnt und nach dem dritten Aufruf z.B. einer Artikelliste ist es schon völlig normal, dass diese so schnell ist.
Wird ein Virenscanner benötigt?
Ja für den Client! Wir raten grundsätzlich dazu, auf jedem Client-Rechner einen geeigneten und aktuellsten Virenscanner einzusetzen. Sollte es auf Clientseite Geschwindigkeitsprobleme geben, so könnte das Kieselstein ERP Clientprogramm im Virenscanner ausgenommen werden.
Bitte nicht am Server! Am Server raten wir möglichst die gesamte Performance der Hardware für die Geschwindigkeit des Applikationsservers zu verwenden (und nicht um immer wieder die gleichen Dateien zu scannen).
Wie geht das, was ist nun wirklich einzustellen?
- Installieren Sie den Kieselstein ERP Server auf einem Linux-Rechner
- Stellen Sie in jedem Falle sicher, dass Ihr Kieselstein ERP Server in einer friendly Netzwerk-Umgebung läuft. D.h. dass er vor Angriffen jeglicher Art ausserhalb seiner selbst bestmöglich geschützt ist.
- Müssen, z.B. weil der Kieselstein ERP Server aus Firmenpolitik-Gründen auf einem Microsoft-Rechner läuft, Virenscanner und Firewalls installiert werden, so stellen Sie unbedingt sicher, dass die Zugriffe der Kieselstein ERP Clients nicht durch die Firewall z.B. des Virenscanners blockiert werden. Stellen Sie sicher, dass sowohl Datenbank als auch Application-Server beide mit den entsprechend temporären Dateien, von der ewigen Virenscannerei ausgeschlossen sind.
Müssen am Kieselstein ERP Server Verzeichnisse freigegeben werden?
Mit einer einzigen eventuellen Ausnahme, bitte in keinem Fall!
Bitte stellen Sie sicher, dass das Basis-Kieselstein ERP Verzeichnis nicht erreichbar ist. Es könnte bei Freigaben durch unsachgemäße Bedienung bzw. Versehen dazu kommen, dass die ganze Kieselstein ERP Server-Struktur gelöscht wird. Das einzige Verzeichnis, welches für geschulte Anwender eingerichtet werden darf ist ab dem Root-Verzeichnis der Reports.
Info: Für den Zugriff der Kieselstein ERP Clients ist keine wie immer geartete Freigabe erforderlich. Der Zugriff erfolgt ausschließlich über die Ports.
Sollte ich meinen Kieselstein ERP Client auf einem Netzwerklaufwerk installieren?
Technisch gesehen spricht nichts dagegen. Aus Gründen der Netzwerkbelastung raten wir in der Regel jedoch dazu, die Clients lokal zu installieren.
Kann ich das Layout speichern?
Ja. Siehe bitte
Energiesparen / Energiesparmodus
Bei manchen Anwendungen taucht die Frage auf, sollte man den Kieselstein ERP Server, welcher ja über das Wochenende nicht verwendet wird, abschalten, z.B. aus Energiespargründen.
Grundsätzlich ist der Gedanke des Energiesparens sehr zu begrüßen und wird von uns soweit möglich unterstützt. Es sind für das Abschalten des Servers jedoch zwei gegensätzliche Standpunkte zu berücksichtigen.
Der eine ist eben der des Energiesparens. Wenn man dies derzeit (April 2009) in Geldwert umrechnet, so bedeutet dass man durch das gezielte Abschalten eines Server einen Geldwertenvorteil von ca. 3,50 € pro Wochenende (2x24x0,2kWx0,37€) erzielt. Wenn wir nun davon ausgehen, dass zwischen Weihnachten und Neujahr die Server unabhängig von weiteren Überlegungen abgeschaltet werden, so muss von ca. 50Wochenenden pro Jahr ausgegangen werden, also von einem Geldwerten Vorteil von ca. 175,- €.
Dem stehen folgende nachteilige Punkte gegenüber:
- Bei Zeiterfassung oder Zutritt, insbesondere in Kombination mit Online Buchungen / Prüfungen muss der Server zum Buchungszeitpunkt zur Verfügung stehen.
- Der Start eines Server Systems dauert üblicherweise zwischen 10 bis 15 Minuten, manchmal auch deutlich länger.
- Durch das Abschalten des Server kühlen die Komponenten aus, die Versorgungsspannung bricht zusammen und so weiter. Beim Hochfahren werden die Komponenten wieder erhitzt, also gestresst, die internen Spannungsversorgungen müssen aufgebaut werden usw. Das bedeutet für die Komponenten des Servers ist das Aus- und Wieder-Einschalten Stress und verkürzt dadurch möglicherweise die Lebensdauer des Systems.
- Erhöhter organisatorischer Aufwand um die Sicherung des letzten Wochentages sicherzustellen.
- Jedes Server-System ist so ausgelegt, dass es sich über die Laufzeit der Anwendung, also des Servers optimiert und dadurch schneller wird. Diese Informationen gehen beim Serverneustart verloren.
- Manchmal sind mit den Servern auch Kommunikationsdienste wie EMail und Fax verbunden. Ist der Server abgeschaltet, stehen diese nicht zur Verfügung. Bitte klären Sie ob dies für Sie akzeptabel ist.
Hier kommt dazu, dass nach dem Hochfahren des Servers automatisch vom EMail-Dienst alle für Sie anstehenden EMails abgerufen werden. Das kann durchaus zu für einige Zeit verstopften Internetverbindungen führen, was wiederum bedeutet, dass Remotezugänge erst nach einiger Zeit, das können schon mal ein - zwei Stunden sein, wieder vernünftig zur Verfügung stehen. - Die möglicherweise nachteiligen Auswirkungen auf Rooting Tabellen in den Routern und weitere Nebeneffekte sollten ebenfalls überlegt werden.
- Bei Verwendung mehrerer Server wird das Starten deutlich komplexer und unter Umständen auch langwieriger.
- Oft wird diese Zeit von Ihrem Kieselstein ERP Betreuungsteam genutzt um Updates einzuspielen oder sonstige Arbeiten an Ihrem System durchzuführen. Auch diese Arbeiten sind nur bei eingeschaltetem Server möglich.
Das bedeutet für Sie, gerade das Wiedereinschalten des Servers bis er seinen normalen Betrieb erreicht hat, kann durchaus 30Minuten oder auch mehr in Anspruch nehmen. Es ist für die ersten 15Minuten ab dem Einschalten noch kein Arbeiten mit dem System möglich. Teilweise muss auch mit dem Start der Clients gewartet werden, bis die Server laufen. Gehen wir nun davon aus, dass wegen des Serverstarts am Montag ein Mitarbeiter regelmäßig um 20Minuten früher kommen muss, so sprechen wir hier von Kosten von 10,- € oder mehr pro Wochenende rein für Personalkosten. Die reduzierte Lebenserwartung des Server ist hier nicht berücksichtigt.
Bitte bedenken Sie diese Punkte bei einer allfälligen Entscheidung.
Sollte der Server im Energiesparmodus betrieben werden?
Eine ehrliche Antwort ist, nein. Es ist dies ein Server, welcher jederzeit zur Verfügung stehen sollte.
Selbstverständlich müssen wir unsere Mitwelt schützen soweit uns nur irgend möglich ist. D.h. für einen stabilen guten Betrieb sollte der Server durchaus so eingestellt werden, dass er so Resourcen schonend wie nur möglich betrieben wird. D.h. selbstverständlich sollte der Monitor echt abgeschaltet werden, es können die Festplatten nach kurzer Zeit (30Minuten) abgeschaltet werden. Allerdings hat uns die Praxis gezeigt, dass der Energiesparbetrieb von zwei Komponenten meist zu erheblichen Problemen im Betrieb führt. Deshalb raten wir dies Komponenten vom Energiesparmodus auszunehmen.
- CPU
Ein Heruntertakten der CPU hat bei einigen Installationen dazu geführt, dass bei wieder Aktivierung des vollen Betriebes die CPU nicht mehr mit voller Geschwindigkeit arbeitete und daher der Rechner neu gestartet werden musste, was gerade bei Serverbetrieb, aber auch bei Clients entsprechen lästig ist und die Verfügbarkeit von Kieselstein ERP enorm beeinträchtigt. - Netzwerkkarte
Wenn die Netzwerkkarte im Energiesparmodus ist, reagiert sie in den vielen Betriebssystemen oft nicht richtig. Das hat zur Folge, dass es den Anschein hat, dass der Kieselstein ERP Server nicht verfügbar ist. Geht man nun direkt zum Server und betätigt eine Taste so wird der Energiesparmodus der Netzwerkkarte beendet und alles verhält sich wieder normal. Sollten Sie dieses Verhalten feststellen, schalten Sie bitte den Energiesparmodus der Netzwerkkarte ab. Wir sind hier generell der Meinung, dass der geringe Mehrverbrauch an elektrischer Energie für die Netzwerkkarte, für den Serverbetrieb, in absolut keinen Verhältnis zu den unter Umständen erforderlichen Gesamtaufwänden steht.
Wie kann am MAC / OS X der Energiesparmodus abgeschaltet werden?
In einigen Installationen wird ein MAC / MAC Mini als Kieselstein ERP Server verwendet. Auch hier kommt es zu den oben beschriebenen Verhalten, weshalb auch am (Server) MAC der Energiesparmodus abgeschaltet werden sollte. Zusätzlich stellen Sie bitte bei echtem Serverbetrieb unter Optionen, nach Stromausfall automatisch neu starten ein, damit Ihr Kieselstein ERP Server möglichst immer zur Verfügung steht.
Kann Kieselstein ERP in einer DMZ betrieben werden
Ja selbstverständlich. Wichtigste Voraussetzung ist, dass das Tunneling in die DMZ vollständig ist.
So gibt es bei OpenVPN zwei Arten zu Tunneln. Verwenden Sie hier bitte die Einstellung TAP-Device.
Was ist bei einem Austausch des Kieselstein ERP Servers generell zu beachten?
Nach einigen Jahren des Betriebes ist es immer wieder erforderlich den Kieselstein ERP Server durch eine neue Hardware zu ersetzen. Da unser Ziel ist, auch hier einen möglichst zügigen und reibungslosen Übergang zu ermöglichen, eine kurze Beschreibung der Vorgehensweise. Bitte berücksichtigen Sie, dass EDV Betreuer die Übersiedelung Ihres Kieselstein ERP Servers immer wieder unterschätzen und leider davon ausgehen, dass es reicht einige Files zu kopieren.
Dem ist definitiv nicht so, es müssen der Datenbankserver und der Applikationsserver umgezogen / gesiedelt werden. Bei einer guten Vorbereitung kann die Umschaltung in kurzer Zeit durchgeführt werden. Unvorbereitete Umstellungen verursachen Stress und Kosten auf allen Seiten, der nicht notwendig ist. Gehen Sie daher bitte wie folgt vor:
- Reservieren Sie mindestens vier Wochen vor der Umstellung die Umstellungsunterstützung bei uns bzw. Ihrem Kieselstein ERP Betreuer.
- Planen Sie einen parallel Betrieb der alten und der neuen Hardware.
- Stellen Sie uns einen Fernwartungszugang auf die neue Hardware, parallel zum Zugang zur alten Hardware zur Verfügung.
- Planen Sie ausreichend Zeit (eine Kalenderwoche) für die Installation von Kieselstein ERP auf der neuen Hardware ein. Damit können wir in aller Ruhe die Installationsarbeiten durchführen. Da oft eine Menge Daten auf die neue Hardware zu transferieren ist, benötigt dies eine gewisse Dauer. Wenn das nebenher gemacht werden kann ist es entsprechend kostengünstiger.
- Testen Sie die Funktion von Kieselstein ERP komplett durch, bis hin zur Datensicherung, zum Zugriff auf die täglich erzeugten Sicherungsdateien durch Ihr Datensicherungssystem.
- Planen Sie den Tag der Umstellung, stimmen Sie den Termin mit uns und mit ihrem EDV-Verantwortlichen ab. Es müssen alle drei Beteiligten gut Verfügbar sein.
- Bei der Durchführung der Umstellung werden die Datenbanken vom Altsystem auf die neue Hardware eingespielt.
Es müssen die Clientzugriffe entsprechend umgestellt werden, oder es werden die Namen / Adressen zwischen Alt- und Neusystem entsprechend ausgetauscht. - Testen Sie den Zugriff aller Clients auf das neue System. Denken Sie auch an VPN Tunnel, Zeiterfassungsterminals, Browser-Terminals usw.
Bei Berücksichtigung dieser wenigen und einfachen Punkte kann die eigentliche Umstellung meist innerhalb weniger Stunden z.B. an einem Freitag Nachmittag oder sogar an einem Abend durchgeführt werden.
8 - laufende Pflege
Laufende Pflege deiner Kieselstein ERP Datenbank.
Wenn dein Kieselstein ERP schon einige Zeit im Einsatz ist, sollten regelmäßig (monatlich / halbjährlich) die Daten bereinigt werden.
Diese macht üblicherweise der Datenbank Administrator.
Die SQLs dafür sind:
-
delete from LP_ENTITYLOG where t_aendern < ‘2020-01-01 00:00:00’; – bitte mit Verstand einsetzen
-
delete from LP_VERSANDANHANG where VERSANDAUFTRAG_I_ID in (select I_ID from LP_VERSANDAUFTRAG where STATUS_C_NR = ‘Storniert’);
-
delete from LP_VERSANDAUFTRAG where STATUS_C_NR = ‘Storniert’; update LP_VERSANDAUFTRAG set O_MESSAGE = null, O_VERSANDINFO = null where STATUS_C_NR = ‘Erledigt’ and O_INHALT is null;
-
delete from LP_INSTALLER; – sollte in deiner KIESELSTEIN leer sein.
-
delete from LP_USERCOUNT where T_ZEITPUNKT < ‘01.01.2020 00:00:00’;
9 - Installation Reportgenerator(en)
Installationsbeschreibung zu den Reportgeneratoren, Tipps und Tricks, Return Variablen aus Subreport
Als Reportgeneratoren kommen zwei Versionen zum Einsatz. Einerseits der alte und eigentlich nur mit Java 7 Code lauffähige iReport und der Eclipse basierte Nachfolger Jasperstudio.
Achtung: Jasperstudio ist sehr Resourcen hungrig und leider nicht stabil (alle paar Stunden neu starten) auch das arbeiten mit Subreports ist im Studio nicht wirklich implementiert. Daher verwenden wir gerne auch noch den iReport 5.5.0, trotz des massiven Nachteils, dass er nur mit Java7 Code arbeiten kann.
Für JasperStudio 6.20.x oder höher, solltest du ausreichend RAM in deinem Rechner zur Verfügung haben. Unsere Erfahrung, ab 16 GB humpelt es, aber 32GB geht’s halbwegs. https://sourceforge.net/projects/jasperstudio/files/
Installation Jasperstudio
Hinweis: Wenn du Jasperstudio und iReport auf dem gleichen Rechner installieren möchtest, so zuerst Jasper Studio installieren und dann den iReport. Es sollten die jrxml mit dem iReport und die jasper mit dem Studio verlinkt sein.
Die Zusatz-Libs findest du hier und hier
Welcher Reportgenerator muss wo verwendet werden
In den neueren Reports werden auch HelperReport Methoden verwendet, welche nur mit Java 8 compiliert wurden. Wenn diese Methoden verwendet werden, kann nur mehr mit JasperStudio compiliert werden. D.h. wenn beim compilieren Fehlermeldungen wie z.B. 
aufscheinen, so muss mit Jasperstudio compiliert werden.
Debricated Java Funktionen
Ab der Version 1.0.0 ist auch der Serverteil des Kieselstein ERP Servers mit Java 11 kompiliert. Das kann durchaus bedeuten, dass Funktionen die in Java 7 zur Verfügung standen, in Java 8 bereits als debricated angekündigt waren, aber noch gingen und nun in Java 11 nicht mehr funktionieren.
So wurden gerade im Bereich der Kalender und Zeit Methoden massive Änderungen durchgeführt.
Tipps und Tricks für die Report gestaltenden Consultants
- Wenn man im Summary Band, den PSQL_Executer.subreport aufruft, muss danach noch ein Feld interpretiert werden, sonst macht der Report nichts. Das ist auch beim Jasper Studio so. Hängt ev. auch an den Eigenschaften in dem der Subreport definiert ist!
- Variablen werden erst nach dem ersten Detail berechnet. Das bedeutet, dass diese erst nach dem Durchlaufen des (ersten) Details einen gültigen Wert haben. Will man nun z.B. einen Gruppen-Header, der ja vor dem eigentlichen Detail kommt, mit einer Variablen andrucken oder eben nicht, so kann das nicht über Variablen gelöst werden, sondern muss direkt in die Print When expression des Gruppen-Headers eingetragen werden.
- Man kann dem Report auch generelle Bedingungen mitgeben (Siehe Eigenschaften des Reports) der ganze Zeilen herausfiltert.
Rückgabe von Werten aus den Subreports
Diese Funktion ist gegeben, aber in der Definition der Return-Variablen extrem kritisch.
Der wesentlichste Punkt ist, dass man akzeptieren muss, dass Subreports parallel zum Hauptreport ausgeführt werden. https://community.jaspersoft.com/wiki/how-sum-return-values-multiple-subreport-various-levels
Daher ist z.B. während der Ausführung eines Details (Detail-Bands mit Subreport) nicht sichergestellt, dass die Rückgabevariablen während des Rendering des Details-Bands bereits zur Verfügung stehen. Daher werden auch weiterrechnende Variablen, welche auf Rückgabewerten des Subreports aufbauen, nicht richtig bzw. zu spät interpretiert. Dieses “zu spät” ist offensichtlich auch von so Dingen wie Rechenlast abhängig.
Daher ist folgende Vorgehensweise offensichtlich erforderlich:
- Hauptreport
- Variable welche vom Subreport befüllt wird
- Calculation:
- System … System bedeutet, es wird der Wert dieser Variablen nicht durch den (Haupt-)Report verändert (aber durch die Parameter Übergabe des Subreports und seiner Calculation-Art)
- Resettype:
Resettype Bedeutung Hinweis Report für Gesamtsummen unten am Ende der Wert stimmt auch erst im Summary Group für Gesamtsummen am Ende der Gruppe der Wert stimmt erst im entsprechenden Group Footer None für Zeilensummen im weiteren Detail der Wert stimmt erst im, dem dem Subreport nachfolgenden Detail - Wichtig: Wenn Sie, wie z.B. oben drei verschiedene Zwischensummen benötigen, so müssen drei Variablen definiert werden, welche durch die Parameter-Rückgabefunktion des Subreports, in drei Definitionen, befüllt werden.
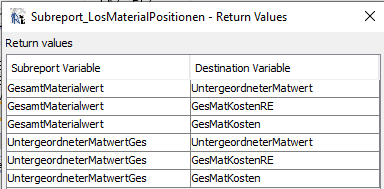
- Dass die Datentypen stimmen müssen, ist selbstverständlich.
- Calculation:
- Rückgabeparameter
- Wichtig: Wenn du im Rückgabeparameter Calculationtyp Sum o.ä. verwenden, so dürfen vom Subreport keine Nullwerte kommen!
- Interessant: Man kann durchaus zwei Variablen aus dem Subreport im Hauptreport zusammenzählen. D.h. es wird beim Rückgabeparameter die Destination Variable mehrfach angegeben und als Calculationsart SUM verwendet.
- Variable welche vom Subreport befüllt wird
Um die vom Subreport erhaltenen Werte zu sehen, muss nach dem Detailband in dem der Subreport ausgeführt wird, ein weiteres Detail-Band eingerichtet werden. In diesem stehen die Werte aus dem Rückgabeparameter, wenn der Resettype der Variablen auf none steht, zur Verfügung.
Sollte man am Ende des Reports einen Subreport mit Return Variable benötigen, so ist der Trick, dass man eine Gruppe mit Bedingung null macht. Diese so reihen, dass sie die äußerste Gruppe ist und den Subreport der die Returnvariable liefert im Gruppenfooter aufruft. Die Variable in der die Returnvariable eingefüllt wird muss auf diese Gruppe gestellt sein. Dann steht im Summary der Wert zur Verfügung. Gegebenenfalls schiebt man das Feld dann über den oberen Rand des Summary hinaus, damit die optische Position “richtig” ist.
Wenn Werte aus dem Subreport in das rufende Report Summary übergeben werden sollten, muss im Hauptreport der Resettype auf Report stehen.
Als Beispiel siehe: rech_warenausgangsjournal_materialeinsatz.jrxml
Trick
Will man im Summary einen Subreport mit Rückgabeparameter aufrufen, so gibt es ja nach dem Summary kein Band mehr, welches noch interpretiert wird. Daher macht man sich eine Gruppe mit Bedingung null und reiht diese als äußerste Gruppe. In den Group Footer gibt man seine Summary Variablen und den Aufruf des Subreports mit der Rückgabevariablen. Die Variable in die der Rückgabewert eingetragen = aufsummiert wird, hat als Rest-Group diese äußerste Gruppe. Im Summary, das ja dann danach kommt, kann man nun auf den Wert zugreifen. Gegebenenfalls schiebt man ein anzudruckendes Feld über den oberen Rand raus. Das ist nur mit der Tastatur möglich. In der Feldeingabe sind negative Werte für Top nicht zulässig. Gegebenenfalls auch direkt im XML ändern.
Welche Parameter stehen immer zur Verfügung
Generell gilt die Regel, dass Fields und Parameter nicht von anderen Reports übernommen werden dürfen. Davon ausgenommen sind folgende Parameter, welche immer an alle Reports angeliefert werden und daher jederzeit nachgetragen werden können.
| Parameter | Bedeutung | kopieren von |
|---|---|---|
| P_MANDANT_OBJ | Mandantenobjekt mit einer Vielzahl von weiteren Informationen über den Mandanten. Von Mandantennummer bis zum Länderkennzeichen | rech_rechnung.jrxml |
| P_SQLEXEC | Aufruf von Datenbank Querys aus dem Report heraus Muster für Variable siehe fert_fehlteile.jrxml, Variable: LosEndetermin |
rech_rechnung.jrxml |
| P_MODUL | interner Name des Moduls zur automatischen Findung der Subreports. Siehe dazu auch com.lp.util.HelperReport.getSubreportPath |
rech_rechnung.jrxml |
| P_LOGO_IMAGE | Logo aus dem Verzeichnis allgemein, also allgemein/logo.png | rech_rechnung.jrxml |
| P_LOGO_SUBREPORT | Pfad auf das Verzeichnis mit dem aktuell gültigen Firmenlogo mit allen Sprach und Mandanten Unterverzeichnissen | rech_rechnung.jrxml |
| P_MITLOGO | Sollte die Brief-Papier Information (Logo) gedruckt werden oder nicht | rech_rechnung.jrxml |
| REPORT_DIRECTORY | Pfad auf das Verzeichnis des aktuellen Reports um z.B. zu Subreports zu finden | rech_rechnung.jrxml |
| REPORT_ROOT_DIRECTORY | Pfad auf das Report-Root-Verzeichnis | rech_rechnung.jrxml |
Arbeiten mit iReport
Es darf ausschließlich iReport 5.5.0 verwendet werden. Alle anderen Versionen haben andere Bugs, die sich teilweise erst nach einiger Zeit zeigen.
Die Vorteile von iReport sind seine Geschwindigkeit und seine Übersichtlichkeit und dass man mit Subreports vernünftig arbeiten kann. Der wesentlichste Nachteil ist, dass iReport nur Java 7 kann und dass neuere Funktionen des Kieselstein-Clients nur mehr unter Java 8 zur Verfügung stehen.
[Einrichten von iReport]siehe
Arbeiten mit Jasper Studio
das liegt leider daran, dass der iReport nur Java 7 kann und der aktuelle Kieselstein Client unter Java 8 läuft.
Daher musste (aktuell ist das ein leider) auf den Nachfolger Jasperstudio 6.20.5 gewechselt werden (https://sourceforge.net/projects/jasperstudio/files/)
ACHTUNG: Jasperstudio 6.20.6 hat andere Property Definitionen (kann mit den Properties am Root nicht umgehen und hat weitere Bugs). Aktuell verwenden wir 6.20.5
Welche Reports müssen mit Jasper Studio bearbeitet werden
und welche können noch im iReport 5.5.0 bearbeitet werden
Arbeiten mit Formularen im iReport / JasperStudio
Report Editor
In Kieselstein ERP wird der iReport für das editieren der mitgelieferten Reports verwendet. Bitte achten Sie darauf die exakt richtige Version des iReports für die Bearbeitung der Formulare zu verwenden.
Nachfolgend Hinweise zu der Arbeitsweise und den Eigenheiten von iReport welche bei der Gestaltung der Reports beachtet werden sollten.
Hinweis: Für das Arbeiten mit iReport sollte mindestens eine Zwei-Tasten Maus zur Verfügung stehen. Eine Bearbeitung der Druckformulare mit nur eine Maustaste (MAC) ist nicht möglich.
Achtung: Wenn Sie Druckformulare selbst bearbeiten wollen, müssen Sie diese als Anwenderreport ablegen, da ansonsten die bearbeiteten Reports bei einem Update der Kieselstein ERP Version gelöscht werden!!
Die Hierachie der Verzeichnisstruktur können Sie unter “System -> Druckformulare” entnehmen.
Grundsätzliche Vorgangsweise beim Bearbeiten eines Reports
- Wenn nicht vorhanden, ein Verzeichnis für Anwenderreport anlegen, und Originalreports hineinkopieren. Bitte nur die tatsächlich benötigten Formulare einkopieren (und nicht einfach alle)
- Bei bereits vorhandenem Anwenderreport: Backup des Anwenderreport-Verzeichnis erstellen.
- Textfelder (Felder oder Parameter) im iReport anpassen.
- Änderung speichern und mit “Build - Compilieren”. Damit werden ihre Änderungen im laufenden System übernommen.
- Änderung mit Kieselstein ERP Client ansehen (den entsprechenden Report Druck aufrufen).
Feldnamen der Reports
Starten sie das Programm iReport. Gehen Sie auf “Datei -> Öffnen” und laden Sie den entsprechenden Report.
Unter “Ansicht -> Report Felder” und “Ansicht -> Report Parameter” finden Sie die Feldnamen und die Parameter Namen des Report.
“Felder” werden nur im Detailabschnitt des Reports verwendet. Für jede z.B Rechnungsposition wird eine Zeile im Detailabschnitt des Reports gedruckt. Zugriff auf ein Feld mit dem Namen Gesamtpreis ist über $F{Gesamtpreis} möglich.
“Parameter” sind nur einmal im ganzen Report vorhanden. Zugriff auf einen Parameter mit dem Namen P_KOPFTEXT ist über $P{P_KOPFTEXT} möglich.
Die Namen sind sprechend gewählt z.B im Anwenderreport der Rechnung unter: im Dateiverzeichnis Ihres Kieselstein ERP-Server (…) report/rechnung/anwender/rech_rechnung.jrxml finden Sie den Parameter P_KOPFTEXT, dieser enthält den Kopftext der Rechnung.
Wollen Sie z.B P_KOPFTEXT ändern gehen Sie im Report auf das entsprechende Feld, klicken mit der rechten Maustaste darauf und wählen “Eigenschaften”.
Unter “Textfeld -> Ausdruck für Textfeld” sehen Sie den Wert des Feldes. Wenn Sie unten Rechts auf “Expression Editor öffnen” klicken können Sie leicht verschiedene Felder oder Parameter auswählen und mit “Anwenden” übernehmen.
Unter “Allgemein -> Drucken wenn” wird angegeben, wann der Inhalt des Feldes angedruckt werden soll. Z.B new Boolean($F{Positionsart}.equals(“Stuecklistenpos”)) gibt an das das Feld nur gedruckt werden soll, wenn der Wert des Feldes Positionsart gleich “Stuecklistenpos” ist.
In Textfeld und Allgemein können Sie einige Konstrukte der Java Programmiersprache verwenden, die Datentypen der Felder und Parameter entsprechen Java Datentypen, weitere Informationen dazu finden Sie in der Java Dokumentation.
Wenn Sie Änderungen durchgeführt haben, gehen Sie auf “Build -> Compilieren” und ihre Änderungen werden im laufenden System übernommen.
Bevor Sie Änderungen machen empfehlen wir ein Backup des Reportverzeichnises zu erstellen, dadurch können fehlerhafte Änderungen zurückgenommen werden.
Weiterführende Dokumentation: Kostenpflichtige iReport Dokumentation zu beziehen unter: http://www.jasperforge.org/sf/wiki/do/viewPage/projects.ireport/wiki/HomePage iReport Hilfen und Dokumentation sind über Suchmaschine im Internet auffindbar
Dies ist nur eine Kurzanleitung wie iReport mit Kieselstein ERP Drucken eingesetzt werden kann und stellt keine ausführlich iReport Anleitung dar.
Breite der Barcodes:
Die Größe der gedruckten Barcodes richtet sich nach der Größe des definierten Feldes. Der Barcode wird so gedruckt, dass er sowohl von der Breite her, als auch von der Höhe her in die gedachte Umrahmung des Feldes passt. Zugleich wird das für den Barcode erforderliche Strich/Lücken Verhältnis beibehalten.
Anmerkung: Die Angabe erfolgt in 1/72" (Punkt bzw. Dezidot) Für die Umrechnung von Punkten auf mm verwenden Sie als Näherung bitte einen Multiplikator von 0,353. So ergeben 220 Punkte eine Breite von 77,66mm
In der Praxis hat sich bewährt, eine Höhe von 10mm (28Punkte) zu verwenden und die Breite ausreichend Breit zu definieren.
(100/72 = Inch * 25,4 = mm = 1/72*25,4 = 0,35277)
Bitte bedenken Sie, dass ein gut lesbarer Barcode zu anderen Strichen und Kanten einen ausreichenden Abstand haben muss. Als mindest Abstand ist die Breite zweier Zeichen zu empfehlen.
Bitte bedenken Sie auch, dass Barcodescanner üblicherweise eine maximale Erfassungsbreite von 70mm haben. D.h. mit einem Rand von wenigen Zeichen darf ein Barcode maximal 220Punkte breit sein.
Definition der Barcodetype
Die Definition der Barcodetype wird über den Formulareditor vorgenommen.
Üblicherweise wird der Code 128 verwendet. Bitte beachten Sie dazu auch Drucken von Barcodes.
Welche Parameter können wo verwendet werden.
Alle Parameter sind in den vordefinierten, von uns gepflegten Reports enthalten. Sollten Sie in Ihrem eigenen (Anwender) Report Parameter vermissen, so öffnen Sie bitte den original Report, gehen Sie auf Ansicht, Reportparameter. Hier sehen Sie nun alle definierten Felder, Variablen und Parameter. Sie können den gewünschten Parameter nun mit der rechten Maustaste kopieren, in Ihren eigenen Report wechseln und dort mit rechter Maustaste und Einfügen in Ihre Reportparameterliste aufnehmen.
ACHTUNG: Die Parameter werden nur innerhalb der gleichen Reports unterstützt. Das Einfügen ungültiger Parameter in einen Report kann zum Abbruch des Programms führen.
Drucken des Pageheaders aus dem Summary heraus, wenn im Summary ein Seitenumbruch ist.
Dies ist im Konzept des JasperReports nicht direkt vorgesehen. Als Work Around gehen Sie bitte wie folgt vor:
Definieren Sie eine neue Gruppe mit Namen Summary und als äußerste Gruppe definieren. D.h. sie muss in der Ansicht der Reportgruppen als erstes stehen. Die Summary-Gruppe mit Header Höhe 0 und Footer Höhe 78 anlegen. Die Felder aus dem original Summary in den Footer der (neuen) Summary-Gruppe (=SummaryFooter) verschieben.
Das original Summary auf Höhe 0 setzen.
Anmerkung: Sind in den Detailpositionen Felder mit Höhe 0 enthalten, werden sie beim Einfügen der neuen Gruppe nicht mitverschoben. Diese müssen manuell an die richtige Position gebracht werden, also an die richtigen Position in der richtigen Gruppe per Hand nachziehen. Beispiel: $F{Lerrzeile} im Detail des Rechnungsreports.
Dringende Empfehlung:
Bilder, die auf einem Report ausgedruckt werden sollten, dürfen im Dateinamen keine Leerzeichen enthalten. Der Dateiname sollte nur aus Kleinbuchstaben und _ bestehen. Er darf nur mit Buchstaben beginnen, im weiteren Namen dürfen Ziffern vorkommen, aber nicht an erster Stelle.
Definition der Abmessungen des Reports:
Die Abmessungen eines Reports / eines Formulares, z.B. einer Etiketten können im Reportgenerator unter Ansicht, Reporteigenschaften definiert werden. Definieren Sie hier Abmessungen, Ausrichtungen und Ränder. WICHTIG: Es hat sich bewährt, den Drucker immer im Porträt bzw. Hochformat zu definieren, auch wenn ein Formular verwendet wird, welches Breiter als Hoch ist. Um dies für die Reportvorlage richtig definieren zu können, müssen Sie die Höhe etwas höher als die Breite angeben. Die eigentliche Höhe des Etikettes definieren Sie dann mit der Höhe des Druckbereiches im jeweiligen Druck-Band (Detail, bzw. Title). Siehe dazu auch Etikettendruck.
Wenn Sie die Abmessungen des Reports verringern, so achten Sie bitte unbedingt darauf, dass auch die Höhen der einzelnen Elemente der Dokumentenstruktur (pageHeader, Detail usw.) angepasst werden müssen. Sind diese zu groß erhalten Sie Fehlermeldungen wie:
“1. The detail section, the page and column headers and footers and the margins do not fit the page height.”
Gehen Sie in diesem Falle in die verwendeten Elemente (Bands) und klicken Sie in die Band height. Geben Sie hier einen Wert ein der passt (mm -> DeziDots = mm/0,353) oder höher ist. Beim Verlassen des Feldes wird dieser Wert dann automatisch auf die richtige Höhe gesetzt.
Der Druck des Lieferscheins ist nach unten verschoben
Wenn man ein Feld mit einer bestimmten Höhe aus einem Report löscht, dann bleibt der dafür reservierte Platz bestehen, da dieser über die Bandbreite jenes Bandes bestimmt wird, in dem sich das Feld befindet. Um also den entstehenden Leerraum zu entfernen, der durch das Löschen des Feldes entsteht, muss man die Bandbreite entsprechend anpassen.
Beispiel: Es wird ein Feld “P_BEZEICHNUNG” mit Höhe 24 Pixel aus dem Band “Title” entfernt. In der Folge muss die Bandbreite des Bandes “Title” ebenfalls um 24 Pixel verringert werden.
Seit meiner letzten Änderungen werden die Texte mit Style Informationen gedruckt.
Wird in Ihrem Report ähnliches wie  angedruckt, so muss für das jeweilige Textfeld unter Font, Is styled text angehackt sein, damit die Formatierungsinformationen aus den Kommentardateien, aus den Textdateien usw. mit angedruckt werden.
angedruckt, so muss für das jeweilige Textfeld unter Font, Is styled text angehackt sein, damit die Formatierungsinformationen aus den Kommentardateien, aus den Textdateien usw. mit angedruckt werden.
Datenexport aus der Druckvorschau
Damit insbesondere Listen in anderen Programmen weiterverarbeitet werden können, wird dringend empfohlen die Spalten und Zeilen auszurichten. Nur so wird erreicht, dass auch in den exportierten Daten die Spalten untereinander stehen. Es reicht NICHT dies optisch auszurichten. Es muss dies mit den Jasper Werkzeugen, gleiche Breite UND links bzw. rechtsbündig ausgerichtet werden. Auch die Höhen müssen gleich und ausgerichtet sein.
Für den eigentlichen Export verwenden Sie am Besten den CSV Export.
Um die Datei in Excel zu übernehmen benennen Sie nun die Erweiterung der Datei bitte auf .TXT um. Nun mit Excel öffnen, Getrennte Breite, Trennzeichen Komma, Texterkennung “”, markieren Sie nun alle Spalten und Kennzeichnen Sie diese als Text und nun Fertigstellen.
So haben Sie die Daten optimiert importiert.
Drucken von mehrspaltigen Reports z.B. für Etiketten
Mit iReport können auch mehrspaltige Reports definiert werden, so wie sie z.B. für Laseretiketten für Laserdrucker (Zweckform, Herma, …) benötigt werden. Definieren Sie dazu die Eigenschaften des Reports unter Bearbeiten, Reporteigenschaften und klicken Sie auf den Reiter Spalten.  Geben Sie hier die gewünschte Anzahl der Spalten ein und definieren Sie auch den benötigten Zwischenraum.
Geben Sie hier die gewünschte Anzahl der Spalten ein und definieren Sie auch den benötigten Zwischenraum.
Im eigentliche Report finden Sie nun die angegebenen Spalten angezeigt. Definieren Sie nun die Inhalte der linken Spalte.

Wichtiger Hinweis:
Der Druck von Etiketten auf A4 Vorlagen ist nur für den Ausdruck von einmaligen “Listen” zu empfehlen. Gerade für die Schritte bei denen einzelne Etiketten benötigt werden, z.B. Wareneingang, werden Drucker benötigt, welche diese Einzelnen Etiketten auch ausdrucken können. Das mehrmalige Einlegen von A4-Etiketten hat schon so manchen Laserdrucker ruiniert. Auch diese Formulare sind nur für den einmaligen Durchlauf durch den Laserdrucker gedacht. Wir hatten immer wieder Fälle in denen einzelne Etiketten sich vom Trägermaterial gelöst haben und auf der Trommel des Druckers geklebt sind.
Praktische Kommandos, Bedingungen im iReport
Nachfolgend eine lose Sammlung praktischer Kommandos für den iReport.
-
Nur Drucken wenn String Leer ist:
new Boolean($F{F_POSITION}!=null&&$F{F_POSITION}.trim().length()>0)
F_POSITION ist hier der String -
new Boolean($F{F_POSITION}!=null&&$F{F_POSITION}.trim().length()>0 && $F{F_POSITIONSART}.equals(“Ident “))
Beachten Sie bitte, dass auch jeder Abschnitt seine Bedingung hat. So sind die Bedingungen für den PageHeader üblicherweise in diesem abgebildet (<$V{IS_CURRENT_PAGE_NOT_ONE}>) und nicht bei jedem einzelnen Feld.
Funktionen die von Kieselstein ERP zusätzlich für die Reportgestaltung im iReport verwendet werden können
Nachfolgend eine Sammlung ergänzender Funktionen für die Verwendung im iReport. Voraussetzung dafür ist, dass das lpclientpc.jar in den Classpath des iReport (siehe Extras, Optionen, Classpath) eingebunden ist.
Alle Funktionen sind in der Klasse com.lp.util.HelperReport gesammelt. Der Aufruf aus iReport entspricht immer dem Muster:
com.lp.util.HelperReport.FUNKTION
-
boolean pruefeObCode39Konform(String sString) Sind in dem String nur Code39 druckbare Zeichen enthalten
-
String wandleUmNachCode39(String input) Ersetzt Umlaute mit deren Entsprechung ohne Umlaut
-
Double time2Double(java.sql.Time time)
-
String ersetzeUmlaute(String input) Wandelt Ö auf Oe usw.
-
String wandleUmNachCode128(String input)
-
String ersetzeUmlauteUndSchneideAb(String input,int maxStellen)
-
String getWochentag(java.util.Locale locale, java.sql.Timestamp tDatum) Liefert den Wochentagsnamen in der jeweiligen Sprache
-
String ganzzahligerBetragInWorten(Integer betrag)
-
Integer getCalendarOfTimestamp(java.sql.Timestamp tTimestamp, Locale locale)
-
String getMonatVonJahrUndWoche(Integer iJahr, Integer iWoche, Locale locale) Liefert den Monatsnamen eines Jahres und einer Kalenderwoche
-
Integer getCalendarWeekOfDate(Date date)
-
Integer getCalendarWeekOfDate(String sDate, Locale locale)
-
Boolean pruefeEndsumme(BigDecimal bdReportNettoValue, BigDecimal bdHvValue, Double dAbweichung, String listeMwstsaetze, Locale reportLocale)
-
String laenderartZweierLaender(String lkzKunde, String lkzBasis, String uidNummer, java.sql.Timestamp tsEUMitglied) Ermittelt die Länderart des Kunden in Bezug auf die Basis (= Mandant)
-
String entferneStyleInformation(String) Entfernt die in den Texteingaben enthaltenen Styleinformationen wis bold usw.
-
int berechneModulo10(String nummer) ’nummer’ darf nur Ziffern zwischen 0 und 9 enthalten!
-
String berechneModulo10Str(String nummer)
-
Time double2Time(Number zahl)
-
Konvertierung eines Strings in einen anderen Datentyp, ohne Fehlermeldung (Exception): BigDecimal toBigDecimal(String bigDecimal) ; // wandelt nach BigDecimal, in Locale “deAT” BigDecimal toBigDecimal(String bigDecimal, Locale locale) ; // wandelt nach BigDecimal in angegebener Locale
BigInteger toBigInteger(String bigInteger) ; // wandelt nach BigInteger mit Radix 10 (Dezimalzahlen) BigInteger toBigInteger(String bigInteger, int radix) ; wandelt nach BigInteger mit angegebenen Radix (oktal, hex, ….)
Integer toInteger(String integer) ; // wandelt nach Integer
All diesen Funktionen gemeinsam: Bei einem fehlerhaften Format, oder auch null als Parameter wird null anstatt einer Exception zurückgeliefert. Dies muss im Report entsprechend ausgewertet werden. Anwendungsbeispiele: HelperReport.toBigDecimal(“25'100,12”, new Locale(“de”, “CH”)) ; // deCH HelperReport.toBigDecimal(“25.100,12”) ; // deAT HelperReport.toBigDecimal("-25'987.65”) ;
Bei der Komplierung kommt eine ClassNotFoundException Fehlermeldung
Diese Meldung bedeutet, dass der iReport Compiler eine Java Klasse nicht findet. Um die Formulare von Kieselstein ERP mit der gewünschten Funktionalität auszustatten, werden viele Klassen direkt von Kieselstein ERP zur Verfügung gestellt. Dafür muss der Pfad auf den Kieselstein ERP Client mit in den ClassPath des iReport eingebunden werden.
Sie finden dies unter Extras, Optionen, Classpath. Geben Sie hier den Pfad auf den aktuellen Kieselstein ERP Client an.
Bitte beachten Sie, dass in der Regel der Kieselstein ERP Client unter … zu finden ist.
Fehlermeldung unsupported version
Kommt beim Compilieren eine Fehlermeldung ähnlich java.lang.UnsupportedClassVersionError: com/lp/util/report/PositionRpt : Unsupported major.minor version 51.0 so bedeutet dies, dass iReport nicht unter Java 7 ausgeführt wird.
Beachten Sie bitte in jedem Falle, dass Sie iReport nur unter Java 7 genutzt werden kann und dass Sie dafür den Client für Java 7 benötigen. Die Clients für Wildfly sind für Java 8 kompiliert. Gegebenenfalls bitten Sie Ihren Kieselstein ERP Betreuer Ihnen einen passenden Client zur Verfügung zu stellen. Gegebenenfalls siehe auch im iReport, Hilfe, Info.
Wichtiger Hinweis:
in den Reports können nur die fields und parameter verwendet werden, welche vom Kieselstein ERP-Server auch angeliefert werden. D.h. wenn Felder bzw. Parameter aus anderen Reports kopiert werden, so haben diese normalerweise nicht die gewünschte Wirkung. Hintergrund: Diese Felder werden über sogenannte Call-Backs vom Application-Server befüllt und wenn diese nicht vorgesehen sind, sind sie eben NULL.
Ausnahmen: Es gibt Parameter die in allen Reports zur Verfügung stehen, aber nicht in allen Reports ausgeführt sind. Diese sind:
- Mandanten-obj
- psql-executer
- logo….
- report_directory
- report_root_directory Diese Parameter können jederzeit in einen (Haupt-)Report von einem anderen Report einkopiert werden. Für die Verwendung in Subreports müssen diese selbstverständlich durchgereicht werden.
Was sind Styles?
In iReport können Styles folgendermaßen angelegt werden: Style Bibliothek -> Neuer Style (Symbol). Daraufhin öffnet sich ein Popup, in welchem der neue Style zu definieren ist. Bei Style Name ist ein Name für den aktuellen Style anzugeben, damit man beim Anlegen mehrerer Styles den Überblick behalten kann. Der Standardstyle beinhaltet alle Formatierungen, die ein Feld standardmäßig haben soll, z.B. ist das häufig schwarzer Vordergrund auf weißem Hintergrund. Mit dem Button ‘Hinzufügen’ kann man eine neue Bedingung erstellen, an welche andere Formatierungen geknüpft sind. Z.B. legt man als Bedingung new Boolean ($F{Projektbezeichnung}.contains(“Fehler”)) fest, was bedeutet, dass wenn in dem Feld ‘Projektbezeichnung’ das Wort ‘Fehler’ vorkommt, der definierte Style angewendet wird.
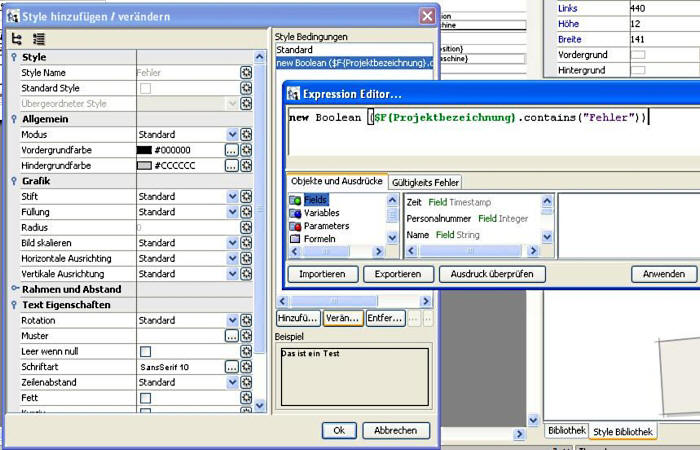
Anwendung des definierten Styles im Report:
Man wählt in ein oder mehreren Reportfeld-Eigenschaften im Register ‘Allgemein’ unter ‘Style’ den zuvor definierten Style aus.
Worauf ist bei Verwendung von Styles speziell zu achten?
A: Damit die definierten Styles auch angezeigt werden, gibt es folgende Punkte zu beachten:
-
Beim Style in der Style Bibliothek:
-
Es sollten unter ‘Allgemein’ Vorder-, Hintergrundfarbe und Modus definiert sein (Modus nicht undurchsichtig, Standard wäre am Besten)
-
Beim Standardstyle soll ein aussagekräftiger Name definiert werden
-
-
Beim Report-Feld, auf das der Style angewendet wird (Feld-Eigenschaften):
-
Im Register ‘Allgemein’ ist beim Style der anzuwendende Style auszuwählen
-
Im Register ‘Allgemein’ ist das Feld auf NICHT transparent zu setzen
-
Im Register ‘Alle’ sind die Vorder- und die Hintergrundfarbe zu löschen (Bei Vorder- und Hintergrund rechts daneben das Kreis-Symbol anklicken)
-

Meine im iReport definierten Feldgrößen passen nicht zu den Ausdrucken
Vermutlich sind die für den Kieselstein ERP Server verfügbaren Fonts (Schriften) nicht identisch mit den von Ihnen beim Design der Reports verwendeten Schriftvorlagen. Gerade bei Linux und MAC-Servern müssen diese aus Lizenzgründen extra installiert werden. Siehe dazu bitte auch auf Ihrer Installations-CD unter Tools/Linux/Fonts.
Bei den Adressetiketten werden nur leere Etiketten gedruckt.
Wie bereits an anderer Stelle angeführt, ist das Ausdrucken von Etiketten eine eigene Wissenschaft, die manchmal unterschätzt wird. Die Thematik ist hier vor allem, dass Druckertreiber nicht immer 100%ig richtig implementiert sind und auch Aufgrund der vielen zu treffenden Einstellungen manchmal etwas vergessen wird.
Hier nun eine lose ergänzte Sammlung von Punkten / Empfehlungen, die für das Etikettendrucken erforderlich sind, die getestet werden sollten, wenn der Etikettendruck nicht wie gewünscht funktioniert:
-
Stellen Sie sicher, dass Sie auf das Etikett / den Etikettendrucker eine Testseite ausdrucken können.
-
Versuchen Sie das Etikett aus einem Textverarbeitungsprogramm zu drucken.
-
Spannen Sie ein großes Blatt Papier ein, wenn möglich und drucken Sie auf dieses.
-
Etiketten Orientierung: Etiketten werden in aller Regel im iReport so definiert, dass sie für den Designer lesbar sind. Oft ist hier die Etikettenbreite größer als die Etikettenhöhe. Dadurch wird im iReport bei Änderungen der Abmessungen die Orientierung automatisch auf Querformat umgeschaltet, was von der Druckrichtung her falsch ist. Um dies zu korrigieren muss in das jrxml File des Reports eingegriffen werden. Ändern Sie hier bei Orientation den Wert von Landscape auf Portrait ab. Speicher Sie die Datei, gehen Sie wieder in den iReport und kompilieren sie die Datei erneut. Nun kann geduckt werden.
-
Ein weißes Blatt, eine leere Etikette wird gedruckt. Um festzustellen woran das Problem liegen könnte, vergrößern Sie das Etikettenformular entsprechend und stellen Sie die Nutzdaten einfach in die Mitte. In aller Regel erhält man nun Informationen wo den eigentlich hingedruckt wird.
Oft ist es auch so, dass die Orientation (siehe oben), der Auslöser für dieses Verhalten ist. -
Bei Verwendung von dedizierten Etikettendruckern, stellen Sie unbedingt in den Druckereigenschaften des Etikettendruckers das eingelegte Etikett ein.
-
Bei Verwendung von CUPS Treibern achten Sie unbedingt darauf, dass die Etikettendefinition im iReport in das Etikett passt. Schon geringe Abweichungen (1 Pixel) führen dazu dass das Etikette gedreht oder gar nicht gedruckt wird.
Ausdrucken aller Bearbeiter Daten
Gerade in Angeboten, aber auch für eine gute Kommunikation mit Ihren Partnern (Kunden und Lieferanten) ist es erwünscht, nicht nur den Namen des Ansprechpartners sondern auch seine ausführlichen Kontaktdaten mit anzudrucken. Dafür steht in den öffentlichen Reportvorlagen eine sogenannte Objectvariable zur Verfügung.
Diese lautet in allen Reports: <P_BEARBEITER>
Um nun z.B. die EMai-Adresses des Bearbeiters anzudrucken muss folgendes Konstrukt unter Textfeld eingegeben werden: <$P{P_BEARBEITER}.getSEmail()>
Wichtig: Damit diese Erweiterungen im iReport kompiliert werden können, muss der Klassenpfad auf das kieselstein-ui-swing.jar / lpclientpc.jar gesetzt werden, welches du üblicherweise unter c:\kieselstein\client\lib\kieselstein-ui-swing.jar findest
Es stehen folgende Werte zur Verfügung:
| Typ | Methode |
|---|---|
| java.lang.String | getSEmail() |
| java.lang.String | getSMobil() |
| java.lang.String | getSNachname() |
| java.lang.String | getSTelefonDWFirma() |
| java.lang.String | getSTelefonFirma() |
| java.lang.String | getSTitel() |
| java.lang.String | getSVorname() |
Ausdrucken aller Positionsinhalte als einzelne Felder
Für manche offizielle Formularvorlagen ist es erwünscht, dass, insbesondere zu Positionierungszwecken die Felder z.B. der Artikelbezeichnungen als jeweils einzelnes Datenfeld zur Verfügung stehen. Um diese Forderung zu erfüllen wird an einige offizielle Reportvorlagen die Objectvariable <F_POSITIONSOBJEKT> übergeben. Um nun z.B. nur die Artikelnummer mithilfe dieser Objectvariabeln zu drucken muss folgendes Konstrukt unter Textfeld eingegeben werden: $F{F_POSITIONSOBJEKT}.getSIdent()
Es stehen in den unten angeführten Vorlagen folgende Variablen zur Verfügung.
| Typ | Aufruf | AF | BS | AG | AB | LS | RE | GS |
|---|---|---|---|---|---|---|---|---|
| String | getSIdent() | |||||||
| String | getSBezeichnung() | |||||||
| String | getSZusatzbezeichnung() | |||||||
| String | getSZusatzbezeichnung2() | |||||||
| String | getSKurzbezeichnung() | |||||||
| String | getSPositionsartCNr() | |||||||
| String | getSText() | |||||||
| BigDecimal | getBdUmrechnungsfaktor() | |||||||
| String | getSEinheitBestellung() | |||||||
| String | getSArtikelgruppe() | |||||||
| String | getSArtikelklasse() | |||||||
| String | getSArtikelreferenznr() | |||||||
| String | getSArtikelmaterial() | |||||||
| Float | getFArtikelmaterialgewicht() | |||||||
| String | getSVerkaufsEANNr() | |||||||
| String | getSWarenverkehrsnr() | |||||||
| String | getSUrsprungsland() | |||||||
| Float | getFArtikelgewicht() |
Bitte beachten Sie auch die unter Ergebnisklasse Textfeld erforderliche Typ-Definition.
eine andere Sortierung als ursprünglich gewünscht
Um dies zu erreichen fügt man nach der Definition der FieldNames die sogenannten sortField hinzu. Damit werden die Reports in der angegebenen Reihenfolge sortiert.
z.B.: <sortField name=“Lagerort”/>
ACHTUNG: Bei Änderungen direkt im XML, welche vom Designer nicht unterstützt werden, direkt aus dem XML heraus speichern und dann erst in den Designer zurückwechseln. XML Kommentar wird NICHT unterstützt, d.h. wieder herausgelöscht.
Das kann man natürlich auch für die Sortierung aus dem Sort-Field nutzen.
9.1 - Installation Jasperstudio
Einrichten des Jasperstudio
Für das Arbeiten mit Jasperstudio ist unbedingt folgendes zu beachten:
Ein Arbeiten mit Jasperstudio unter 16GB Ram ist faktisch unmöglich. Auch muss von einer entsprechend leistungsfähigen CPU ausgegangen werden. Idealerweise sind sowohl Programme als auch Reports auf einer SSD Platte verfügbar.
Automatisches Build abschalten
Es ist leider so, dass dieses Build in der Regel die erzeugten Jasper-Dateien zerstört. Daher muss dies unbedingt abgeschaltet werden, bevor die Reports, also die Projekte zugeordnet werden. Es sollte auch das automatische sichern der Report Sources vor dem build / compilieren eingeschaltet sein.
Hauptmenüleiste, Window, Preferences
General, Workspace, Build
Kompatibilität zu iReport 5.5.0
Da das Arbeiten, gerade für komplexere Reports mit Subreports und Rückgabewerten im iReport deutlich einfacher ist, ist es sehr praktisch, wenn die XML-Sourcen der Reports kompatibel zu JasperReport 5.5.0 abgespeichert werden. Es steht damit zwar das automatische Fontsizing zur Anpassung an den verfügbaren Platz NICHT zur Verfügung, aber da Schriften unter 6Punkt sowieso als nicht geschrieben gelten, benötige ich diese Funktion nicht.
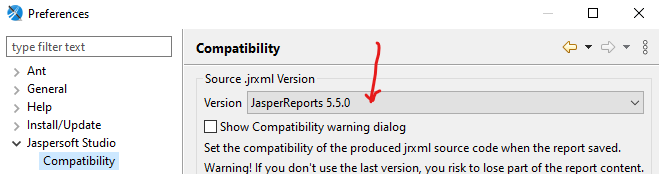
Kennzeichnen für Jasperstudio wird instabil
Wenn das automatische Sichern vor dem Compilieren nicht mehr geht, empfiehlt sich, das Jasper Studio neu zu starten, damit nicht deine Editierarbeit vergebens war.
Installation
Report Backup
Wir raten dringend, vor der Installation ein Backup des gesamten Report-Verzeichnisses zu machen. Es ist leider immer wieder vorgekommen, dass durch die Installation die Jasper-Dateien, die eigentlich ausführbaren Dateien sind, zerstört wurden.Bitte denke auch daran, dass die Workspace-Einstellungen Benutzer-Werte sind. Also, auch wenn der gleichen Rechner/Server genutzt wird. In dem Moment wo du dich mit einem anderen Benutzer als der einrichtende anmeldest, bitte die Einstellungen prüfen.
herunterladen
https://sourceforge.net/projects/jasperstudio/files/latest/download
Achte darauf immer nur eine Version auf dem Rechner installiert zu haben. Die Version vom 29.5.2023, 6.20.5 scheint etwas weniger Resourcen hungrig zu sein.
ACHTUNG: Jasperstudio 6.20.6 hat andere Property Definitionen (kann mit den Properties am Root nicht umgehen und hat weitere Bugs). Aktuell verwenden wir 6.20.5
2024-03-25 / 6.21.2
Es stehen die Vorgängerversionen nicht mehr zur Verfügung. JasperSoft stellt aktuell die 6.21.2 zur Verfügung.
ACHTUNG:
Diese kann derzeit mit Kieselstein ERP nicht nicht verwendet werden. Versuche die 6.20.6 mit der unten beschriebenen Anpassung der Projekt-Pfade zu verwenden.Diese hat das gleiche Verhalten wie die Version 6.20.6. D.h. sie kann mit den Reports auf dem Root nicht umgehen. D.h. insbesondere bei der Bearbeitung von Report in Netzwerkumgebungen muss mindestens eine zusätzliche Ebene, also ein Ordner angesprochen werden. Sonst werden die Properties nicht ausgelesen.
Die Datei findest du unter https://community.jaspersoft.com/files/file/41-jaspersoft-community-edition/ Für den Download muss du dich entsprechend registrieren.
Hinweis: Auch für die Installation wird nun eine Registrierung verlangt.
2024-07-01 / 6.20.6
Die Version 6.20.6 steht offensichtlich auch nicht mehr zur Verfügung.
Das bedeutet im Endeffekt. Du musst dir für dein Betriebssystem eine gültige Version der 6.20.5 organisieren.
Wir arbeiten gerade an der Umstellung des Wildfly auf Java 11 und damit verbunden auch auf die Verwendung des aktuellen Jasper Studio 6.21.3.
2024-10-01 / 6.21.3
Mit der Version 1.0.0 oder höher kann Jasper Studio 6.21.3 verwendet werden.
einrichten
Die Einrichtung ist so aufgebaut, dass zuerst die Einstellungen im Standard Workspace erzeugt werden und dann in das Report-Verzeichnis verschoben werden. Damit der Jasperstudio das erkennt, ist ein Anlegen, Verschieben, Löschen und re-Importieren erforderlich. Daher die nachfolgende Beschreibung.
Solltest du mehrere Kieselstein-Installationen parallel betreuen, kannst du durch entsprechende Namensvergabe dies komfortable steuern.
Neues Project = Kieselstein anlegen

Project anlegen Variante 2
Nun im Menü Project und dann Project Explorer
Wenn noch kein Projekt angelegt, dann auch hier anlegen
im leeren darunter liegenden Feld, Rechtsklick mit der Maus
Project einstellen
ACHTUNG: Ab der Version 1.0.3 ist die Pfadtrennung in dist und data aktiv. Idealerweise werden von dir nur die Anwenderspezifischen Reports bearbeitet, die sich im ?:\kieselstein\data\reports befinden.
- Rechtsklick auf Projektname (Kieselstein)
Im Einstellungsdialog, Java Build Path, dann der Reiter Libraries und klicke auf Classpath.
Nun die weiteren Jars hinzufügen, also Knopf Add External JARs.

Und nun die drei Files hinzufügen
core-3.2.1.jar und javase-3.2.1.jar sind für die Bearbeitung von QR-Codes.
kieselstein-ui-swing.jar für die Verwendung der zahlreichen Helperreport-Methoden.
Die Zusatz-Libs findest du hier und
hier
Bitte beachte, dass das aktuell zu deiner Kieselstein ERP Server Version passende ejb.jar verwendet wird.
Ab der Kieselstein ERP Version 1.0.3 wird anstelle der ejb???.jar die kieselstein-ejb-1.0.3.jar verwendet. Du findest diese im lib Verzeichnis des Clients. Kopiere diese idealerweise in das bin Verzeichnis.
Zusätzlich solltest du bei Erweiterungen in den Helper daran denken, dass diese Datei auf die aktuell von dir verwendeten Kieselstein Version aktualisiert werden sollte. Siehe dazu deinen aktuellen Client, ?:\kieselstein\client\lib\kieselstein-ejb-1.?.?.jar
die ejb Datei, in der alle von deinem Server unterstützen Helper enthalten sind.
Bitte beachte, dass die hier angeführten Versionsnummern zu deiner Serverinstallation passen müssen.
Verbinden der Reportdateien mit dem Projekt
Automatisches Build abschalten
Unbedingt vorher das automatische Build abschalten.dafür erneuter Rechtsklick auf den Projektnamen

Nun siehst du wo die Einstellungsdateien liegen. Z.B.
Verschiebe diese nun in dein Kieselstein-ERP-Report-Root-Verzeichnis.

Nun das oben angelegte Projekt löschen
Also erneut rechtsklick auf das Projekt und Delete / löschen
und aus dem Reportverzeichnis wieder importieren
Also erneuter Rechtsklick in das freie Feld im Projekt-Explorer und importieren wählen.
In diesem Import Dialog, wählen General bzw. Allgemein und in dem Ordner den Typ
Existing Project into Workspace.
Hier nun das Reportverzeichnis deines Kieselstein-ERP Servers angeben.
Du findest nun im Projektexplorer unter Kieselstein die gesamten definierten Reports.
ACHTUNG:
Wenn die Reports durch eine andere Quelle, z.B. iReport verändert werden, musst du im jeweiligen Detail (Unter-) Baum mit Rechtsklick die Anzeige aktualisieren. Das auch, wenn nur der Inhalt der Reportdefinition, also das jrxml File geändert wurde.
Hinweis:
Denke daran die Kompatibilität zu iReport 5.0.0 einzustellen.
Tipp:
Die Files bitte immer aus dem Projektbaum des Jasperstudios öffnen und da auf die jrxml Files klicken. Das sind die eigentlichen Sourcen.
Hinweis:
Ist bereits unter einem anderen User eine Jasper Studio Installation vorhanden, so einfach das Jasperstudio starten. Es kommt der Willkommens Schirm. Dann Menü, Window, new Window. Dann im oberen Reiter den Project Explorer auswählen und dann weiter mit rechter Maustaste und Import.
Hinweis mehrere Installationen gleichzeitig warten
Wenn mehrere Kieselstein-Installationen faktisch parallel bearbeitet werden sollten, z.B. für verschiedene Firmen oder für die Testinstallation, so kannst du aus der ersten Installation die oben beschriebenen Dateien bzw. Verzeichnisse in die anderen Reportverzeichnisse kopieren.
WICHTIG: Es sind keine doppelten Projektnamen erlaubt. D.h. es muss nach dem kopieren (und vor dem Importieren) die Datei .project (z.B. ?:\kieselstein\dist\wildfly-12.0.0.Final\server\helium\report.project ) bearbeitet werden. Hier ist der Wert für  name entsprechend auf den neuen eindeutigen Projektnamen zu ändern. Danach bitte bei Projekt importieren fortsetzen.
name entsprechend auf den neuen eindeutigen Projektnamen zu ändern. Danach bitte bei Projekt importieren fortsetzen.
Sollte im Importdialog
das Projekt nicht ausgewählt werden können, so gibt es ein Projekt unter diesem Namen bereits. Also die .project Datei entsprechend bearbeiten.
Wichtig:
In .classpath des Projektes stehen die einzubindenden externen Java-Klassen drinnen. D.h. wenn man gemeinsam ein Report-Verzeichnis verwenden möchte, müssen die externen Java-Klassen auch in den exakt gleichen Verzeichnissen liegen.
Hier hat sich bewährt, die
 Classpathentry’s in UNC Notierung anzugeben.
Classpathentry’s in UNC Notierung anzugeben.
D.h. man kann das bin Verzeichnis auch dafür nutzen, diese speziellen Java Libs, zentral bei den Reports mit zu hinterlegen und damit sehr klar das Projekt zur Verfügung zu haben.
Vor dem compilieren immer speichern
Leider ist es so, dass, obwohl speichern vor compilieren angehakt ist, Jasperstudio auch in der Version 6.20.5 dies nicht zuverlässig macht.Da das Ding auch immer wieder mal abstürzt, habe ich mir angewöhnt, immer bevor ich auf compilieren klicke, auf speichern klicke. Auch das übliche Strg+S geht leider nicht immer.
noch einstellen
Ich habe für mich noch folgende Einstellungen getroffen
Window, Preferences, Generell, Editors
Prompt to save on close event if still open elsewhere
Window, Preferences, Jaspersoft Studio, Report Designer
- Abschalten: Automatically exand bands to fit child elements
- Abschalten: Resize band to accomodate pasted elements
Window, Preferences, Jaspersoft Studio, Report Designer, Rulers And Grid
- Grid Options, schalte ich generell alles aus, lasse aber Show Rulers an und Ruler Measure Unit auf Centimeter.
Window, Preferences, Jaspersoft Studio, Report Designer, Toolbars
- Elements Alignment ist sehr praktisch
Window, Preferences, Java, Compiler
Compiler compliance level -> habe ich auf 1.8 gestellt, da derzeit der Server nur in Java 8 compiliert ist
Window, Preferences, General
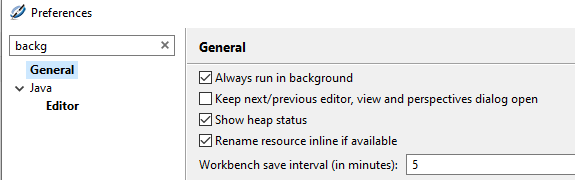
Alway run in background -> abschalten -> üblicherweise compiliere ich nur den Report, der mich interessiert und nicht laufend alle (was man bei komplexen Programmen dann doch will)
Empfehlung
Ich richte alle Felder im 10 Pixel Raster aus. Nur wenn der Platz extrem begrenzt ist, z.B. bei Etiketten gehe ich ins 5er raster oder wirklich Pixelweise. Das hat sich auch für Formulare, welche nach XLS oder CSV exportiert werden sollten, sehr bewährt
Wichtig
Damit die Einstellungen gespeichert werden können, muss man auf das Programmverzeichnis entsprechende Rechte vergeben “c:\Program Files\Jaspersoft\Jaspersoft Studio-6.20.5”
Fehler beim Compilieren finden
Auf den Tab-Problems, den Report suchen und Doppelklick
Info zu Variablen
Wenn man den Namen einer Variablen ändert, ändert er automatisch alle Verwendungen auch ab. Im iReport hat er das nicht gemacht. Hat beides seine Vorteile.
weitere Einstellungen
Wie werden CSV Daten exportiert. Siehe Window, Preferences, Jaspersoft Studio, Exporters und z.B. CSV Exporter. Hier würde ich als FieldDelimiter \t anstatt Komma versuchen.
9.2 - Installation iReport 5.5.0
Einrichten des iReport
Um den iReport mit Kieselstein ERP verwenden zu können, darf ausschließlich die Version 5.5.0 verwendet werden. Diese benötigt selbst wiederum Java 7, welche üblicherweise nicht mehr auf den Rechnern installiert ist.
Wenn du iReport verwenden möchtest, raten wir den iReport nach dem Jasper Studio zu installieren, sodass die Erweiterung .jrxml auf den iReport zeigt und die Erweiterung .jasper auf das Jasper Studio.
Für das Drucken von QR-Codes benötigst du zusätzlich noch
core-3.2.1.jar
javase-3.2.1.jar
Für alle ehemaligen HELIUM V Anwender, hier muss es auch ein lpclientpc.jar geben, welches noch mit Java 7 compiliert wurde. Dieses ebenfalls unter zusatz_libs zur Verfügung stellen.
Unsere Empfehlung ist, dass du im Verzeichnis c:\Program Files (x86)\Jaspersoft\iReport-5.5.0\ ein weiteres Unterverzeichnis zusatz_libs anlegst in das diese Dateien installiert werden. Diese Dateien müssen in den Classpath (Extras, Optionen, Reiter Classpath) mit aufgenommen werden.
Zusätzlich muss die c:\Program Files (x86)\Jaspersoft\iReport-5.5.0\etc\ireport.conf geändert werden, dass beim Aufruf von iReport 5.5.0 das Java 7 verwendet wird.
Wir legen dies üblicherweise unter c:\Program Files (x86)\Jaspersoft\iReport-5.5.0\jre7 ab.
D.h. hier ist das
jdkhome=“c:\Program Files (x86)\Jaspersoft\iReport-5.5.0\jre7”
zu setzen.
Da das JRE7 in der richtigen Version aktuell schwer zu bekommen ist, haben wir hier eine Version zusammengestellt.
Vor dem ersten Einsatz des iReport solltest du unter Optionen Plugins konfigurieren Check for iReport Updates ausschalten und wichtig unter Optionen, Optionen Register Compiler Reportverzeichnis zum Compilieren verwenden anhaken. Der Haken bei keep.java kann entfernt werden.
Dass du auf das Verzeichnis der Reports ein Schreibrecht haben musst ist selbstverständlich. Bitte beachte auch, dass, falls die Reports auf einem Netzwerk-Share liegen, dieses Share mit ein Laufwerksbuchstaben zugewiesen sein muss. Mit UNC Pfad kommt der iReport nicht zurecht.
daran denken
Um im iReport die Konfigurationen überhaupt speichern zu dürfen, sind Schreibrechte am Verzeichnis erforderlich.
Report Editor
Nachfolgend Hinweise zu der Arbeitsweise und den Eigenheiten von iReport welche bei der Gestaltung der Reports beachtet werden sollten.
Hinweis: Für das Arbeiten mit iReport sollte mindestens eine Zwei-Tasten Maus zur Verfügung stehen. Eine Bearbeitung der Druckformulare mit nur eine Maustaste (MAC) ist nicht möglich.
Achtung: Wenn Sie Druckformulare selbst bearbeiten wollen, müssen Sie diese als Anwenderreport ablegen, da ansonsten die bearbeiteten Reports bei einem Update der Kieselstein ERP Version gelöscht werden!! Die Hierachie der Verzeichnisstruktur siehe Vor dem ersten Einsatz des iReport sollten Sie unter Optionen Plugins konfigurieren Check for iReport Updates ausschalten und ‘‘‘wichtig’’’ unter Optionen, Optionen Register Compiler ‘‘‘Reportverzeichnis zum Compilieren verwenden’’’ anhacken. Der Haken bei keep.java kann entfernt werden.
Das Sie auf das Verzeichnis der Reports ein Schreibrecht haben müssen ist selbstverständlich.
Grundsätzliche Vorgangsweise beim Bearbeiten eines Reports
- Wenn nicht vorhanden, ein Verzeichnis für Anwenderreport anlegen, und Originalreports hineinkopieren.
- Bei bereits vorhandenem Anwenderreport: Backup des Anwenderreport-Verzeichnis erstellen.
- Textfelder (Felder oder Parameter) im iReport anpassen.
- Änderung speichern und mit “Build - Compilieren” werden ihre Änderungen im laufenden System übernommen.
- Änderung mit Kieselstein ERP Client ansehen (den entsprechenden Report Druck aufrufen).
Feldnamen der Reports
Starten sie das Programm iReport. Gehen Sie auf “Datei -> Öffnen” und laden Sie den entsprechenden Report.
Unter “Ansicht -> Report Felder” und “Ansicht -> Report Parameter” finden Sie die Feldnamen und die Parameter Namen des Report.
“Felder” werden nur im Detailabschnitt des Reports verwendet. Für jede z.B Rechnungsposition wird eine Zeile im Detailabschnitt des Reports gedruckt. Zugriff auf ein Feld mit dem Namen Gesamtpreis ist über $F{Gesamtpreis} möglich.
“Parameter” sind nur einmal im ganzen Report vorhanden. Zugriff auf einen Parameter mit dem Namen P_KOPFTEXT ist über $P{P_KOPFTEXT} möglich.
Die Namen sind sprechend gewählt z.B im Anwenderreport der Rechnung unter: im Dateiverzeichnis deines Kieselstein ERP Server (…) /server/helium/report/rechnung/anwender/rech_rechnung.jrxml finden Sie den Parameter P_KOPFTEXT, dieser enthält den Kopftext der Rechnung.
Wollen Sie z.B P_KOPFTEXT ändern gehen Sie im Report auf das entsprechende Feld, klicken mit der rechten Maustaste darauf und wählen “Eigenschaften”.
Unter “Textfeld -> Ausdruck für Textfeld” sehen Sie den Wert des Feldes. Wenn Sie unten Rechts auf “Expression Editor öffnen” klicken können Sie leicht verschiedene Felder oder Parameter auswählen und mit “Anwenden” übernehmen.
Unter “Allgemein -> Drucken wenn” wird angegeben, wann der Inhalt des Feldes angedruckt werden soll. Z.B new Boolean($F{Positionsart}.equals(“Stuecklistenpos”)) gibt an das das Feld nur gedruckt werden soll, wenn der Wert des Feldes Positionsart gleich “Stuecklistenpos” ist.
In Textfeld und Allgemein können Sie einige Konstrukte der Java Programmiersprache verwenden, die Datentypen der Felder und Parameter entsprechen Java Datentypen, weitere Informationen dazu finden Sie in der Java Dokumentation.
Wenn Sie Änderungen durchgeführt haben, gehen Sie auf “Build -> Compilieren” und ihre Änderungen werden im laufenden System übernommen.
Bevor Sie Änderungen machen empfehlen wir ein Backup des Reportverzeichnises zu erstellen, dadurch können fehlerhafte Änderungen zurückgenommen werden.
Weiterführende Dokumentation: Kostenpflichtige iReport Dokumentation zu beziehen unter: http://www.jasperforge.org/sf/wiki/do/viewPage/projects.ireport/wiki/HomePage iReport Hilfen und Dokumentation sind über Suchmaschine im Internet auffindbar
Dies ist nur eine Kurzanleitung wie iReport mit Kieselstein ERP Drucken eingesetzt werden kann und stellt keine ausführlich iReport Anleitung dar.
Die Größe der gedruckten Barcodes richtet sich nach der Größe des definierten Feldes. Der Barcode wird so gedruckt, dass er sowohl von der Breite her, als auch von der Höhe her in die gedachte Umrahmung des Feldes passt. Zugleich wird das für den Barcode erforderliche Strich/Lücken Verhältnis beibehalten.
Anmerkung: Die Angabe erfolgt in 1/72" (Punkt bzw. Dezidot) Für die Umrechnung von Punkten auf mm verwenden Sie als Näherung bitte einen Multiplikator von 0,353. So ergeben 220 Punkte eine Breite von 77,66mm
In der Praxis hat sich bewährt, eine Höhe von 10mm (28Punkte) zu verwenden und die Breite ausreichend Breit zu definieren.
(100/72 = Inch * 25,4 = mm = 1/72*25,4 = 0,35277)
Bitte bedenken Sie, dass ein gut lesbarer Barcode zu anderen Strichen und Kanten einen ausreichenden Abstand haben muss. Als mindest Abstand ist die Breite zweier Zeichen zu empfehlen.
Bitte bedenken Sie auch, dass Barcodescanner üblicherweise eine maximale Erfassungsbreite von 70mm haben. D.h. mit einem Rand von wenigen Zeichen darf ein Barcode maximal 220Punkte breit sein.
Die Definition der Barcodetype wird über den Formulareditor vorgenommen.
Üblicherweise wird der Code 128 oder der QR-Code verwendet. Bitte beachte dazu auch Drucken von Barcodes
Welche Parameter können wo verwendet werden.
Alle Parameter sind in den vordefinierten, von uns gepflegten Reports enthalten. Sollten Sie in Ihrem eigenen (Anwender) Report Parameter vermissen, so öffnen Sie bitte den original Report, gehen Sie auf Ansicht, Reportparameter. Hier sehen Sie nun alle definierten Felder, Variablen und Parameter. Sie können den gewünschten Parameter nun mit der rechten Maustaste kopieren, in Ihren eigenen Report wechseln und dort mit rechter Maustaste und Einfügen in Ihre Reportparameterliste aufnehmen.
ACHTUNG: Die Parameter werden nur innerhalb der gleichen Reports unterstützt. Das Einfügen ungültiger Parameter in einen Report kann zum Abbruch des Programms führen.
Drucken des Pageheaders aus dem Summary heraus, wenn im Summary ein Seitenumbruch ist.
Dies ist im Konzept des JasperReports nicht direkt vorgesehen. Als Work Around gehen Sie bitte wie folgt vor:
Definieren Sie eine neue Gruppe mit Namen Summary und als äußerste Gruppe definieren. D.h. sie muss in der Ansicht der Reportgruppen als erstes stehen. Die Summary-Gruppe mit Header Höhe 0 und Footer Höhe 78 anlegen. Die Felder aus dem original Summary in den Footer der (neuen) Summary-Gruppe (=SummaryFooter) verschieben.
Das original Summary auf Höhe 0 setzen.
Anmerkung: Sind in den Detailpositionen Felder mit Höhe 0 enthalten, werden sie beim Einfügen der neuen Gruppe nicht mitverschoben. Diese müssen manuell an die richtige Position gebracht werden, also an die richtigen Position in der richtigen Gruppe per Hand nachziehen. Beispiel: $F{Lerrzeile} im Detail des Rechnungsreports.
Dringende Empfehlung:
Bilder, die auf einem Report ausgedruckt werden sollten, dürfen im Dateinamen keine Leerzeichen enthalten. Der Dateiname sollte nur aus Kleinbuchstaben und _ bestehen. Er darf nur mit Buchstaben beginnen, im weiteren Namen dürfen Ziffern vorkommen, aber nicht an erster Stelle.
Definition der Abmessungen des Reports:
Die Abmessungen eines Reports / eines Formulares, z.B. einer Etiketten können im Reportgenerator unter Ansicht, Reporteigenschaften definiert werden. Definieren Sie hier Abmessungen, Ausrichtungen und Ränder. WICHTIG: Es hat sich bewährt, den Drucker immer im Porträt bzw. Hochformat zu definieren, auch wenn ein Formular verwendet wird, welches Breiter als Hoch ist. Um dies für die Reportvorlage richtig definieren zu können, müssen Sie die Höhe etwas höher als die Breite angeben. Die eigentliche Höhe des Etikettes definieren Sie dann mit der Höhe des Druckbereiches im jeweiligen Druck-Band (Detail, bzw. Title). Siehe dazu auch Etikettendruck.
Wenn Sie die Abmessungen des Reports verringern, so achten Sie bitte unbedingt darauf, dass auch die Höhen der einzelnen Elemente der Dokumentenstruktur (pageHeader, Detail usw.) angepasst werden müssen. Sind diese zu groß erhalten Sie Fehlermeldungen wie:
“1. The detail section, the page and column headers and footers and the margins do not fit the page height.”
Gehen Sie in diesem Falle in die verwendeten Elemente (Bands) und klicken Sie in die Band height. Geben Sie hier einen Wert ein der passt (mm -> DeziDots = mm/0,353) oder höher ist. Beim Verlassen des Feldes wird dieser Wert dann automatisch auf die richtige Höhe gesetzt.
Der Druck des Lieferscheins ist nach unten verschoben
Wenn man ein Feld mit einer bestimmten Höhe aus einem Report löscht, dann bleibt der dafür reservierte Platz bestehen, da dieser über die Bandbreite jenes Bandes bestimmt wird, in dem sich das Feld befindet. Um also den entstehenden Leerraum zu entfernen, der durch das Löschen des Feldes entsteht, muss man die Bandbreite entsprechend anpassen.
Beispiel: Es wird ein Feld “P_BEZEICHNUNG” mit Höhe 24 Pixel aus dem Band “Title” entfernt. In der Folge muss die Bandbreite des Bandes “Title” ebenfalls um 24 Pixel verringert werden.
Seit meiner letzten Änderungen werden die Texte mit Style Informationen gedruckt.
Wird in Ihrem Report ähnliches wie angedruckt, so muss für das jeweilige Textfeld unter Font, Is styled text angehackt sein, damit die Formatierungsinformationen aus den Kommentardateien, aus den Textdateien usw. mit angedruckt werden.

Datenexport aus der Druckvorschau
Damit insbesondere Listen in anderen Programmen weiterverarbeitet werden können, wird dringend empfohlen die Spalten und Zeilen auszurichten. Nur so wird erreicht, dass auch in den exportierten Daten die Spalten untereinander stehen. Es reicht NICHT dies optisch auszurichten. Es muss dies mit den Jasper Werkzeugen, gleiche Breite UND links bzw. rechtsbündig ausgerichtet werden. Auch die Höhen müssen gleich und ausgerichtet sein.
Für den eigentlichen Export verwenden Sie am Besten den CSV Export.
Um die Datei in Excel zu übernehmen benennen Sie nun die Erweiterung der Datei bitte auf .TXT um. Nun mit Excel öffnen, Getrennte Breite, Trennzeichen Komma, Texterkennung “”, markieren Sie nun alle Spalten und Kennzeichnen Sie diese als Text und nun Fertigstellen.
So haben Sie die Daten optimiert importiert.
Drucken von mehrspaltigen Reports z.B. für Etiketten
Mit iReport können auch mehrspaltige Reports definiert werden, so wie sie z.B. für Laseretiketten für Laserdrucker (Zweckform, Herma, …) benötigt werden. Definieren Sie dazu die Eigenschaften des Reports unter Bearbeiten, Reporteigenschaften und klicken Sie auf den Reiter Spalten.  Geben Sie hier die gewünschte Anzahl der Spalten ein und definieren Sie auch den benötigten Zwischenraum.
Geben Sie hier die gewünschte Anzahl der Spalten ein und definieren Sie auch den benötigten Zwischenraum.
Im eigentliche Report finden Sie nun die angegebenen Spalten angezeigt. Definieren Sie nun die Inhalte der linken Spalte.

Wichtiger Hinweis:
Der Druck von Etiketten auf A4 Vorlagen ist nur für den Ausdruck von einmaligen “Listen” zu empfehlen. Gerade für die Schritte bei denen einzelne Etiketten benötigt werden, z.B. Wareneingang, werden Drucker benötigt, welche diese Einzelnen Etiketten auch ausdrucken können. Das mehrmalige Einlegen von A4-Etiketten hat schon so manchen Laserdrucker ruiniert. Auch diese Formulare sind nur für den einmaligen Durchlauf durch den Laserdrucker gedacht. Wir hatten immer wieder Fälle in denen einzelne Etiketten sich vom Trägermaterial gelöst haben und auf der Trommel des Druckers geklebt sind.
Praktische Kommandos, Bedingungen im iReport
Nachfolgend eine lose Sammlung praktischer Kommandos für den iReport.
-
Nur Drucken wenn String Leer ist:
new Boolean($F{F_POSITION}!=null&&$F{F_POSITION}.trim().length()>0)
F_POSITION ist hier der String -
new Boolean($F{F_POSITION}!=null&&$F{F_POSITION}.trim().length()>0 && $F{F_POSITIONSART}.equals(“Ident “))
Beachten Sie bitte, dass auch jeder Abschnitt seine Bedingung hat. So sind die Bedingungen für den PageHeader üblicherweise in diesem abgebildet (<$V{IS_CURRENT_PAGE_NOT_ONE}>) und nicht bei jedem einzelnen Feld.
Funktionen die von Kieselstein ERP zusätzlich für die Reportgestaltung im iReport verwendet werden können
Nachfolgend eine Sammlung ergänzender Funktionen für die Verwendung im iReport. Voraussetzung dafür ist, dass das lpclientpc.jar in den Classpath des iReport (siehe Extras, Optionen, Classpath) eingebunden ist.
Alle Funktionen sind in der Klasse com.lp.util.HelperReport gesammelt. Der Aufruf aus iReport entspricht immer dem Muster:
com.lp.util.HelperReport.FUNKTION
-
boolean pruefeObCode39Konform(String sString) Sind in dem String nur Code39 druckbare Zeichen enthalten
-
String wandleUmNachCode39(String input) Ersetzt Umlaute mit deren Entsprechung ohne Umlaut
-
Double time2Double(java.sql.Time time)
-
String ersetzeUmlaute(String input) Wandelt Ö auf Oe usw.
-
String wandleUmNachCode128(String input)
-
String ersetzeUmlauteUndSchneideAb(String input,int maxStellen)
-
String getWochentag(java.util.Locale locale, java.sql.Timestamp tDatum) Liefert den Wochentagsnamen in der jeweiligen Sprache
-
String ganzzahligerBetragInWorten(Integer betrag)
-
Integer getCalendarOfTimestamp(java.sql.Timestamp tTimestamp, Locale locale)
-
String getMonatVonJahrUndWoche(Integer iJahr, Integer iWoche, Locale locale) Liefert den Monatsnamen eines Jahres und einer Kalenderwoche
-
Integer getCalendarWeekOfDate(Date date)
-
Integer getCalendarWeekOfDate(String sDate, Locale locale)
-
Boolean pruefeEndsumme(BigDecimal bdReportNettoValue, BigDecimal bdHvValue, Double dAbweichung, String listeMwstsaetze, Locale reportLocale)
-
String laenderartZweierLaender(String lkzKunde, String lkzBasis, String uidNummer, java.sql.Timestamp tsEUMitglied) Ermittelt die Länderart des Kunden in Bezug auf die Basis (= Mandant)
-
int berechneModulo10(String nummer) ’nummer’ darf nur Ziffern zwischen 0 und 9 enthalten!
-
String berechneModulo10Str(String nummer)
-
Time double2Time(Number zahl)
-
Konvertierung eines Strings in einen anderen Datentyp, ohne Fehlermeldung (Exception): BigDecimal toBigDecimal(String bigDecimal) ; // wandelt nach BigDecimal, in Locale “deAT” BigDecimal toBigDecimal(String bigDecimal, Locale locale) ; // wandelt nach BigDecimal in angegebener Locale
BigInteger toBigInteger(String bigInteger) ; // wandelt nach BigInteger mit Radix 10 (Dezimalzahlen) BigInteger toBigInteger(String bigInteger, int radix) ; wandelt nach BigInteger mit angegebenen Radix (oktal, hex, ….)
Integer toInteger(String integer) ; // wandelt nach Integer
All diesen Funktionen gemeinsam: Bei einem fehlerhaften Format, oder auch null als Parameter wird null anstatt einer Exception zurückgeliefert. Dies muss im Report entsprechend ausgewertet werden. Anwendungsbeispiele: HelperReport.toBigDecimal(“25'100,12”, new Locale(“de”, “CH”)) ; // deCH HelperReport.toBigDecimal(“25.100,12”) ; // deAT HelperReport.toBigDecimal("-25'987.65”) ;
Bei der Komplierung kommt eine ClassNotFoundException Fehlermeldung
Diese Meldung bedeutet, dass der iReport Compiler eine Java Klasse nicht findet. Um die Formulare von Kieselstein ERP mit der gewünschten Funktionalität auszustatten, werden viele Klassen direkt von Kieselstein ERP zur Verfügung gestellt. Dafür muss der Pfad auf den Kieselstein ERP Client mit in den ClassPath des iReport eingebunden werden.
Sie finden dies unter Extras, Optionen, Classpath. Geben Sie hier den Pfad auf den aktuellen Kieselstein ERP Client an.

Fehlermeldung unsupported version
Kommt beim Compilieren eine Fehlermeldung ähnlich java.lang.UnsupportedClassVersionError: com/lp/util/report/PositionRpt : Unsupported major.minor version 51.0 so bedeutet dies, dass iReport nicht unter Java 7 ausgeführt wird.
Beachten Sie bitte in jedem Falle, dass Sie iReport nur unter Java 7 genutzt werden kann und dass Sie dafür den Client für Java 7 benötigen. Die Clients für Kieselstein ERP sind für Java 8 kompiliert, was bedeutet dass für Anwender die nur Kieselstein ERP verwenden, das JasperStudio eingesetzt werden muss. Die Arbeitsweise ist sehr ähnlich.
9.2.1 - Rückwärts-Kompatibilität Jasperstudio -> iReport 5.5.0
Rückwärts Kompatibilität des iReport <-> Jasper Studio
Es kommt immer wieder vor, dass Reports im Jasperstudio ohne Berücksichtigung der Rückwärtskompatibilität bearbeitet wurden.
Wenn man nun, aus den verschiedensten Gründen, als Report-Designer dann doch den alten iReport verwenden möchte / muss, so sind uns bisher folgende Punkte aufgefallen, die über einen Texteditor im jrxml File geändert werden müssen.
-
Änderungen
- das Feld textAdjust=“StretchHeight” aus JasperStudio muss in iReport isStretchWithOverflow=“true” heissen.
Wichtig: Wurde die Rückwärtsübersetzung nicht durchgeführt, geht die Information verloren und damit wurde eventuell der Report teilweise unbrauchbar, da nicht mehr die gesamte Information angedruckt wird.
- das Feld textAdjust=“StretchHeight” aus JasperStudio muss in iReport isStretchWithOverflow=“true” heissen.
-
Verschiedene Barcode Komponenten die über JasperStudio eingefügt wurden, kann der iReport nicht mehr interpretieren. D.h. diese im JasperStudio aus dem XML entfernen und “nur” abspeichern. Dann kann der Report wieder im iReport geöffnet werden.
Beim Öffnen im iReport erscheint z.B. die Fehlermeldung:
Man findet im Report.jrxml
Diesen Block komplett entfernen und durch ein iReport Element ersetzen.
In diesem Falle ist es ein DataMatrix Barcode, welcher in seiner Definition im iReport anders ist, da andere Lib’s verwendet werden.
Zusatznotiz zum DataMatrix Code.
In den freien Lib’s ist bei Dateninhalten mit drei oder mehr * (Sternchen) ein Bug enthalten, der den Code für die Scanner nicht lesbar macht. Dies ist derzeit (2024) nur durch Kauflizenzen der Barcodelibrary behebbar. Daher unser Rat -> QR-Code verwenden.
9.3 - Formulare bearbeiten
Formulare bearbeiten
Wie in der Bearbeitung von Formularen vorgehen
Bereiche eines Formulares
Es hat sich bewährt, die Bereiche, welche Bands genannt werden, die nicht benötigt werden, mit löschen zu entfernen. Die üblichen Standardbereiche (z.B. Summary) erscheinen dann in Grau und können jederzeit wieder aktiviert werden.
Title
Daten die vom Kieselstein-ERP Server angeliefert werden
Parameter
Fields
Variablen
Empfehlungen zum Bearbeiten
wo findet man im Jasperstudio was?
Seiteneigenschaften:
- Report anklicken, rechte Maus
- Show Properties
- dann im rechten Eingabedialog, rechts unten
 Edit Page Format
Edit Page Format - hier kann auch die Darstellung der Feldeinheiten (Pixel, mm) eingerichtet werden.
wie findet man Parameter / Field - Namen?
Manchmal kommt es vor, dass man einfach den Namen des Parameters / des Feldes nicht findet (weil schon 100-Mal überlesen). Dafür einfach in den Reiter Source gehen und hier nach Teilen des erwarteten Namens suchen. Meist wird es dann klar, wie der Name genau lautet.
kann man Parameter / Fields von einem zum anderen Report kopieren ?
Nein!
Da die Werte / Inhalte der Parameter / Fields über sogenannte Call-Back abgerufen werden, werden vom Kieselstein ERP Server nur die Inhalte angeliefert, die auch tatsächlich programmtechnisch vorgesehen sind.
In allen Hauptreports stehen folgende Parameter zur Verfügung, auch wenn sie nicht in den Formularen ausgeführt sind (historisch bedingt).
- REPORT_DIRECTORY
- REPORT_ROOT_DIRECTORY
- P_LOGO_IMAGE
- P_MANDANT_OBJ
- P_SUBDIRECTORY
- P_MODUL
- P_SQLEXEC
- P_SQLEXEC.execute(QueryString mit einem Rückgabewert)
- P_SQLEXEC.executes(QueryString mit einem Array von Rückgabewerten)
Als Beispiel siehe pers_benutzerstatistik.jrxml, Variable MaxAB_Pos_1 bzw. siehe - P_SQLEXEC.subreport(QueryString mit Rückgabewert(en) die wiederum in einem Subreport verwendet werden können)
kann man Formulare kopieren?
Das kommt darauf an!
Will man eine Reportvariante erstellen, so muss immer vom Original Formular ausgegangen werden. Die meisten Fehler passieren, wenn man unterschiedliche Formulare, die optisch gleich sind, übertragen möchte.
Ein Beispiel:
Das Los Ablieferetikett wurde schön gestaltet, es funktioniert alles. In diesem konkreten Falle wurde auch die Referenznummer der Stückliste mitgedruckt.
Nun bestand auch der Wunsch, dass das Losetikett gleich aussehen sollte, einziger Unterschied, die Chargennummer kommt aus dem Kommentar.
Nun wurde einfach das Ablieferetikett kopiert und als Losetikett definiert. Ging eigentlich ganz gut, nur die Referenznummer wurde nicht gedruckt.
Hintergrund: Die Fields und Parameter sind leider, aus den verschiedensten Gründen nicht immer gleich benannt. Daher findet der Callback das Field, den Parameter nicht und somit kann es nicht funktionieren.
Um nun, gerade bei Etiketten diese effizient vom einen Formular zum anderen zu Übertragen hat sich folgende Arbeitsweise bewährt:
- kopieren der neuen Ziel-Etikette auf den gewünschten Namen (alles klein, keine Umlaute nur Underline)
- öffnen der optisch zu kopierenden Etikette und der Zieletikette im Reportgenerator
- verschieben der original Felder in der Zieletiketten z.B. rechts raus, damit im eigentlichen Feld Platz wird.
- Kopieren aller Felder in die Zieletikette
- üblicherweise sind die Felder um 10x10Pixel nach rechts unten verschoben. Also mit Strg+Cursor nach oben und nach links an die richtige Stelle schieben
- speichern
- die Größe der Zieletikette anpassen
- die Felder / Parameter auf die richtigen Namen unbenennen
- die überzähligen Felder löschen
- compilieren. Hat man vergessen ein Feld umzubenennen kommt ein entsprechender Fehler.
Merke
Fields und Parameter immer nur vom Original-Ausgangsreport nachtragen. NIE von irgend einem anderen Report, auch wenn er sehr ähnlich zu sein scheint.was bedeuten die gelben Rufzeichen?

in “alten” Reports werden für sehr viele Felder diese Ausrufezeichen angezeigt. Diese bedeuten generell, dass mit diesem Feld irgendwas nicht stimmt. Da man beim normalen Arbeiten diese Information benötigt, sollten die “falschen” Fehler / Warnungen entfernt werden.
Fährt man mit der Maus auf das Ausrufezeichen, so sieht man eine genauere Fehlermeldung. 
Das bedeutet nun, dass man, um diesen Hinweis wegzubekommen, die PDF Font Namen aus dem Source entfernen muss. Also:
- auf den Reiter Source klicken
- Strg+F (Finden und Ersetzen) und PDFFontName eingeben
- damit findet man den ersten Eintrag von

- diesen durch nichts (leer) im gesamten XML ersetzen
- üblicherweise sind pdfFontName=“Helvetica” und pdfFontName=“Helvetica-Bold” verwendet. Diese alle entfernen. Damit sind die Warnungen bzgl. PdfFontName weg und die Rufzeichen haben wieder ihre übliche Bedeutung.
Sammlung von praktischen Sonderzeichen
| Sonderzeichen | Bedeutung |
|---|---|
| • | Interpunktion |
| · | Middle Dot |
| √ | ok Häckchen, ACHTUNG: Anzeige im Browser geht so nicht. |
| Ø | Durchmesserzeichen, Alt+0216 |
| Siehe dazu auch https://wiki.selfhtml.org/wiki/Zeichenreferenz oder auch https://seo-summary.de/html-sonderzeichen/ |
Für Sonderzeichen in den message-dateien (Sprachübersetzungen) müssen die Unicodezeichen verwendet werden. Eine Definition ist in den jeweiligen Sprachen enthalten, siehe aber auch z.B. https://symbl.cc/de/unicode/table/.
Fehlermeldung: Parameter msg must not be empty
Wenn ein Formular, mit einem Barcode nicht gedruckt werden kann -> es kommt schwerer Fehler und es steht im Detail der Fehlertext:
java.lang.NullPointerException: Parameter msg must not be empty
So bedeutet dies, dass versucht wurde einen Barcode für einen Leerstring auszudrucken.
das muss bitte in der Druckbedingung für den Barcode abgefangen werden, sodass gar kein Barcode erzeugt wird.
9.4 - Farbdefinitionen
Bewährte Farbdefinitionen
Bei der Erstellung von Formularen / Reports ist auch immer die Frage, wie kann man besondere Felder hervorheben. Hier ist mit zu bedenken, dass diese “Farben” auch auf monochromen (SW/WS) Druckern funktionieren sollten.
Gerade für den Druck von Hintergrund Farben hat sich bewährt Pastellfarben zu verwenden.
Ich habe hier einige von mir gerne verwendeten Farbkombinationen zusammen getragen.
Farbdefinitionen für Reports für das Kieselstein ERP-System
Kieselsteinfarben
| Benennung | [R,G,B] Farben |
|---|---|
| Standard | [21,114,138] |
| hell | [33,179,203] |
| sehr hell | [143,207,218] |
Kieselstein Farben der Belegkopfdaten
| Benennung | [R,G,B] Farben |
|---|---|
| Hintergrund | [199,231,237] |
| Trennlinie | [171,219,227] |
Hintergrund Farben = Regenbogenfarben in Pasteltönen
| Benennung | [R,G,B] Farben |
|---|---|
| rot | [247,171,173] |
| orange | [254,214,165] |
| gelb | [250,246,183] |
| grün | [206,229,183] |
| hellblau | [169,222,236] |
| dunkelblau | [165,193,230] |
| violett | [235,200,222] |
weitere gern verwendete Farben
| Benennung | [R,G,B] Farben |
|---|---|
| hellgrau | [204,204,204] (Zebra) |
| orange | [255,161,50] (Sonntag) |
| mittleres orange | [255,184,101] |
| helles orange | [255,207,152] (Samstag) |
| blau | [88,193,218] |
| mittleres blau | 142,208,228] (Feiertag) |
| helles blau | [177,224,234] |
| sekundärfarbe | [4,111,159] |
| helles grün | [51,255,0] |
| helles hintergrund rot | [255,153,153] |
9.5 - Formelsammlung
Eine Sammlung von nützlichen Formeln für den Reportgenerator
Die Beschreibung der Helper wurde aus allgemein\muster_qr_code.jrxml entnommen.
iReport = Java 7
Kalenderwoche aus Timestamp errechnen
und das immer für die vorige Woche, als vom Stichtag = Timestamp den Wochentag abzuziehen um auf den Sonntag davor zu kommen
com.lp.util.HelperReport.berechneKWJahr(
new java.sql.Date(
$P{P_STICHTAG}.getTime() -
$P{P_STICHTAG}.getDay()*1000*3600*24
)
)
SQL Abfragen für einen Return-Wert
- $P{P_SQLEXEC}.execute( SQL Query String)
SQL Abfragen für mehrere Werte
- $P{P_SQLEXEC}.executes( SQL Query String) siehe
Werte aus der Datenbank
- Bigint aus DB = Long im Jasper Report
- sum() aus der DB liefert immer BigDecimal
Werte aus dem Report anders zusammenstellen und eigenständig sortieren
Manchmal will man einen Teil eines Reports anders sortieren, verschiedene Zwischensummen darstellen und ähnliches. Hier sei als Beispiel der Report ../eingangsrechnung/er_eingangsrechnung_alle.jrxml genannt. Auf diesem sieht man am Ende des Reports eine Zusammenfassung der verschiedenen Steuersätze. Dafür wird der Inhalt, den man an den Subreport übergeben will, in einer Array-List gesammelt (siehe Variable LISTE_UST_SAETZE bzw. LISTE_UST_SAETZE_ADD). Mit dieser Arraylist wird über einen Helper ein Sub-Report aufgerufen (im Summary er_eingangsrechnung_kontierung_summary). Das besondere an dem Helper ist, dass nach dem ersten Element sortiert wird. Dafür muss dieses ein String sein. Nicht zuletzt deshalb gibt es für diesen Helper zwei Ausführungen.
- HelperReport.sortList wird diesem Helper im Sort ein Null-Wert übergeben, wird mit einer Fehlermeldung abgebrochen
- HelperReport.sortListNoNull dieser Helper akzeptiert auch null in der Sortierung
Strings in Zahlen wandeln
- com.lp.util.HelperReport.toBigDecimal (String bigDecimal, Locale stringLocale) mit und ohne Local
- com.lp.util.HelperReport.toInteger(String integer)
Datum aus Date/Timestamp
$V{LosEnde}.toLocaleString().substring(6,10)+"-"+
$V{LosEnde}.toLocaleString().substring(3,5)+"-"+
$V{LosEnde}.toLocaleString().substring(0,2)
/* $V{LosEnde}.toLocaleString() liefert DD.MM.JJJJ */
ACHTUNG: Liefert das Datum in Abhängigkeit des Report-Locales. Also bei italienisch die italienische Schreibweise (8-nov-2023), welche für SQL Abfragen dann nicht verwendbar ist. Für SQL Abfragen daher z.B. (new SimpleDateFormat(“yyyy-MM-dd”, Locale.GERMAN)).format($V{Datum}) verwenden. Siehe auch.
Datum in String konvertieren
- (new SimpleDateFormat(“dd.MM.yyyy”, Locale.GERMAN)).format($P{P_ANGEBOTSGUELTIGKEIT}) Locale.ENGLISH
- bei den Schreibweisen auf 24Std 12Std achten, für Kalenderwoche auch auf die Java Definitionen (siehe Erfolgsrechnung bzw. Link oben)
Mögliche Beispiele:
- (new SimpleDateFormat(“yyyy-MM-dd”, Locale.GERMAN)).format($V{DiesesMonat})+" 00:00:00"
- (new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”, Locale.GERMAN)).format($F{Von})
- (new SimpleDateFormat(“dd.MM.yyyy”, Locale.GERMAN)).format($V{V_HEUTE}) – im in deutsch lesbaren Format
String in Datum konvertieren
- Wichtig Datum muss im Stringformat dd.MM.yyyy übergeben werden
com.lp.util.Helper.parseString2Date($F{F_REALISIERUNGSTERMIN})
Beginnzeitpunkt rechnen
Von Obigem bekommt man ein Date, welches mit .getTime() in ein Long verwandelt wird. Hier kann man nun ms (Millisekunden) als Long dazuzählen und mit new java.sql.Timestamp(long) in einen Timestamp verwandelt weden kann, mit dem man nun rechnen kann.
So will man z.B. für den jeweiligen Tag wissen, wieviele Stunden der Mitarbeiter vor 6:00 gearbeitet hat. Also:
- z.B. in die Vairable Datum, welche ein Date ist:
(new SimpleDateFormat("dd.MM.yyyy", Locale.GERMAN)).format($F{Zeit}) )
- und dann in die Variable Beginn
new java.sql.Timestamp($V{Datum}.getTime()+(6*3600*1000))
- somit erhält man als long $V{Beginn}.getTime() - $F{Kommt}.getTime()
Stunden dazu oder abziehen
Siehe z.B. rech_rechnung_abrechnung_detail_zeitraum.jrxml
- Variable bis
- new java.sql.Timestamp (($F{t_zeit}.getTime() + (new Double ($F{n_stunden}.doubleValue()36001000)).longValue()))
Wichtig: Man rechnet mit dem Long und wenn man dann wieder eine Uhrzeit braucht, die Konvertierung auf Timestamp
Tagesdifferenzen errechnen
Wenn man Tagesdifferenzen errechnen will so hat sich folgende Herangehensweise bewährt:
(($V{V_HEUTE}.getTime() - $F{Liefertermin}.getTime()) / 3600 / 24 / 1000) -> liefert die entsprechenden Tage
V_HEUTE = Calendar.getInstance(Locale.GERMAN).getTime()
Letzter des Monates
com.lp.util.HelperReport.getLetztenTagDesMonats($V{V_HEUTE}, 0)
Das ,0 ist der Monatsversatz der dazugerechnet wird. Siehe z.B. auch fc_deltaliste_entwicklung.jrxml
Timestamp to Date
Bedeutet, dass die Zeit beim Datum, das auch ein Timeobjekt ist, auf 00:00:00 gesetzt wird.
new java.sql.Date($V{LosBeginn}.getTime())
Kalenderobjekt
Siehe: com.lp.util.HelperReport.asKalender
Dezimalstunden als hh:mm drucken
((String)(com.lp.util.HelperReport.konvertiereZeitDezimalInHHMMSS($V{V_SUMMEDAUER},2,false))) wobei die Variable ein BigDecimal sein muss (siehe auch PJ 19324). Wenn hinten true, dann auch Sekunden
Zahlen in String konvertieren
- String.format("%05d", $F{F_ARBEITSGANG})
nur für integer
BigDecimal to String
String.format("%05.4f" , $V{Rabatt}.doubleValue()*100).replace(",",".")
Je nachdem was man damit machen muss, es kommt der String im default Locale, also ev. noch die Dezimaltrenner usw. bearbeiten.
Time in Double konvertieren
Manchmal muss man aus der Datenbank eine Time, z.B. die Sollzeit eines Zeitmodelles, in ein Double konvertieren um damit weiterrechnen zu können.
$V{U_Sollzeit} == null ? 0.00 : ((new Double($V{U_Sollzeit}.getTime())).doubleValue() / 1000 / 3600 ) +1.0
Gerade oder ungerade
für ein int
$V{KW_int}.intValue()%2 == 0 ? ist eine gerade Zahl
für ein double
xxx.doubleValue()%2 == 0 ? ist eine gerade Zahl
Fremdsprachige Installationen
Bei fremdsprachigen Installationen, z.B. Konzernsprache in Englisch, müssen bereits die default Reports in der Mandantensprache, z.B. Englisch sein.
D.h. unter z.B. report/auftrag/anwender/ müssen bereits die englischsprachigen Reports für den Auftrag sein. Sollte dann ein Kunde eine deutsche AB benötigen,
ist diese unter 001/de zu hinterlegen.
Zugriff auf die Bezeichnung der intelligenten Zwischensumme
Da die intelligente Zwischensumme hierarchiefähig ist, ist der eigentliche Feldinhalt ein String[Array]. Das bedeutet, will man nun auf den Inhalt zugreifen, so muss das Array-Element angegeben werden. So erhält man z.B. mit $F{F_ZWSTEXTE}[0] eben die Bezeichnung der ersten Zeile des Textes der intelligenten Zwischensumme.
Timestamp / Datum formatieren
von ist ein Timestamp (new SimpleDateFormat(“HH:mm”, Locale.GERMAN)).format($F{Von}.getTime())
jetzt als String
new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”).format(new java.util.Date())
zwei Timestamps nur das Datum vergleichen
https://tableplus.com/blog/2018/07/postgresql-how-to-extract-date-from-timestamp.html
To extract a date (yyyy-mm-dd) from a timestamp value For example, you want to extract from ‘2018-07-25 10:30:30’ to ‘2018-07-25’
- Extract from a timestamp column: Use date() function: SELECT DATE(column_name) FROM table_name;
- Extract date from a specific timestamp value: Cast the timestamp to a date by adding ::date suffix: SELECT ‘2018-07-25 10:30:30’::TIMESTAMP::DATE; Or combine date() and substring() function: SELECT DATE(SUBSTRING(‘2018-07-25 10:30:30’ FROM 1 FOR 10));
im Query mit Monaten rechnen
(t_letztewartung+(i_wartungsintervall \* '1 month'::INTERVAL))
eine weitere interessante Variante ist
(start_date + (duration || ' month')::INTERVAL) < '2010-05-12'
siehe https://stackoverflow.com/questions/5909363/calculating-a-date-in-postgres-by-adding-months
oder auch
https://www.postgresqltutorial.com/postgresql-string-functions/postgresql-to_char/
TO_CHAR(n_min, '999999.99') || ' - ' || TO_CHAR(n_max,'999999.99')
aus ...\stueckliste\stk_gesamtkalkulation_konfigurationswerte.jrxml
einen Subreport mit Tagen
com.lp.util.HelperReport.getSubreportKalendertage(
$P{P_VON},
$P{P_BIS},
$P{P_MANDANT_OBJ}.getTheClientDto())
Liefert einen Subreport mit Datum, Feiertag und Sollzeit (in Stunden) des Firmenzeitmodells
Beispiel siehe: proj_projekt_journal_offene_gantt_zeitachse.jrxml
Query um eine Summe der jüngsten 10 Mengen zu erhalten
Der Trick liegt hier darin, dass man sich mit einem Select (dem inneren) die Werte holt, den man dann mit einem zweiten Select (dem äußeren) aufsummiert. Man könnte auch sagen, dass man damit einen zweistufigen Select macht. Also z.B. für die Aufträge:
select sum(n_menge) from (
select n_menge from auft_auftragposition
inner join auft_auftrag on auft_auftrag.i_id=auft_auftragposition.auftrag_i_id
where artikel_i_id in (select i_id from ww_artikel where c_nr like ‘ABC%’)
order by auft_auftrag.t_belegdatum desc
limit 10) as foo;
Für diverse SQL Querys
Siehe https://www.postgresql.org/docs/current/functions-formatting.html alleine schon das SQL kann jede Menge
X_TEXT direkt aus der Datenbank holen
Nachdem im Jasper üblicherweise mit Strings (und nicht mit String-Objekten) gearbeitet wird, aber in der Datenbank auch lange / große X_Texte abgelegt sind, müssen diese mittels CAST aus der Datenbank geholt werden. Z.B. für die Bemerkung aus einer Kostenstelle.
$P{P_SQLEXEC}.execute( “select CAST(X_BEMERKUNG as VARCHAR(3000)) from LP_KOSTENSTELLE where C_NR = ‘10’;” )
Abfrage mit locale
Um das locale in den Querys verwenden zu können:
{REPORT_LOCALE}.toString().replace("_","")
z.B. Übersetzung der Bezeichnung der Mengeneinheiten
$P{P_SQLEXEC}.execute( “select c_bez from lp_einheitspr where einheit_c_nr=’"+$P{P_EINHEIT}+”’ and locale_c_nr=’"+$P{REPORT_LOCALE}.toString().replace("_","")+"’;" )
Datenreihen mit Datum generieren
Für PostgresQL (MS-SQL ist anderes und wird, da nicht OpenSource, von Kieselstein ERP nicht verwendet).
Tage zwischen Datumsbereich:
SELECT day::date
FROM generate_series(timestamp ‘2023-03-01’, timestamp ‘2023-03-31’, interval ‘1 day’) day;
Ergebnis:“2023-03-01”
“2023-03-02”
“2023-03-03”
…
“2023-03-28”
“2023-03-29”
“2023-03-30”
“2023-03-31”
Stunden für Zeitbereich:
SELECT day::timestamp
FROM generate_series(timestamp ‘2023-03-01 12:00’, timestamp ‘2023-03-02 18:00’, interval ‘1 hour’) day;
“2023-03-01 18:00:00”
“2023-03-01 19:00:00”
…
“2023-03-02 09:00:00”
“2023-03-02 10:00:00”
1. Tag im Monat:
SELECT date ‘2023-03-01’ + interval ‘1’ month * s.a AS date
FROM generate_series(0,3,1) AS s(a);
Ergebnis:
“2023-03-01 00:00:00”
“2023-04-01 00:00:00”
“2023-05-01 00:00:00”
Raufzählen
SELECT * FROM generate_series(1,3);
Ergebnis:
1
2
3 als integer
Konvertieren auf BigDecimal
Das einfachste ist BigDecimal.valueOf(value) wobei value z.B. ein Double sein kann.
gerundet auf Nachkommastellen
BigDecimal.valueOf(value).setScale(2, BigDecimal.ROUND_HALF_UP)
Usecase ID wird nicht angedruckt
Macht man einen Druck der Auswahlliste (FLR Liste) muss rechts oben die UseCaseID angedruckt werden. 
Diese wird nicht angedruckt, wenn im ../report/allgemein auch der flrdruck.jasper vorhanden ist.
Zusätzlich darf es den flrdruck.jrxml ausschließlich ein Mal im allgemein geben und in keinem anderen Verzeichnis.
Das führende Herr / Frau ersetzen
Manchmal will / muss man die förmlichen Anreden entfernen. Also aus Herr Mustermann nur Mustermann haben. Das macht man üblicherweise mit replace. Da es aber auch vorkommen kann, dass der Name des Ansprechpartners Herr enthält muss man das über .replaceAll("^Herr","") machen. D.h. es wird NUR das erste Herr durch den nachfolgenden (Leer-)String ersetzt. Ganz genau muss man dann auch noch auf den beginnenden String prüfen. Für die Ansprechpartner gehen wir hier davon aus, dass es immer eine entsprechende Anrede gibt.
Da man damit auch oft noch das Frau entsprechend herausfiltern will, heißt das dann:
.replaceAll("^Herr “,”").trim().replaceAll("^Frau “,”").trim()
Subreport overflowed on a band that does not support overflow
Wenn das nicht der Title, die Page Header / Footer betrifft, dann ist der Report, der den Subreport aufruft auf Horizontal gestellt. Er muss auf Vertikal gestellt sein. Passiert gerne wenn man Reports umkopiert, z.B. mit mehreren Columns und dann gehts am Anfang und auf einmal nicht mehr (weil dann der Overflow kommt). D.h. wenn die Columns auf 1 (zurück-) gesetzt werden, dann auf die Richtung achten.
Zu Datum Tage dazuzuzählen
com.lp.util.Helper.addiereTageZuDatum(date Datum, int Tage)
Beispiel
com.lp.util.Helper.addiereTageZuDatum(com.lp.util.Helper.parseString2Date($P{Liefertermin}) , -2)
im Query zum Datum / Timestamp Tage dazuzählen
select (cast(fert_los.t_produktionsbeginn as date) + i_maschinenversatztage),
fert_los.t_produktionsbeginn, i_arbeitsgangnummer, i_unterarbeitsgang, i_maschinenversatztage, * from fert_lossollarbeitsplan
inner join fert_los on fert_los.i_id=fert_lossollarbeitsplan.los_i_id
where fert_los.c_nr='24/01622-993' and mandant_c_nr='001'
order by i_arbeitsgangnummer, i_unterarbeitsgang;
Wochentage / Wochentagsnamen andrucken
- com.lp.util.HelperReport.getWochentag($P{REPORT_LOCALE},
$F{Datum}) - com.lp.util.HelperReport.getWochentag($P{REPORT_LOCALE}, new java.sql.Timestamp($F{BeginnDatum}.getTime()) … wenn das ein Date ist
Daten anders sortieren
Üblicherweise werden die Daten des Reports anhand der gewählten Sortierung übergeben. Manchmal will man aber diese, z.B. in einer Reportvariante, anders sortieren. Um dies zu bewerkstelligen kann direkt im jrxml das Sortierkriterium angegeben werden.
Es muss dies zwischen field name und variable eingefügt werden.
D.h. hier muss:
eingetragen werden. Damit werden die Daten vom Jasper nach diesem Feld sortiert. Beispiel siehe z.B.: ..\report\bestellung\bes_sammelmahnung.jrxml

Sortierung des Materials des Fertigungsbegleitscheines
So wie oben beschrieben, einfach nur zwischen den Zeilen field_name und variable die Sortfields einfügen.
<sortField name=“F_ARBEITSGANG”/>
<sortField name=“F_UNTERARBEITSGANG”/>
<sortField name=“F_MATERIAL_LAGERORT”/>
Dies ist leider nur im XML ersichtlich.
EMail Nachricht aus dem Report erzeugen
Mit folgendem Helper kann aus dem Report heraus eine Nachricht versandt werden. Z.B. wenn ein Wareneingang gebucht wurde und das Wareneingangsetikett gedruckt wird.
com.lp.util.HelperReport.emailSenden(
"wareneingang@kieselstein-erp.org",
"WE zu BS: "+$F{F_BESTELLNUMMER},
"Es wurde ein Wareneingang von "+$F{F_IDENT}+" "+$F{F_BEZ}+" gebucht",
$P{P_MANDANT_OBJ}.getTheClientDto())
- Empfänger
- Betrifft
- Nachricht
- Clientobjekt um es versenden zu können.
Links hinterlegen
Manchmal ist es praktisch, wenn hinter einem Text, einem Bild ein Hyperlink hinterlegt wird. Damit braucht der Anwender nur auf den Link zu klicken und schon hat er die benötigte Information. Dafür muss dies ein Text Field sein. Dann mit der rechten Maustaste auf das Field und Hyperlink auswählen.
Dies nun auf
Hyperlink type Reference stellen und in den Reference Reiter den gewünschten Webaufruf als String (mit umschließenden Hochkomma “) eintragen.
Beispiel: artikel/ww_inventurstand.jrxml im Lastpagefooter.
Links als GoTo hinterlegen
Manchmal ist es auch praktisch aus dem Formular heraus einen Goto z.B. auf den Artikel oder einen Beleg zu machen. Dafür wird eine besondere Form des Hyperlink verwendet. Idealerweise verwendest du die Artikelstatistik als Vorlage um dies in anderen Belegen einzubauen.
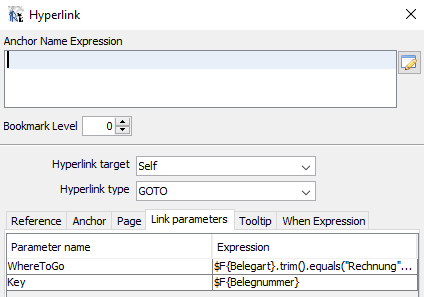
Der besondere Trick liegt im Reiter Link parameters mit den Parameter namen
- WhereToGoTo
- Key
In whereToGoTo kommt die Helperfunktion für den Aufruf des jeweiligen Modules rein
in Key kommt die Belegnummer oder die I_ID des anzuzeigenden Datensatzes rein.
Im Reiter Tooltip kannst du einen entsprechenden String hinterlegen. Leider werden keine Zeilenumbrüche unterstützt.
Aktuell gibt es folgende Helper:
| Helper | Bedeutung |
|---|---|
| com.lp.util.GotoHelper.goto_RECHNUNG_AUSWAHL() | Springe auf die Rechnung |
| com.lp.util.GotoHelper.goto_LIEFERSCHEIN_AUSWAHL() | Springe auf den Lieferschein |
| com.lp.util.GotoHelper.goto_GUTSCHRIFT_AUSWAHL() | Springe auf die Gutschrift |
| com.lp.util.GotoHelper.goto_BESTELLUNG_AUSWAHL() | Springe auf die Bestellung |
| com.lp.util.GotoHelper.goto_FERTIGUNG_AUSWAHL() | Springe auf das Los |
| com.lp.util.GotoHelper.goto_AUFTRAG_AUSWAHL() | Springe auf den Auftrag |
| com.lp.util.GotoHelper.goto_ANFRAGE_AUSWAHL() | Springe auf die Anfrage |
| com.lp.util.GotoHelper.goto_ARTIKEL_AUSWAHL() | Springe auf den Artikel |
| com.lp.util.GotoHelper.goto_ANGEBOT_AUSWAHL() | Springe auf das Angebot |
| com.lp.util.GotoHelper.goto_ANGEBOTSTKL_AUSWAHL() | Springe auf die Angebotsstückliste |
| com.lp.util.GotoHelper.goto_STUECKLISTE_AUSWAHL() | Springe auf die Stückliste |
| com.lp.util.GotoHelper.goto_PROJEKT_AUSWAHL() | Springe auf das Projekt |
| com.lp.util.GotoHelper.goto_ZEITERFASSUNG_ZEITDATEN() | hier muss das ZEITDATEN_I_ID übergeben werden, womit auf die Zeitbuchung gesprungen wird |
Beachte: Ein goto innerhalb des Moduls, wird unterstützt, führt aber immer dazu, dass der soeben angezeigte Report verlassen wird.
Währung aus dem Mandantenobjekt holen
$P{P_MANDANT_OBJ}.getMandantDto().getWaehrungCNr()
Styles hinterlegen
Ein gutes Beispiel für Farbinformationen ist der Report
...\personal\pers_mitarbeiteruebersicht.jrxml.
Etwas einfachers, üblicheres ist z.B.
...\reports\fertigung\fert_gesamtkalkulation.jrxml
Zusätzlich: Wenn du nachträglich Fields von anderen Reports einkopierst, greift die Stylefarbe meistens nicht. Damit diese greift musst du die Farbinformation manuell entfernen. Also:

das forecolor und das backcolor über den Xml Editor manuell herauslöschen. Dann greifen die Farben.
weitere Helper
Du findest eine Aufstellung aller verfügbaren Report-Helper im Report
…/allgemein/muster_qr_code.jrxml
Hier gibt es den Parameter HelperReport  . Fügst du diesen in ein Textfield ein, so siehst du alle verfügbaren Helper.
. Fügst du diesen in ein Textfield ein, so siehst du alle verfügbaren Helper.
Liste der Helper
Hinweis: Können jederzeit Programmtechnisch erweitert werden siehe dazu Source.
toBigInteger( String, int ) java.math.BigInteger
toBigInteger( String ) java.math.BigInteger
toBigDecimal( String, java.util.Locale ) java.math.BigDecimal
toBigDecimal( String ) java.math.BigDecimal
getDauerEinerTaetigkeitEinesTages( String, String, java.util.Date, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
getSubreportPDFAusArtikelkommentar( String, String, String, java.util.Locale, int ) com.lp.util.LPDatenSubreport
getSubreportPDFAusArtikelkommentar( String, String, String, java.util.Locale, boolean, int ) com.lp.util.LPDatenSubreport
getMwstSummeAusListeMwstsaetze( String, java.util.Locale ) java.math.BigDecimal
getVerfuegbarkeitEinerMaschineInStunden( String, int, int, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
berechneOffenenWertEinerBestellung( String, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
berechneOffenenWertEinesAuftrags( String, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
konvertiereZeitDezimalInHHMMSS( java.math.BigDecimal, int, boolean ) String
getSubreportArtikelErsatztypen( String, com.lp.server.system.service.TheClientDto ) com.lp.util.LPDatenSubreport
getSubreportAusStringMitKommaGetrennt( String ) com.lp.util.LPDatenSubreport
getSubreportEnthaltenesLosIstMaterial( String, String, com.lp.server.system.service.TheClientDto ) com.lp.util.LPDatenSubreport
getWochentag( java.util.Locale, java.sql.Timestamp ) String
time2Double( java.sql.Time ) Double
getLief1Preis( String, java.math.BigDecimal, String, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
sortList( java.util.List ) java.util.List
double2Time( Number ) java.sql.Time
emailSenden( String, String, String, com.lp.server.system.service.TheClientDto ) boolean
haengeArrayAn( Object[], Object[] ) Object[]
getSSCC( Long, String ) String
joinStrings( String[], String ) String
zinsesZins( java.math.BigDecimal, java.math.BigDecimal, int ) java.math.BigDecimal
toInteger( String ) Integer
bildDrehen( java.awt.image.BufferedImage, int ) java.awt.image.BufferedImage
getArtikeltechnikeigenschaft( String, String, com.lp.server.system.service.TheClientDto ) String
getSubreportAllergene( String, com.lp.server.system.service.TheClientDto ) com.lp.util.LPDatenSubreport
ersetzeUmlaute( String ) String
ermittleTageEinesZeitraumes( java.util.Date, java.util.Date ) int
pruefeObCode128Konform( String ) boolean
getArtikelkommentarBild( String, String, String, java.util.Locale ) java.awt.image.BufferedImage
getSubreportAusPDFFile( String, int ) com.lp.util.LPDatenSubreport
getMonatVonJahrUndWoche( Integer, Integer, java.util.Locale ) String
ganzzahligerBetragInWorten( Integer ) String
getCalendarWeekOfDate( java.util.Date ) Integer
getCalendarWeekOfDate( String, java.util.Locale ) Integer
ersetzeUmlauteUndSchneideAb( String, int ) String
fuehreSQLQueryAus( String ) Object
getSubreportKalendertage( java.util.Date, java.util.Date, com.lp.server.system.service.TheClientDto ) com.lp.util.LPDatenSubreport
getCalendarOfTimestamp( java.sql.Timestamp, java.util.Locale ) Integer
updateLieferantBeurteilung( Integer, Integer, java.util.Date, String, com.lp.server.system.service.TheClientDto ) Integer
getArtikeleigenschaft( String, String, com.lp.server.system.service.TheClientDto ) String
wandleUmNachCode39( String ) String
wandleUmNachCode128( String ) String
pruefeObCode39Konform( String ) boolean
pruefeEndsumme( java.math.BigDecimal, java.math.BigDecimal, Double, String, java.util.Locale ) Boolean
pruefeEndsumme( java.math.BigDecimal, java.math.BigDecimal, Double ) Boolean
rundeKaufmaennisch( java.math.BigDecimal, int ) java.math.BigDecimal
getVDA4092Barcode( String ) String
berechneKWJahr( java.util.Date ) String
getLiquiditaetsKontostand( Integer, com.lp.server.system.service.TheClientDto ) java.math.BigDecimal
sortListNoNull( java.util.List ) java.util.List
getVDA4092Checksum( String ) Character
getMediastandardTextHtml( String, String, java.util.Locale ) String
getSummeIstZeitEinesBeleges( String, String, com.lp.server.system.service.TheClientDto ) Double
berechneUrlaubsAnspruch( String, java.util.Date, com.lp.server.system.service.TheClientDto ) com.lp.server.personal.service.UrlaubsabrechnungDto
sortListNoNullSprung( java.util.List, int, int ) java.util.List
entferneStyleInformation( String ) String
bildUm90GradDrehenWennNoetig( java.awt.image.BufferedImage ) java.awt.image.BufferedImage
seriennummerErzeugen( String, int ) String
berechneModulo10( String ) int
berechneModulo10Str( String ) String
addiereTageZuDatum( java.util.Date, int ) java.sql.Date
getLetztenTagDesMonats( java.util.Date, int ) java.util.Date
laenderartZweierLaender( String, String, String, java.sql.Timestamp ) String
getSubreportGeraeteseriennummernEinerLagerbewegung( String, Integer, String, com.lp.server.system.service.TheClientDto ) com.lp.util.LPDatenSubreport
9.6 - Anwender Reports
Nutzen von Anwender Reports
Anwender Reports müssen in dem ${KIESELSTEIN_DATA}/reports Ordner abgelegt werden.
Der reports Ordner muss immer reports genannt sein.
Namenskonvention
{KIESELSTEIN_DATA} … bezeichnet jenes Verzeichnis, welches in deiner Kieselstein ERP Installation mit der Umgebungsvariablen / Environment definiert ist. In der Regel ist dies für Windows ?:\kieselstein_data\ für Linux /opt/kieselstein/data
{KIESELSTEIN_DIST} … bezeichnet das Verzeichnis, welches in der Environment Variablen hinterlegt ist. In der Regel ist dies für Windows ?:\kieselstein_dist\ für Linux /opt/kieselstein/dist
Finden des zu verwendenden Reports
Je nachdem wo du deine Reports hinterlegst, wird der entsprechende Report verwendet. Die Logik dafür ist folgende:
Pfade mit einer Kostenstelle
Falls eine Kostenstelle vorhanden ist werden zuerst folgende Pfade durchsucht.
- {KIESELSTEIN_DATA}/reports/{modul}/{kostenstelle}/{mandant}/{locale}
- {KIESELSTEIN_DATA}/reports/{modul}/{kostenstelle}/{mandant}
- {KIESELSTEIN_DATA}/reports/{modul}/{kostenstelle}
Standard Pfade
Ansonsten werden folgende Pfade nach einem Report durchsucht.
- {KIESELSTEIN_DATA}/reports/{modul}/{mandant}/{locale_country}
- {KIESELSTEIN_DATA}/reports/{modul}/{mandant}/{locale}
- {KIESELSTEIN_DATA}/reports/{modul}/{mandant}
- {KIESELSTEIN_DATA}/reports/{modul}
- {KIESELSTEIN_DIST}/wildfly-X.X.X.Final/kieselstein/reports/{modul}/{locale_country}
- {KIESELSTEIN_DIST}/wildfly-X.X.X.Final/kieselstein/reports/{modul}/{locale}
- {KIESELSTEIN_DIST}/wildfly-X.X.X.Final/kieselstein/reports/{modul}
Hinweis:
Das impliziert auch, dass die Subdirectorys der Kostenstellen sich nicht mit den Mandantennummern überschneiden dürfen.
D.h. die Reports, welche sich unter {KIESELSTEIN_DIST} befinden, werden bei jedem Update überschrieben. Die Pflege der Anwender-Reports unter Data liegen in deiner Verantwortung.
Anzeige welcher Report verwendet wird
Um den richtigen Report bearbeiten zu können, muss man auch wissen, welcher Report für den Druck den tatsächlich verwendet wird. Daher wird im Titel des Reports und in den üblichen Listen-Auswertungen der verwendete Pfad angezeigt.

Eine wichtige Information ist der führende Buchstabe vor dem Reportpfad. Hier bedeutet S, dass dies ein Standard-Report ist und ein A steht für den Anwender-Report.
D.h. die Standard-Reports findest du unter …/kieselstein/dist/wildfly-26.1.2.Final/kieselstein/reports/… und die Anwenderreports unter …/kieselstein/data/reports/…
Migration der Reports
Alter Pfad {KIESELSTEIN_DIST}/wildfly-X.X.X.Final/kieselstein/reports/{modul}/anwender/{mandant}/{sprache} Neuer Pfad KIESELSTEIN_DATA/reports/{modul}/{mandant}/{sprache}
Auf Linux kann man find . -name "anwender" -type d verwenden um die Pfade aller Anwenderreport Ordner zu finden.
Beispiele:
-
{KIESELSTEIN_DIST}/wildfly-26.1.2.Final/kieselstein/reports/allgemein/anwender/001/en
-
{KIESELSTEIN_DATA}/reports/allgemein/anwender/001/en
-
{KIESELSTEIN_DIST}/wildfly-26.1.2.Final/kieselstein/reports/rechnung/anwender/001
-
{KIESELSTEIN_DATA}/reports/rechnung/001
-
{KIESELSTEIN_DIST}/wildfly-26.1.2.Final/kieselstein/reports/finanz/anwender
-
{KIESELSTEIN_DATA}/reports/finanz
WICHTIG
In einigen alten Reports sind teilweise auch direkte Zuweisungen wie z.B. für Logos oder ähnlichem enthalten. Diese Reports müssen überarbeitet werden.
Sicherung der Reports
WICHTIG
Denke daran, dass nun nur mehr die Reports von ../kieselstein/data/reports gesichert werden müssen.Übertragung der Report-Einstellungen
Nachdem nun die Strukturen der Reports geändert wurden, können mit nachfolgendem Script diese Werte übernommen werden.
update lp_standarddrucker ls
set c_reportname = case when ls.c_reportname like '%/anwender/%.jasper' then '../../../../data/reports' || substr(replace(ls.c_reportname, '/anwender', '/' || substr(ls.c_reportname, 0, POSITION('/' IN ls.c_reportname))), POSITION('/' IN ls.c_reportname))
when ls.c_reportname like '%\anwender\\%.jasper' then '..\..\..\..\data\reports' || substr(replace(ls.c_reportname, '\anwender', '\' || substr(ls.c_reportname, 0, POSITION('\' IN ls.c_reportname))), POSITION('\' IN ls.c_reportname))
end
where (c_reportname like '%/anwender/%.jasper' or c_reportname like '%\anwender\\%.jasper')
and not exists (
select 7 from lp_standarddrucker ls2
where ls2.c_pc = ls.c_pc
and ls2.c_drucker = ls.c_drucker
and ls2.mandant_c_nr = ls.mandant_c_nr
and ls2.c_reportname = case when ls.c_reportname like '%/anwender/%.jasper' then '../../../../data/reports' || substr(replace(ls.c_reportname, '/anwender', '/' || substr(ls.c_reportname, 0, POSITION('/' IN ls.c_reportname))), POSITION('/' IN ls.c_reportname))
when ls.c_reportname like '%\anwender\\%.jasper' then '..\..\..\..\data\reports' || substr(replace(ls.c_reportname, '\anwender', '\' || substr(ls.c_reportname, 0, POSITION('\' IN ls.c_reportname))), POSITION('\' IN ls.c_reportname))
end
and (ls2.reportvariante_i_id = ls.reportvariante_i_id or (ls2.reportvariante_i_id is null and ls.reportvariante_i_id is null))
);
9.7 - Belegkopfdaten
Nutzen von Belegkopfdaten
Üblicherweise hat jeder offizielle Beleg, z.B. Rechnung, einen Informationsblock auf dem die Dinge wie Rechnungsnummer, Rechnungsdatum, Ansprechpartner usw. angegeben werden.
Diese Daten sind meist dynamisch, sollten aber trotzdem an der üblicherweise erwarteten Stelle zu finden sein.
Wir haben dafür den Subreport allgemein\belegkopfdaten.jrxml geschaffen, der von den jeweiligen Belegen zentral aufgerufen wird.
In diesem wird nur die Erscheinungsform definiert. Also Hintergrundfarbe, Schriftarten, Trennlinien, Positionierung, usw..
Die Grundidee ist, dass ein Subreportdatenobjekt erzeugt wird (siehe z.B. angb_angebot.jrxml).
In diesem ist je Zeile der erste Wert die Art dieser Zeile. Danach folgen vier Werte. Es müssen immer diese fünf Felder je Zeile gegeben sein. Mit der Art wird gesteuert, wie die Zeile gedruckt wird. Der Subreport selbst hat zwei Parameter, der als Überschrift z.B. Rechnung, verwendet wird und einen weiteren der für die Belegkennung (z.B. AG für Angebot) verwendet wird. Die Belegkennung wird nicht nach den verschiedenen Sprachen übersetzt.
Als Art sind aktuell folgende Werte definiert:
| Art | Beschreibung |
|---|---|
| Links1 | Überschrift in fett |
| Links2 | zwei Felder, Lable, Inhalt volle Breite |
| Links4 | vier Felder, Lable, Inhalt, Lable, Inhalt |
| Linie | Trennlinie |
| Nicht | nicht drucken, weil |
Zusätzlich ist es so aufgebaut, dass wenn der Inhalt (beide Inhalte) als null übergeben wird, wird die Zeile nicht gedruckt
Wichtig: Es dürfen nur Strings übergeben werden. Damit liegt leider z.B. die Formatierung von Datum’s wieder im rufenden Report.
ACHTUNG: Offensichtlich muss man für trim() bzw. replace() das Null des String-Objektes vorher abfangen, sonst wird an den Subreport alles als Null übergeben. D.h. wenn z.B. nur die Überschrift gedruckt wird, dann ist so ein Element beteiligt. Das Auslösende Element findet man durch auskommentieren.
Positionierung im Beleg
Wir richten uns hier nach der Postverordnung und danach, dass die Adresse des Empfängers im DIN-lang Kuvert positioniert sein muss.
Damit ergibt sich, dass dieser Block der Belegkopfdaten von links herein 260Pixel und 265Pixel breit sein muss. Die einzige mir bekannte Ausnahme wären alte Schweizer Kuverts, die genau verkehrt herum anzuordnen wären. Da auch die Schweizer inzwischen sich nach den DIN-lang Kuvert richten (dürfen / können) würde ich nichts umstellen.
Diese Ausrichtung gilt meiner Meinung nach auch, für Belege die per PDF versandt werden, denn im Zweifel, wird das Dokument ausgedruckt.
9.8 - Report Varianten
Eine Sammlung praktischer / nützlicher Reportvarianten
Da (fast) alle Formulare auch Report-Varianten können und im laufe der Zeit doch eine Vielzahl von praktischen Reports entstanden ist, hier eine Lose-Sammlung was es denn schon so alles gibt.
Das fast bedeutet, dass für die FLR-Drucke keine Reportvararianten möglich sind, da dies generierte Reports sind.
Diese Reports werden von den Mitgliedern der Kieselstein-ERP eG zur Verfügung gestellt und mit der jeweils aktuelle Version ausgerollt.
So wie für alle Reports und Auswertungen. Die richtige Verwendung und die Prüfung der dargestellten Werte liegt beim Anwender / Mitglied.
| Report Zweck | Vorlage | Beschreibung | zu finden unter |
|---|---|---|---|
| nicht erledigte Aufträge mit Lagerreichweite | auft_auftrag_offene_positionen_reichweite | welche Aufträge kann ich aus dem Lager innerhalb der nächsten 8 Monate bedienen. mit möglichen und Soll-Erlösen | Auftrag, Journal, offene Positionen, Variante Reichweite |
| Übermengen | fert_ausgabeliste_mit_uebermenge ww_artikelreservierung |
Gerade in der SMT Fertigung werden meist ganze Rollen in die Produktion gegeben. Nun will man natürlich wissen, welche Übermengen auf welchem Los gebucht sind. Dafür gibt es eine Erweiterung in der Losausgabeliste und in der Reservierungsliste | Los, Drucken, Ausgabeliste Artikel, Info, Reservierungen |
| Spezial KEG Personalliste | pers_personalliste_keg | Darstellung der eingetretenen Personen und deren Zeitmodelle für die Mitarbeiter VZÄ Ermittlung | Personal, Journal, Variante Mitgliederauswertung |
| LS-Gestehungspreise | ls_lieferschein_etikett_inhalt | Gestehungspreise jeder Lieferscheinposition auch wenn es nicht Lagerbewirtschaftet Artikel sind | Lieferschein, Lieferschen, Adressetikette |
| Logindaten | pers_personalliste_login | Gerade während der Systemeinführung, wann hat nun wirklich wer am Kieselstein ERP gearbeitet | Personal, Journal, Variante Login-Daten |
| Lieferungen ohne Rechnung | rech_warenausgangsjournal_ohne_LS | Liste aller Mengenbehafteten Positionen die keinen Lieferschein (und keine Gutschrift) hinterlegt haben | Rechnung, Journal, RE-Pos ohne LS |
| Los Kommissionierliste | Los, Materialliste, fert_materialliste | Welche Artikel sollte ich an den Fremdfertiger liefern | Los, Reiter Material, Druck im Detail |
| Zahllastbetrachtung | finanz_kontoblatt_zahllast | Spezielle Sortierung des Kontodruckes um eine gute Übersicht für das Finanzamtskonto zu bekommen. Voraussetzung dafür ist, dass in den Fibu Grunddaten, Kontoart, bei Abgabe der Abgaben Stichtag (15. / 10.) und bei Ust- Erwerbssteuerkonto die verschobene Fälligkeit in der Sortierung eingetragen ist. | Fibu, Zahllastkonto, Info, Kontoblatt, Nur Zahllast |
| Maschinen-Struktur-Liste | pers_maschinenliste_struktur | Strukturierte Darstellung von der Fertigungsgruppe zur Maschine | Zeiterfassung, Maschinen, Journal, Maschinenliste |
| ER mit WE | er_eingangsrechnung_alle_mit_WE | Eingangsrechnungsjournal mit den zugehörigen Bestellungen aus den Wareneingängen. Vor allem um ER ohne BS zu finden | Eingangsrechnung, Journal, Alle, Variante mit Wareneingängen |
| EK Anf Stkl Vergleich mit BS | as_einkaufsangebot_nk | Vergleich der Einkaufs Anfrage Stückliste mit den tatsächlichen Bestellungen. Die Basis ist die Projektbezeichnung von EkAfStkl und den Bestellungen. Diese müssen die gleichen Bezeichnungen haben | Angebotsstückliste, unterer Reiter Einkaufsangebot, Menüpunkt Einkaufsangebot, Drucken |
| Ek Anf Stkl Bestellinfo | as_vergleich_bs | Druck der durch Preise optimieren ermittelten Bestellwerte | Angebotsstückliste, unterer Reiter Einkaufsangebot, Menüpunkt Einkaufsangebot, Vergleich |
| ABC Verbrauchsanalyse | ww_hitliste_jahresbedarf_abc | Analyse der Artikelverbrauche nach der Paretto Regel | Artikel, Journal, Hitliste |
| Formelstückliste | stk_gesamtkalkulation_formel | Berücksichtigen der Formeln aus der Formelstückliste | Stückliste, Formelstückliste auswählen, Bearbeiten, Konfigurieren |
| Formelstückliste aus Angebot |
stk_gesamtkalkulation_formel_vk | Errechnen eines Angebotes anhand einer Formelstückliste | Angebot, Stückliste |
9.9 - XSL-Dateien
Verwendung / Arbeiten mit XSL-Dateien
Ergänzend zu den Formularen werden im Kieselstein ERP auch XSL Dateien verwendet.
Diese dienen der Steuerung der EMail Vorlagen Texte und der Anpassung der Exportformate an die verschiedenen Finanzbuchhaltungsprogramme.
Nun ist das XSL faktisch eine Art Programmiersprache, womit sich eine weite Möglichkeit für die Anpassung der Ergebnisse ergibt.
Eine schnelle Übersicht findet man z.B. unter https://www.w3.org/People/maxf/XSLideMaker/tut.pdf
Vielleicht hilft auch https://www.softwaretestinghelp.com/xslt-tutorial/ dem einen oder anderen weiter. Gefunden habe ich auch: https://www.tutorialspoint.com/xslt/index.htm
Komische Zeichen in EMails
Erscheinen in deinen versandten EMails komische Zeichen, z.B.

So ist die EMail-Vorlage mit einem Standard Editor bearbeitet worden, wodurch die notwendige Codedefinition verschwindet. Leider ist es so, dass man diesen Fehler nur sehr mühsam findet. Mir ist derzeit nur ein verlässlicher Weg bekannt, mit dem festgestellt werden kann, ob die Datei richtig eingestellt ist.
Lasse dir die Datei mit einem File-Viewer anzeigen der auch Hexdaten darstellen kann. In Windowssystemen nutze ich dazu den im Totalcommander integrierten Fileviewer und schalte mit der Ziffer 3 auf die Hexdarstellung um. Hier sieht man den Unterschied.
| Ansicht | Inhalt |
|---|---|
| Normale Darstellung |  |
| Hex-Darstellung |  hier sieht man deutlich, dass in einer richtig codierten Datei am Anfang noch drei Steuerzeichen sind. Diese codieren die Datei im UTF-8-BOM Format. Leider werden diese Informationen von den allermeisten Editoren entfernt. |
Daher dürfen diese Dateien (in Windowssystemen) nur mit dem Notepad++ bearbeitet werden. Hier wird diese Information erzeugt / hinzugefügt. Siehe dazu auch:
UTF-8-BOM
Es müssen die EMail-XSL Vorlagen in UTF-8-BOM codiert sein.Wichtig: Wenn man Texte von anderen Vorlagen importiert, oder “falsche” Vorlagen korrigiert, so kommt es auch im Notepad++ immer wieder vor, dass die Kodierung automatisch passend zu den gerade importierten Zeichen umgeschaltet wird. D.h. es muss unbedingt vor der Verwendung geprüft werden, ob die Kodierung noch immer auf UTF-8-BOM steht.
Es kommt sonst immer weider vor, dass gerade unsere deutschsprachigen Umlaut falsch dargestellt werden, oder dass beim Versuch die Rechnung per EMail zu senden, eine Fehlermeldung kommt.
Sieht man im Server Log nach, so findet man:
2024-04-16 16:51:16,582 ERROR [stderr] (default task-3) [Fatal Error] :17:12: Invalid byte 1 of 1-byte UTF-8 sequence.
2024-04-16 16:51:16,583 ERROR [stderr] (default task-3) System-ID unbekannt; Zeilennummer17; Spaltennummer12; org.xml.sax.SAXParseException; lineNumber: 17; columnNumber: 12; Invalid byte 1 of 1-byte UTF-8 sequence.
Sonderzeichen in den EMail Vorlagen definieren
Da, insbesondere in den Firmen-Namen immer wieder auch Sonderzeichen enthalten sind, müssen diese entsprechend in den XSL Vorlagen codiert übergeben werden, da das eigentliche Sonderzeichen eine besondere Bedeutung hat. D.h. diese Zeichen sind wie gewünscht zu kodieren:
| Zielzeichen | Codierung |
|---|---|
| & | & |
Siehe dazu gerne auch https://www.htmlhelp.com/de/reference/html40/entities/special.html, Spalte Entität, bzw. Darstellung im Browser
Kostenstellen Subdirectory wird bei XSL nicht unterstützt
Die mögliche Steuerung der Formularvorlagen über die zusätzliche Subdirectory Funktion in den Kostenstellen wird bei den mail.xsl Vorlagen nicht unterstützt.
9.10 - Besonderheiten
Hinweise zu besonderen Formular Verhalten und ähnlichem
Kostenstellenspezifische Kopf- und Fußzeilen
Hier ist darauf zu achten dass auch die Dateien ausdruckmedium.j* mit in die jeweiligen Subreports einkopiert werden müssen.
Solltes du in der Druckvorschau, in der Dokumentenablage übereinander gedruckte Informationen, meist in Kombination mit Speichern unter, finden
so hilft das einkopieren der beiden Dateien.
Hinweis: Die Pfad Definition findest du unter System, Mandant, Kostenstellen, Subdirectory.
10 - Arbeiten mit Barcode
Wie mit Barcode umgehen
Barcodes sind eine praktische Sache. Vor allem in Verbindung mit Serien- bzw. Chargennummern sind sie maßgeblich für die Sicherheit der Erfassung notwendig.
Grundsätzlich unterscheidet man zwei Typen von Barcodes.
- Die sogenannten eindimensionalen Barcodes, oft auch Strichcode genannt. Dazu gehören auch die oft zitierten EAN Codes (European Article Number)
- die zweidimensionalen Barcodes, dazu gehören vor allem Datamatrix und der QR-Code (Quick Response)
| Barcodeart | Vorteil | Nachteil |
|---|---|---|
| Eindimensional | von annähernd allen Scannern lesbar gute Treffsicherheit des einzelnen zu lesenden Codes |
reduzierter Zeichensatz, großer Platzbedarf, mit den Kameras der mobilen Geräte oft nur sehr schwer bis gar nicht lesbar |
| Zweidimensional | nur von dazu geeigneten Scannern lesbar, die meist teurer als die eindimensionalen sind fast alle Zeichen darstellbar, auch deutsche Sonderzeichen usw. |
bei mehreren Barcodes neben- / untereinander Treffsicherheit nur mühsam gegeben |
Beide Barcodetypen können mit den Reportgeneratoren erzeugt werden.
ACHTUNG: Der Datamatrixcode in Verbindung mit Inhalten in denen mehr wie zwei * vorkommen, liefern fehlerhafte Codes. Dies ist nur durch teure proprietäre Barcodelibraries zu beheben. Besser dann gleich auf die Verwendung von QR-Code drängen.
Welche Barcodesequenzen werden vom Zeiterfassungsterminal unterstützt?
Die zentrale Definition aller Barcode-Lead-Ins die von den Kieselstein ERP Geräten verwendet werden, findest du unter bzw. findest du die Definition hier.
HTML BDE Terminal
| Lead In | Bedeutung |
|---|---|
| $P | Personal |
| $L | Los |
| $T | Tätigkeit |
| $M | Maschine |
| $V | Los Kombi AG |
| $U | Auftrag Kombi |
| $A | Auftrag |
| $KOMMT | Kommt Buchung |
| $GEHT | Geht Buchung |
| $UNTER | Unterbrechung = Pause Buchung |
| $ENDE | Ende der Tätigkeit des Mitarbeiters |
| $ARZT | Unterbrechung mit der Sondertätigkeit Arzt |
| $KRANK | Unterbrechung mit der Sondertätigkeit Krank |
| $BEHOERDE | Unterbrechung durch Behördengang |
| $ANZEIGE | Anzeige des aktuellen Zeitsaldos |
Zeiterfassungs-Terminal-Software
Drucken von Barcode
Barcodes werden für die rasche und sichere Erfassung von Artikel und Seriennummern sowie zur Erfassung von BDE Daten usw. verwendet. Überall wo Auftragsnummern, Tätigkeiten, Maschinenzeiten oder Artikel erfasst werden müssen, können durch die Verwendung von Barcodes entsprechende Vereinfachungen verbunden mit der Reduzierung der Eingabezeit und der Reduzierung der Erfassungsfehler erzielt werden. Von Kieselstein ERP werden die durch den iReport unterstützten Barcodes verwendet. Üblicherweise wird der Code 39 bzw. der Code 128 für die eindimensionalen Barcodes, welche auch Strichcode genannt werden verwendet. An zweidimensionalen Barcodes kommen der Datamatrix Code und vor allem der QR-Code zum Einsatz. Um eine entsprechende Bedienerführung und Bedienungssicherheit zu erreichen, ist der Großteil der von Kieselstein ERP verwendeten Barcode mit einem sogenannten LeadIn versehen, welcher die Art des Codes definiert.
Unterstützte Barcodefunktionen
Derzeit sind folgende LeadIn Zeichen für die verschiedenen Geräte definiert:
| Lead In | Bedeutung | HTML-Terminal | ZE-Terminal | ZE-Stift | Mobil |
|---|---|---|---|---|---|
| $P | Ausweisnummer des Mitarbeiters | x | x | ||
| $L | Losnummer | x | x | ||
| $Lnn$MAT | $L Losnummer $MAT Materialentnahmebuchung für das Los |
x | |||
| $T | Tätigkeit (Arbeitszeitartikel) | x | |||
| $M | Maschinen ID (einzelne Maschine) | x | nur für abweichende Maschine | x | |
| $V | Vorgang bestehend aus Los, Maschinen ID, Tätigkeit oder anstelle der Tätigkeit STOP für das Ende der Maschinenzeit oder FT für die Fertigbuchung des Arbeitsganges |
x | x | x | |
| $U | Vorgang bestehend aus Auftrag, Tätigkeit | x | x | x | |
| $W | Vorgang bestehend aus Los, Tätigkeit | x | |||
| $ABLIEFERN | Ablieferungsbuchung | x | |||
| $O | Lagerort/Lagerplatz | x | |||
| $F | Fehlernummer | ||||
| $A | Auftragsnummer z.B. auf Packliste | x | x | x | x |
| $B | Bestellung Nummer | x | |||
| $KOMMT | Anwesenheitszeit Kommt | x | x | x | |
| $GEHT | Anwesenheitszeit Geht | x | x | x | |
| $UNTER | Unterbrechungsbeginn oder Ende | x | x | x | |
| $ENDE | Tätigkeits Ende | x | x | x | |
| $ANZEIGE | Anzeige von Zeitsalden des Mitarbeiters | x | |||
| $STOP | Stop der Maschinentätigkeit | x | |||
| $GROESSEAENDERN | Losgrößen Ändern auf Stückzahl am Terminal | x | |||
| $PLUS | Dient der Zusammenfassung von mehreren Losen zu einer Zeiterfassung. Bei der Endebuchung dieser Mehrfachen Lose, wird die Arbeitszeit zu gleichen Teilen auf die angegebenen Lose gebucht.Nur für die Erfassung von Fertigungs-Losen möglich. | ||||
| $G | Einzelbuchung auf Los mit Arbeitsgang anstelle der Tätigkeit. Code für Arbeitsgang: $Gxx.yy … xx Arbeitsgang numerisch, yy Unterarbeitsgang numerisch | ||||
| $X0artikelnummer | Anzeige des Artikelstammblattes | (x) | |||
| $X1losnummer | Anzeige des Druckes der Nachkalkulationdes Loses | x | (x) | ||
| $L…$MAT | Materialbuchung auf das Los | x | |||
| $I | Artikelnummer mit Seriennummer oder Chargennummer nach der Artikelnummer muss | und die CNr bzw. CHG kommen. | x | |||
| Artikelnummer | Artikelnummer ohne LeadIn und ohne SNR, CHG | x | |||
| VDA4992 | VDA 4992 Mat-Label lt. VDA Norm | x | |||
| Spezialstring | Artikel<Tab>Menge<Tab>Charge@ | Spezialartikelerfassungsstring mit Menge und Chargennummer. ACHTUNG: Es dürfen KEINE <Tab> in der Artikelnummer erlaubt sein | x |
Weitere definierte Barcode LeadIns, welche für zukünftige Verwendungen definiert sind. Diese sind derzeit nicht umgesetzt.
| Lead In | Bedeutung | mobile App |
|---|---|---|
| $ARZT | Arzt Beginn oder Ende | |
| $KRANK | Krank Beginn oder Ende | |
| $BEHOERDE | Behördengang Beginn oder Ende | |
| $DIENST | Dienstgang | |
| $REISE | Dienstreise Beginn oder Ende | |
| $UEBER | Überstunden Beginn | |
| $URLAUB | Urlaubsbeginn oder Ende | |
| $ und Kundennummer | Kundennummer auf Kundenkarte | x |
| $I123456789012345 | Material Ident danach muss | |
| $$Pdruckerstring | Übersteuerung des Druckers für den Druck steht aktuell nur für Los-Fertigungs-,Ausgabeliste-,Etikette zur Verfügung |
(x) |
| $$Losnummer | Mehrfach Losnummer auf der Ausgabeliste für die Verwendung in der VDA Scan App zur gleichzeitigen Ausgabe und Rücknahme von Chargengeführten Artikeln (Reelid) |
Anmerkung: Dinge wie $BEHOERDE sollten am ZE-Terminal gebucht werden können, aber nur über Sondertätigkeitsbutton, Combobox
ACHTUNG: Es gibt insbesondere für die kombinierten Barcodes zwei Forderungen:
- über den Barcodesanner der verschiedensten Apps Artikelnummer und Chargennummer in einem Zug erfassen, also z.B. $Innnn|chgnr aber
- wie erfasst man dann den Artikel über einen Wedgescanner
Aktuelle Lösung zwei Barcodes andrucken d.h. der kombinierte für die schnelle Erfassung, NUR die Artikelnummer um über Wedge im Client schnell auf den Artikel zu springen.
Barcode Definitionen für Materialbuchungen
In der LosMaterialbuchung, bei SNR/CHG Artikeln
Für die Losmaterialbuchung stehen in Kombination mit Barcode folgende Möglichkeiten zur Verfügung:
- Scann der Artikelnummer im Klartext
- $Innnnn | Seriennummer bzw. Chargennummer
- hier kann in dem nun geöffneten Dialog weitergescannt werden
also z.B. $I4711|1234(CR)$I4711|1235(CR)
Bitte dabei darauf achten, dass die immer der gleiche Artikel ist.
- hier kann in dem nun geöffneten Dialog weitergescannt werden
- ist man im Seriennummern Feld, so kann auch die Seriennummer direkt gescannt werden. Dabei wird die Menge immer mit ein Stück fix angenommen und daher sofort in die Erfassungsliste übernommen
- ist man im Chargennummern Feld, so kann auch die Chargennummer direkt gescannt werden. Danach muss zusätzlich die Menge eingegeben werden.
Von den Barcodes unterstützte Zeichen:
| Barcode | Unterstützte Zeichen |
|---|---|
| Code 39 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ-.$/+%Space |
| Code 128 | !#$%’()0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{ |
| QR-Code | QR-Code unterstützt UTF-8, also, vereinfacht gesagt alle Zeichen die du in Kieselstein ERP eingeben können. |
HINWEIS: Code39 kann keine _______
Wenn nun ein Barcode nicht gedruckt werden kann, so überprüfe bitte die Artikelbezeichnung bzw. den zu druckenden Text auf nicht angeführte Zeichen - vor allem Umlaute.
Drucken von Barcodes aus anderen Programmen:
Manchmal ist es nützlich Barcodes aus anderen Programmen (Textverarbeitung) zu drucken.
Wenn du eine passende TrueType Schrift besitzt, so kannst du den Code 39 direkt als Schrift verwenden.
Hier ist zu beachten, dass Barcodes noch zusätzliche Steuerzeichen am Beginn und am Ende des Codes besitzen. Diese müssen üblicherweise mitgedruckt, also in deinen Zeichen enthalten sein.
Der Code 39 muss in ** eingebettet sein (=VERKETTEN("";D85;"")). Wenn du also die Zahlen 1234 als Barcode ausgeben möchtest, müssen die Zeichen 1234 mit dem Code 39 TrueType Font ausgegeben werden.
Erzeugen von VDA / MAT Lables
Eigentlich werden die VDA / MAT Lables durch Variablen in den verschiedenen Reports zusammengestellt. Da man manchmal zum Testen schnell einen Barcode braucht, hier der Link zu einer praktischen Seite. https://label.tec-it.com/de Hier kannst du dir den gewünschten Barcode zusammen stellen. Bitte beachte, das der Barcode nicht normal gedruckt werden kann. Aber: Die modernen 2D Scanner lesen gerade den QR-Code auch sehr gut vom Bildschirm ab.
Warum werden manche Artikelnummern nicht als Barcode gedruckt?
Es kommt z.B. beim Ausdruck der Inventur Zählliste dazu, dass manche Artikel nicht als Barcode angedruckt werden. Ursache ist hier immer dass in der Artikelnummer für den Barcode ungültige Zeichen enthalten sind.
So ist in der zweiten Artikelnummer ein Umlaut enthalten, welcher im Code 39 nicht gedruckt werden kann.
Siehe dazu auch [erlaubte Zeichen in der Artikelnummer](../artikel/index.htm#Erlaubte Zeichen in der Artikelnummer).
Barcodes sind schlecht lesbar, können mit einem CCD Scanner nur mühsam gelesen werden
Für die Akzeptanz der Zeiterfassung, bzw. der gesamten Datenerfassung mittels Barcode ist das schnelle und sichere Lesen der Codes von enormer Bedeutung. Um dies zu erreichen beachte bitte Folgendes:
Die Codes müssen etwas schmäler sein als der CCD-Scanner. Wir setzen üblicherweise Touchscanner ein, also bitte sehr nahe an den Barcode heranführen und dann den Scannknopf drücken. Es hat sich bewährt, während des Scannens eine leichte Bewegung nach unten zu machen.
Zu den Codes selbst: Diese MÜSSEN vor und nach dem eigentlichen Code eine Ruhezone haben. D.h. links und rechts vom Barcode darf im Bereich von ca. 1cm kein Druck sein. Bitte beachte, dass auch Papierkanten als Linien gelesen werden und daher den Barcode verfälschen können, unlesbar machen.
Oft werden die Barcodes auch in Klarsichtfolien eingelegt. Es gibt nur wenige Klarsichtfolien, die für den Einsatz von Barcodes geeignet sind. Bitte achte darauf, dass die Folien
- nicht spiegeln und
- trotzdem einen klaren/scharfen Blick (für den Scanner) auf den Barcode ermöglichen.
Wenn Codes in Folien schlecht lesbar sind, so prüfe bitte zuerst, ob der Barcode direkt vom Papier gut lesbar ist. Ist dies der Fall, so muss eine andere Klarsichtfolie verwendet werden.
Der Scannvorgang sollte bei normalem Licht erfolgen. Bei direkter Sonneneinstrahlung konnten wir bisher keinen Barcode vernünftig einlesen.
Für Einstellung der Barcodescanner siehe auch.
Können auch QR-Codes gedruckt werden oder Datamatrix-Codes?
A: Ja es können auch QR-Codes gedruckt werden. Grundsätzlich können auch Datamatrix-Codes gedruckt werden. Leider ist es so, dass in allen verfügbaren Libraries (Stand Februar 2016) Fehler bei der Verwendung von mehreren * (Sternchen), vor allem wenn diese aufeinanderfolgend sind, enthalten sind. Wir raten daher anstatt des Datamatrixcodes den QR-Code zu verwenden. Der QR-Code hat zusätzlich den Vorteil, dass die mobilen Apps für die Decodierung des QR-Codes optimiert sind und diesen sehr schnell lesen können. Bitte beachte, dass dafür zumindest auch Java 8 auf deinem Kieselstein ERP Server und auf den Client-Rechnern eingerichtet sein muss.
Im Unterschied zu den 1D-Barcodes, Strichcodes, können im QR-Code bis zu ca. 4300 Zeichen eingebunden und decodiert werden. Dies ist auch Abhängig vom zur Verfügung stehenden Platz und der Auflösung des Druckers und der Qualität der ScannEngine des Barcodelesers.
Welche Drucker / Druckertreiber sollten für den Druck von Barcodes verwendet werden?
Von Kieselstein ERP werden Barcodes über den Druckertreiber direkt an den Drucker gesandt. Das bedeutet, dass die Qualität des Barcodes auch von der Qualität des Druckertreibers abhängig sind. In Kombination mit den Barcodedruckern hat sich bewährt anstelle der original Druckertreiber (ZDesigner) Druckertreiber der Firma Seagull zu verwenden. Achte bitte in jedem Falle darauf, dass die Auflösung deines Druckers ausreichend für die Wiedergabe der Barcodezeichen ist. Die oft angetroffenen 8Dot Drucker haben damit 203dpi, 12Dot haben 300dpi. Alles unter 300dpi liefert meist unzufriedenstellende Ergebnisse.
Wichtig
Prüfe die Lesbarkeit der Etiketten bevor du mehrere Etiketten auf den verschiedensten Paketen, Lagerplätzen usw. anbringst. Wir haben da schon einige interessante Effekte gehabt. Prüfe jede Etikette auch in der wirklichen Anwendung, bei Sonneneinstrahlung usw..Es mussten leider schon ganze Lageretikettierungen neu gemacht werden, da dies eben nicht beachtet wurde. Das sollte man vermeiden.
Detailbeschreibung zur Installation von Barcodedruckern
Da wir immer wieder danach gefragt werden, nachfolgend eine kompakte Beschreibung was bei der Einrichtung von Barcodedruckern im besonderen zu beachten ist, wobei wir hier von Windows-Betriebssystemen ausgehen. Die Installation in Linux bzw. MAC OSX Systeme setzt immer sogenannte CUPs Treiber voraus. Solltest du Bedarf in dieser Umgebung haben, wenden dich vertrauensvoll an uns.
-
Wenn Drucker von mehr als einem Rechner erreicht werden sollten, nutze nur Drucker die einen vollwertigen Netzwerkanschluss besitzen. Für Linux/OSX Umgebungen, können ausschließlich Drucker mit IP Anschlüssen verwendet werden.
-
Achte auf eine ausreichende Auflösung, wie oben beschrieben bitte mindestens 12Dot
-
Lade die neueste Version der kostenlos zur Verfügung gestellten Druckertreiber der Firma Seagull.
-
Installiere den richtigen Treiber, achte dabei auch auf Kleinigkeiten in der Bezeichnung. So beachte bitte bei Zebradruckern auf die teilweise unterstützten unterschiedlichen Druckersprachen. Manche Zebradrucker können nur ZPL (Zebra Programing Language) manche nur oder zusätzlich EPL (Epson Programming Language). Nur wenn dein Drucker die richtige Sprache spricht wird er auch das gewünschte ausdrucken.
-
Wähle nun die Druckereigenschaften (Rechtsklick auf das Drucker-Symbol unter Geräte Drucker, etwas vom Betriebssystem abhängig)
-
Du siehst nun die Werbeinfo von Seagull und vielen Dank für die guten und stabilen Treiber. Wechsle auf den Reiter Allgemein und klicken unten auf Einstellungen
-
Nun kommt ein weiteres Fenster, wählen hier den Reiter Seite einrichten.
-
Klicke auf Neues (Etikett) oder bearbeite das bestehende durch Klick auf bearbeiten. Gib Name und Abmessungen in mm ein. Bitte beachten, dass die eingegebenen Etikettenabmessungen um eine Kleinigkeit größer (höher / breiter) als in deinem Kieselstein ERP Etikett definiert sein müssen.
-
Speichere die Einstellungen durch Klick auf Ok und (im eigentlichen Eigenschaftenfenster) auf übernehmen.
-
Wähle nun Testseite drucken. Es muss der Testdruck exakt am linken oberen Rand der Etikette gedruckt werden. Sollte dies nicht so sein, bitte prüfen deine Etikettendefinitionen.
-
Voraussetzung dafür ist, dass die Startposition deiner Etikette vom Drucker her richtig eingestellt ist. Sollte dies nicht so sein, betätige bitte einmal den Formfeed / Seitenvorschub.
-
Manchmal ist jedoch auch der Positionserkennungssensor falsch oder die Etikettenbahn wurde nicht durch / unter dem Sensor durchgeführt oder in den Einstellungen im Reiter Etikett ist bei den Einzugsoptionen ein falscher Wert ausgewählt.
-
Was noch so eintreten kann
-
Der Drucker druckt zu hell.
Stelle in den Einstellungen unter Optionen die Helligkeit etwas höher ein. Tasten dich bitte Schrittweise an den Idealwert heran. Wenn zu schnell auf zu heiss gedreht wird, kann das TTF (ThermoTransfer) Band schmelzen, also abreissen. Eine mögliche Abhilfe ist auch die Etikette langsamer zu drucken, reduziere also im gleichen Reiter die Geschwindigkeit.
Optimiere die beiden Werte für deine Bedürfnisse. -
Prüfe nach der Einrichtung der Drucker ob das gewünschte Etikett wirklich in der richtigen Lage und in der richtigen Größe / Position ausgedruckt wird. Beachte, dass die Einstellungen der Etiketten Benutzerabhängig hinterlegt werden. D.h. stelle sicher, dass der/die Druckende auch unter dem Namen angemeldet ist unter dem du die Etikette eingerichtet haben.
Kann man Etikettendrucker per Fernwartung einrichten?
Technisch gesprochen ist das kein Problem. Nachdem aber auch bei den Etiketten geprüft werden muss ob diese in der richtigen Lage usw. ausgedruckt werden, empfiehlt es sich dies vor Ort durchzuführen oder von einem fähigen Menschen durchführen zu lassen.
Können Etikettenformulare per Fernwartung eingerichtet werden?
Auch das, technisch kein Problem. Wenn dies von dir als Anwender wirklich gewünscht wird, weil z.B. die Reisezeiten einfach zu lange wären, bitte übermittle uns einen Etikettenentwurf, der wirklich auf den Millimeter stimmt. Nur so können wir halbwegs effizient die Etiketten per Fernwartung einrichten. Es muss dazu in jedem Falle jemand vor Ort sein, der den Ausdruck der Etikette(n) überprüft und dann in der Lage ist exakte Angaben zu machen. Unter exakt verstehen wir wirklich, dass die Verschiebung der Felder in mm angegeben wird. Angaben wie etwas größer, ein bisschen nach links signalisieren uns zwar deinen Wunsch, verursachen aber ein, nein nicht so weit, noch größer, also eine Vielzahl an Durchläufen.
Einlesen von Zahlschein-QR-Codes
Um dies auch einlesen zu können benötigst du einen Wedge-fähigen 2D Barcodescanner. Bei den von uns verwendeten Gryphon GD4400, muss dieser zusätzlich auf Wedge Send Control Characters = 01 programmiert werden, um auch die im QR-Code enthaltenen Steuerzeichen an die Empfangsroutine durchzureichen.
10.1 - Konfiguration verschiedener Barcodescanner
Konfiguration verschiedener Barcodescanner
Da man immer wieder nach den wesentlichen Konfigurationscodes für die Barcodescanner sucht und die vom Hersteller mitgelieferten Scann-Codes natürlich nicht zur Hand hat, anbei die von uns üblicherweise benötigten Codes, ohne jeglichen Anspruch auf Vollständigkeit etc.
Wir setzen in der Regel Barcodescanner von Datalogic ein. Diese bieten eine sehr gute Leseleistung bei einem angemessenen Preis.
Genereller Reset des Barcodescanners
Wenn dein Scanner überhaupt nicht mehr das macht was du möchtest, hilft meist der Reset auf Factory Default. Geht auch das nicht, kannst du es mit fünf Sekunden halten der Scanntaste versuchen. Manchmal hilft auch eine Kombination aus Scanner abstecken. Scanntaste drücken und halten und dann wieder anstecken und noch immer einige Sekunden (> 5) halten. Der Scanner meldet sich mit einem Spezialbeep und machte einen kompletten Reset.
Quickscann
Der Quickscann ist ein Scanner für Ein-Dimensionale Barcodes, gerne auch Strichcodes genannt. Hinweis: Es ist normal, wenn die Strichcodes nicht vom Bildschirm abgelesen werden können. Hier hilft nur ausdrucken. Am Papier lesen die Ein-Dimensionalen Scanner deutlich besser.
Factory Default
ACHTUNG: Dieser Reset ist trotzdem von der Schnittstellen Konfiguration abhängig, also welche du gerade gewählt hast.

USB COM Standard
Damit wird die COM-Schnittstelle auf deinem PC emuliert. Dies ist der von uns für die Terminals verwendete Modus.

USB Wedge
Wenn du den Scanner z.B. für die Inventur-Zählliste nutzen möchtest, muss dieser eine Tastatur emulieren. Das sogenannte Wedge-Interface. Dies wird mit folgendem Code aktiviert.

ACHTUNG: Du musst dazu auch immer dein Tastaturlayout angeben. D.h. wenn z.B. bei der Losnummer anstelle des / ein - kommt, oder statt dem Z ein Y ist das Tastaturlayout falsch.
Countrymode, Tastaturlayout
- Enter Programming Mode

- Deutsches Tastaturlayout

Und danach wieder Enter/Exit Programming Mode
Gryphon
USB COM Standard

USB Wedge

Countrymode, Tastaturlayout
- Enter Programming Mode

- Deutsches Tastaturlayout

Und danach wieder Enter/Exit Programming Mode
Es geht absolut nichts mehr
Sollte das tatsächlich passieren, was ein Anwender in den 40Jahren einmal geschafft hat, so gibt es von Datalogic auch noch den Alladin, mit dem der Scanner komplett zurückgesetzt werden kann.
11 - Drucker einrichten
Drucker unter Linux einrichten
Drucker unter Linux einrichten
Ab CentOS 5 können IP Drucker am einfachsten mit printconf eingerichtet werden. Hier stehen fast alle Druckertreiber usw. zur Verfügung. Der Port für die Standard IP Verbindung ist 9100. Siehe dazu auch in den Windowseinstellungen in der Konfiguration des Druckeranschlusses unter RAW Einstellungen, Portnummer.
Alternativ / Einfacher kann der WebMin (https://192.168.8.251:10000/), Hardware, Printeradministration verwendet werden. Hier können, ab CentOS 5 fast alle Druckertreiber usw. ausgewählt werden.
12 - Zeitserver einrichten
Einrichten von Zeitservern
Zeitserver
Gerade in der Zeiterfassung, aber auch für das Zutrittskontrollsystem ist eine exakte amtliche Zeit wesentlich. Stellen Sie daher sicher, dass alle beteiligten Komponenten Zeitsynchron sind.
Beteiligte Komponenten sind:
- Kieselstein ERP Server
- Kieselstein ERP Clients
- Kieselstein ERP BDE Stationen
- Zeiterfassungsgeräte wie das ZE-Terminal, aber auch die Offline-Stifte, ev. mobile Geräte
- Zutrittskontroller
Üblicherweise wird der Kieselstein ERP Server auf die Zeit eines Atomzeit-Server im Internet synchronisiert.
Alle anderen Netzwerkkomponenten werden auf diesen Server sychnronisiert.
Eine Auswahl der verfügbaren Zeitserver finden Sie unter http://www.pool.ntp.org/zone/europe oder unter http://timeserver.verschdl.de/
Wir verwenden üblicherwiese:
| Server | IP (V4) |
|---|---|
| ntp0.fau.de (ntp0-rz.rrze.uni-erlangen.de) | 131.188.3.220 |
| ntp1.fau.de (ntp1-rz.rrze.uni-erlangen.de) | 131.188.3.221 |
| ntp2.fau.de (ntp2-rz.rrze.uni-erlangen.de) | 131.188.3.222 |
| ntp3.fau.de (ntp3-rz.rrze.uni-erlangen.de) | 131.188.3.223 |
| ptbtime1.ptb.de | 192.53.103.108 |
| ptbtime2.ptb.de | 192.53.103.104 |
Synchronisierung der Server mit den Atomzeitservern
Windows 2003
- w32tm /config /syncfromflags:manual /manualpeerlist:ts1.univie.ac.at
- w32tm /config /update
- w32tm /resync
Linux
Eventuell muss der NTP Dienst zuerst installiert werden. In unseren Linux-Installationen ist dieser bereits eingerichtet. Installation mit
- yum install ntp
- chkconfig --levels 235 ntpd on
Bei bereits laufendem ntp Dienst:
- service ntpd stop
- ntpdate IP-Adresse ... verwenden Sie hier die Adresse eines erreichbaren NTP Servers
- service ntpd star
- Ist der Zeitdienst (ntpd) wirklich synchron ?
- ntpq -p
MAC OS X
Öffnen Sie die Systemeinstellungen und klicken Sie auf Datum und Uhrzeit. Wählen Sie den Reiter Datum & Uhrzeit und setzen Sie einen Haken bei Datum & Uhrzeit automatisch einstellen. Wählen Sie einen Server aus der Liste aus oder geben Sie den Namen eines NTP Server, z.B. aus obiger Liste, an. Siehe dazu auch: http://docs.info.apple.com/article.html?artnum=61273
Ergänzend
Siehe dazu auch: http://www.msxfaq.de/verschiedenes/timesync.htm
13 - Dokumentenscann einrichten
Einrichten von Dokumentenscann
Scannen mit NAPS2
- Stichwort: TWAIN Scanner
- Herunterladen von https://www.naps2.com/ und komplett installieren
- nun gibt es im Verzeichnis das NAPS2.exe. Dies starten und den Scanner wie gewünscht konfigurieren und das Profil unter einem guten einfachen Namen anlegen / speichern
- nun unter Arbeitsplatzparameter, PFAD_MIT_PARAMETER_SCANTOOL das Programm
"C:\Program Files (x86)\NAPS2\NAPS2.Console.exe" -p "TW-Brother MFC-J6910DW LAN" -o
-
eintragen. -p ist das Profil welches mit dem naps2 erzeugt wurde.
Macht schön komprimierte PDFs die eine sehr gute Größe (eigentlich Kleinheit bei Farbe und 300dpi) haben. -
siehe auch https://www.naps2.com/doc-command-line.html
14 - EMail Versand einrichten
Einrichten des EMail Versandes
Nach der Installation sollte oft sehr rasch der EMail Versand eingerichtet werden.
Es sind dabei einige Dinge zu beachten:
- Sind die Automatik Jobs aktiviert SMTP und IMAP und der Automatikjob an und für sich aktiviert
- hat der lpwebappzemecs überhaupt Rechte, vor allem wenn ein weiterer Mandant eingerichtet wurde
- sind die EMail Parameter für jeden zu sendenden Mandanten hinterlegt
- geht der EMail Versand aus System, Parameter,
Hinweis:
Wenn man beim Testen bereits EMail-Versandaufträge erzeugt hat, aber obige Parameter nicht richtig waren, so diese Versandaufträge löschen und neu erzeugen. Es werden einige Dinge intern zwischengespeichert, die die Änderung nicht mitbekommen.
Kommt beim Test-EMail-Versand die Fehlermeldung
nested exception is:
javax.net.ssl.SSLException: Unsupported or unrecognized SSL message
at com.sun.mail.smtp.SMTPTransport.openServer(SMTPTransport.java:2120)
So wurde die falsche Verschlüsselung für den SMTP Versand ausgewählt. Versuche einfach die andere Verschlüsselung.
Interner Versanddienst
Integriert im Kieselstein ERP Applikations Server steht eine direkte SMTP und IMAP Anbindung für den Versand der E-Mails und gegebenenfalls auch Faxe zur Verfügung.
Voraussetzungen
Kieselstein ERP Interner VersanddienstE-Mail SMTP und gegebenenfalls IMAP Server mit den entsprechenden Zugangsdaten
- Personal IMAP Zugangsdaten (Reiter Parameter) und E-Mail-Absenderdaten sind eingestellt
- Personal IMAP Abholungsdaten (Inbox) ist eingerichtet
Funktionsweise des internen Versanddienstes / Mailversand
- a.) E-Mail Versand
Das E-Mail wird mit einem der Kieselstein ERP Module erzeugt und durch den Klick auf Senden in den Versandauftrag übertragen.
Hier ist üblicherweise (Parameter DELAY_E_MAILVERSAND) ein Zeitversatz von 5 Minuten eingetragen. Nach dem Ablauf dieser Zeit wird das E-Mail mit den eingestellten SMTP Parametern per SMTP versandt.
War der SMPT-Versand erfolgreich wird das E-Mail in den gesendet Ordner des jeweiligen Sendenden abgelegt.
Also:
- a1.) Versandauftrag erzeugt
- a2.) SMPT Versand
- a3.) IMAP Ablage in gesendete Objekte
Hinweis: Beachte, dass der Versanddienst als Automatikjob ausgeführt wird. D.h. es muss der Automatikjob aktiviert werden. Siehe dazu.
Es ist der SMTP Versand von der IMAP Ablage datentechnisch komplett getrennt, daher wird ein per SMTP versandtes EMail aus dem Postausgang nach gesendet verschoben. Solange es noch nicht in der IMAP Ablage des jeweiligen Benutzers abgelegt werden konnte, bleibt es hier im Status Teilerledigt  stehen.
stehen.
Erst nachdem auch die IMAP Ablage gemacht wurde, wird der Status auf Erledigt = Versandt geändert.
Zusätzlich sieht man in der Statuszeile des Versandauftrages ganz unten den detaillierten Status des jeweiligen Versandauftrages, also gegebenenfalls auch eine entsprechende Fehlermeldung.
Hinweis: Von ev. Fehlermeldungen des vorgelagerten Servers werden nur die ersten 1000Zeichen abgespeichert und angezeigt.
- b.) E-Mail Empfang
Start des E-Mail Clients
 und Klick auf Neue Nachrichten vom E-Mail Server laden
und Klick auf Neue Nachrichten vom E-Mail Server laden  oder automatisch abholen ist angehakt.
oder automatisch abholen ist angehakt.
Es werden die E-Mails aus dem hinterlegten IMAP Verzeichnis abgeholt. Dieses geht von der Standard Inbox des jeweiligen Benutzers aus. Wir raten hier z.B. ein (Imap) Verzeichnis ToKieselstein anzulegen und dieses entsprechend beim Personal des jeweiligen Benutzers unter Daten, IMAP-Inbox einzutragen.
Bei der Übernahme der IMAP Daten aus dem IMAP Server wird darauf geachtet, dass von den Dateninhalten keine Duplikate übernommen werden. Das bedeutet E-Mails mit gleicher Message-ID werden nur einmal übernommen.
Also:
- b1.) IMAP – Inbox-Verzeichnis pollen
- b2.) Daten nach Kieselstein ERP E-Mail-Datenbank kopieren
Konfiguration
Die Parametrierung des internen Versanddienstes erfolgt im Modul System, unterer Reiter Parameter. Gibt man hier zur Einschränkung der Suchergebnisse unter Kategorie Versand ein, so werden die erforderlichen Parameter für den internen Versanddienst gelistet. Solltest du diese Parameter nicht vorfinden, so ist in deiner Kieselstein ERP Installation dieses Modul nicht freigeschaltet. Bitte wenden dich an deinen Kieselstein ERP Betreuer.
Einfache Konfiguration
Alternativ kann durch aktivieren des Parameters MAIL_SERVICE_PARAMETER=1 mit anschließendem Schließen und Neustarten des Moduls System in den Reitern 4 (E-Mail) bzw. 5 E-Mail Admin  die Parametrierung vorgenommen werden. Dies ist vor allem für deinen IT-Administrator gedacht.
die Parametrierung vorgenommen werden. Dies ist vor allem für deinen IT-Administrator gedacht.
Vom Ablauf her, werden die Parameter im Reiter 4 eingestellt und dann der tatsächliche EMail Versand im Reiter 5 durch klick auf das EMail Symbol  getestet. In diesem EMail Versand werden auch die Fehlermeldungen beim Versand entsprechend zurückgegeben, womit für einen erfahrenen IT-Admin die Parametrierung für die verschiedensten EMail Dienste einfach durchgeführt werden kann.
getestet. In diesem EMail Versand werden auch die Fehlermeldungen beim Versand entsprechend zurückgegeben, womit für einen erfahrenen IT-Admin die Parametrierung für die verschiedensten EMail Dienste einfach durchgeführt werden kann.
Einrichten des SMTP Servers:
Durch die Parametrierung des SMTP Servers, wird der interne Versanddienst aktiviert.
| Parameter | Beispiel | Beschreibung |
|---|---|---|
| SMPTSERVER | smtp.meinefirma.localodermail.firma.local | Servername des Postausgangs Servers (SMTP) (oder IP-Adresse) |
| SMTPSERVER_BENUTZER | Falls der Postausgangsserver eine Authentifizierung erfordert ist diese hier einzutragen.Benutzername | |
| SMTPSERVER_KENNWORT | Kennwort | |
| SMTPSERVER_FAXDOMAIN | fax.local | Unterstützt der Smtpserver eine Faxweiterleitung / Faxgateway so wird diese Funktion durch einen Eintrag der entsprechenden Domain aktiviert. |
Anmerkung zum Faxgateway / Faxweiterleitung:
Die Faxnummern werden beim Versand eines Faxes automatisch um diese Domain ergänzt und das Fax wird als E-Mail an den SMTP Postausgangsserver versandt. Der eigentliche Versand des Faxes muss durch den Faxgateway erfolgen.
Einrichten der IMAP Anbindung:
Durch die IMAP Anbindung, wird nach erfolgtem SMTP Versand eine Kopie des E-Mails im IMAP Postfach des Benutzers abgelegt. Wenn diese Funktion nicht benötigt wird, sind die Parameter leer zu lassen.
Die Parametrierung ist zweigeteilt:
- a.) die generelle Einbindung, diese findet man ebenfalls unter System, Parameter, Kategorie Versand
- b.) die Definition der Postfächer für jeden Benutzer, diese findet man im Modul Personal, im oberen Modulreiter Parameter.
Parametrierung IMAP Anbindung
| Parameter | Beispiel | Beschreibung |
|---|---|---|
| IMAPSERVER | mail.firma.local | Name des Imapservers (oder IP-Adresse) |
| IMAPSERVER_ADMIN | Name des Users bei dem Mails und Faxe ohne Angabe eines Absenders abgelegt werden | |
| IMAPSERVER_ADMIN_KENNWORT | ||
| IMAPSERVER_SENTFOLDER | Gesendete Objekte | Name des Ordners für die versandten Mails in der IMAP Struktur |
| MAILADRESSE_ADMIN | Diese Adresse wird beim Faxversand verwendet falls kein Benutzer angegeben ist |
Definition der Personal / Benutzerdaten
| Parameter | Beispiel | Beschreibung |
|---|---|---|
| IMAP-Benutzer | office | Benutzerkonto am IMAP Server |
| IMAP-Kennwort | Kennwort | Kennwort für den Benutzer am IMAP Server.Hinweis: Das Kennwort wird nur mit ** angezeigt. |
Der IMAP Server ist definiert, es werden aber keine E-Mails versandt?
Der interne Versanddienst von Kieselstein ERP funktioniert so, dass zuerst das E-Mail per SMTP Server versandt wird. Hat dies funktioniert, so wird, wenn der IMAP Server definiert ist, eine Kopie davon in das IMAP Konto des Benutzers abgelegt.
Das bedeutet: Bitte prüfe ob der Zugriff auf den SMTP Server mit den Parametern SMPTSERVER, SMTPSERVER_BENUTZER, SMTPSERVER_KENNWORT richtig konfiguriert ist.
Man sieht im System, unterer Modulreiter Versandauftrag, beim jeweiligen Versandauftrag unten den Status. Interpretiere dies diese entsprechend.
Werden Parameter am Versandauftrag verstellt / neu gesetzt, so sollte ein im Postausgang wartender Auftrag mit dem grünen Haken  neu getriggert werden. Es wird dadurch auch die interne Zeitsteuerung neu angestoßen.
neu getriggert werden. Es wird dadurch auch die interne Zeitsteuerung neu angestoßen.
Bei mehreren Mandanten achte bitte darauf, dass alle erforderlichen Parameter sowohl unter System, als auch im Personal je Mandant und Mitarbeiter, der Versenden darf, definiert werden muss.
Voraussetzungen die gegeben sein müssen um E-Mails richtig weiterreichen zu können
Gerade im deutschsprachigen Raum kommt es immer wieder zur massiven Verwirrung, weil der Inhalt von E-Mails nicht richtig weitergereicht wird. Hier kommt erschwerend dazu, dass am E-Mail-Versand doch einige Systeme beteiligt sind.
- Kieselstein ERP -> übergibt das E-Mail an den SMTP Server
- SMTP Server reicht das E-Mail an den Empfänger weiter und bestätigt dass das E-Mail versandt werden konnte
- Kieselstein ERP legt eine Kopie im IMAP Ordner des Versenders ab
- Empfänger öffnet das E-Mail mit seinem Client
Abhängig von dem was gesandt wurde, verhalten sich die Systeme zum Teil sehr unterschiedlich.
Wichtig:
- Derzeit wird E-Mail Text welcher von Kieselstein ERP generiert wird als reiner ASCII Text übergeben. Dieser Text ist nach UTF-8 codiert.
- Die SMTP Server richten sich normalerweise nach der im Betriebssystem des Servers eingestellten Sprache
- Plain Text E-Mails, wie sie von Kieselstein ERP gesendet werden, werden in den Clients oft unterschiedlich interpretiert / dargestellt.
Daher müssen, damit die E-Mails mit Umlauten auch richtig beim Empfänger ankommen, alle beteiligten Komponenten mit den Vorschriften RFC 2047 und RFC 6152 richtig umgehen können.
Ein wichtiger Punkt ist dabei noch die richtige Codierung der mail.xsl Datei. Diese muss für Windows und Linux auf UTF8 erfolgen, für MAC auf ISO-8859-1 (Ansi). Achte darauf diese XSL Dateien ausschließlich mit geeigneten Editoren zu bearbeiten, wie z.B. Notepad++. Zum Thema SMTP Versand siehe auch.
Fax - E-Mail Gateway
Alternativ zur oben beschriebenen Faxweiterleitung ist auch der Versand eines E-Mails an einen Fax-Mail Gateway möglich. Auch hier wird ein E-Mail mit PDF Anhang an eine bestimmte Adresse versandt, es sind jedoch im Betreff die entsprechenden Daten enthalten. Der Aufbau ist wie folgt:
E-Mail Empfängeradresse, so wie unter SMTPSERVER_FAXDOMAIN angegeben.
Betreffzeile: Passwort internationaleNummer; Rückmeldungstext für Bestätigung
Für die Aktivierung dieser Funktion müssen die folgenden Parameter (Kategorie Versanddienst) entsprechend eingestellt sein:
- SMTPSERVER_FAXANBINDUNG: Wert=1
- SMTPSERVER_FAXDOMAIN: fax.xpirio.com
- XPIRIO_KENNWORT: Kennwort für das Gateway
Fax - Gateway für Faxmaker
Der Faxversand über den Faxmaker ist ebenfalls möglich.
Angeblich ist die für Kieselstein ERP zu verwendende Option immer verfügbar. D.h. es ist für den Faxversand lediglich bei SMTPSERVER_FAXDOMAIN FAXMAKER.COM einzutragen.
In aller Regel macht die Telefonanlage / der Faxmaker die Amtsholung selbst, daher muss der Parameter AMTSLEITUNGSVORWAHL auf ein Leerzeichen gestellt werden. Die Übergabe der Faxnummer mit enthaltenen Leerstellen ist entgegen der Beschreibung von Faxmaker bei der von uns getesteten Version möglich.
Einrichten EMail-Versand per GMail
Um auch über ein GMail Konto EMails aus Kieselstein ERP versenden zu können, hilft eventuell folgende Vorgehensweise:
Nach erfolgter Anmeldung an deinem Google Konto, suche nach den App-Passwörtern. 
Wähle hier nun die App-Art E-Mail aus und lasse dir dafür ein Passwort generieren:
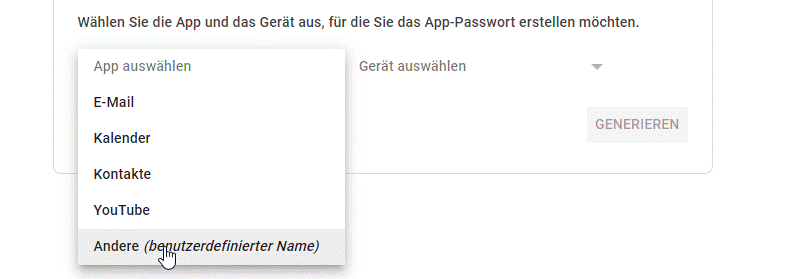
Dieses Passwort muss nun in den Parametern eingetragen werden, also unter
- System, Parameter, E-Mail
Selbstverständlich ist auch der entsprechende GMail Benutzer einzutragen.
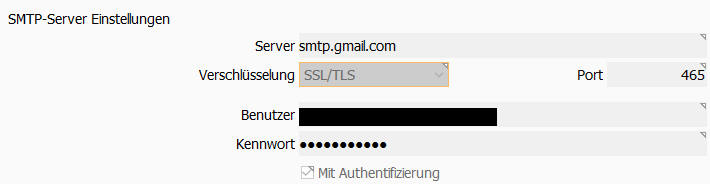
Um nun den Versand per EMail zu testen, wechselst du in den Reiter E-Mail Admin und versuche direkt, also ohne den Umweg über die Automatik des Versanddienstes, durch Klick auf Test E-Mail versenden ein entsprechendes EMail rauszusenden. In den darunter angezeigten Einträgen ist ersichtlich ob dies auch funktioniert hat.
Test E-Mail versenden ein entsprechendes EMail rauszusenden. In den darunter angezeigten Einträgen ist ersichtlich ob dies auch funktioniert hat.
Der Sende-User
Damit die Emails versandt werden können, muss sich ein besonderer User an deiner Kieselstein ERP Installation anmelden können.
Dies ist der User lpwebappzemecs, mit dem Passwort lpwebappzemecs.
Wichtig:
Dieser User muss vor dem Versuch des Versendens eines EMails eingetragen sein. Wurde bereits versucht EMails zu versenden und diese gehen im Versandauftrag nicht raus, so hilft nur diese erneut zu versenden. Hintergrund ist, dass auch diese Daten in den Versandaufträgen abgespeichert werden.
Sollte es trotzdem nicht gehen, könnten aus den verschiedensten Gründen noch 0-Byte Files “herumliegen”. In diesem Falle, den Wildfly stoppen, die 0-Byte Files aus standalone/data löschen und den Server wieder starten.
Wenn der obige User nicht konfiguriert sein sollte, so steht im Serverlog ungefähr folgender Eintrag:
2024-04-26 16:55:10,479 ERROR [org.jboss.as.ejb3.timer] (EJB default - 4) WFLYEJB0020: Error invoking timeout for timer: [id=3e45d60d-ff9e-4fb3-8473-d083cf1f2077 timedObjectId=lpserver.ejb.ShopTimerFacBean auto-timer?:false persistent?:true timerService=org.jboss.as.ejb3.timerservice.TimerServiceImpl@60767998 initialExpiration=Fri April 26 16:55:10 CEST 2024 intervalDuration(in milli sec)=0 nextExpiration=null timerState=CANCELED info=null]: javax.ejb.EJBException: java.lang.NullPointerException at org.jboss.as.ejb3.tx.CMTTxInterceptor.handleExceptionInNoTx(CMTTxInterceptor.java:212) at org.jboss.as.ejb3.tx.CMTTxInterceptor.invokeInNoTx(CMTTxInterceptor.java:264) at org.jboss.as.ejb3.tx.CMTTxInterceptor.notSupported(CMTTxInterceptor.java:316)
Eventuell steht da noch zusätzlich:
2024-04-26 16:59:10,505 ERROR [com.lp.server.shop.ejbfac.ShopTimerFacBean] (EJB default - 9) Das wechseln des Mandants schlug fehl: com.lp.util.EJBExceptionLP: javax.persistence.NoResultException: No entity found for query
at com.lp.server.benutzer.ejbfac.BenutzerFacBean.benutzerFindByCBenutzerkennung(BenutzerFacBean.java:545)
Einstellungen für Office365
Um mit dem Office 365 im Auftrag von (SendAs) senden zu können, muss bei jedem Benutzer unter dessen Adresse man senden will, derjenige eingetragen werden der im Namen des Benutzers senden will.
Z.B. wenn info@kieselstein-erp.org erlaubt dass von office@kieselstein-erp.org gesendet werden darf, dann muss bei office@ die info eingetragen werden (und nicht umgekehrt, was der deutschen Denkweise entsprechen würde).
15 - Praktische Zusatztools
Parktische Zusatztools
Wir dürfen immer wieder kleine praktische Tools für unsere Anwender und Mitglieder erzeugen.
Hier eine Auflistung welche Tools aktuell zur Verfügung stehen
XLS je Blatt verschlüsselt als PDF ablegen. -> Anwendungsfall, Lohnverrechung im XLS
Aufgereihte Lieferanten Angebotspositionen als Kieselstein-ERP Lieferantenimport File zur Verfügung stellen, mit Angebotsnummern Ergänzungsscript
Opticon Reader App
Bildschirmschoner mit guter HTML Darstellung
Anwesenheitsliste, Proxy-Server
Backup-Liste für Starface Telefonanlagen
16 - Tipps und Tricks
Tipps und Tricks rund um dein ERP System
Nachfolgend eine lose Auflistung von Lösungen, die sich im Alltag herauskristalisiert haben.
Memor1 scannt zwar, die App reagiert aber nicht
Mögliche Ursache: Die Pre und Post-Codes sind aktiviert. Siehe dazu Am Memor1 = Android, Einstellungen, Scanner Settings, Formating, und Pre- und Postfix Wenn da Einträge drinnen sind werden diese mitgesendet aber gegebenenfalls nicht angezeigt. Äußert sich ev. auch dadurch, dass man, wenn man die Artikelnummer editiert, geht es auf einmal.
17 - Installation Hilfeeditor
Wie die Hilfe bearbeiten
Der eigentliche Editor
Für das Editieren der Hilfeseiten aufgrund eines Vorschlages von Steffen Bätz wird das Visual Studio Code mit MarkDown verwenden.
Visual Studio Code herunterladen = https://code.visualstudio.com/download
Starten, bei der Frage nach den Themes habe ich solarized Light eingestellt, bzw. links unten das Zahnrad, Designs, Farbdesigns und dann Light + V2  . Ist am ehesten für mich lesbar.
. Ist am ehesten für mich lesbar.
Wenn man nun das Preview Fenster auch sehen will, so aus dem Text-Editor Strg+K und dann V drücken. So kommt rechts ein zweites Fenster, in dem man die Preview sieht.
Achtung: jetzt wieder in das linke Editor Fenster wechseln, sonst ändert man den Inhalt des Previews, was man ja nicht will.
Also immer im linken Fenster arbeiten.
Eine Beschreibung der vielen Text-Commandos siehe z.B. https://www.markdownguide.org/basic-syntax
Für Kopieren der Bilder aus Zwischenablage siehe
Zeichnen
Zusätzlich noch das Drawio Plugin für Visual Studio Code einrichten.
Man muss dann die Files mit filename.drawio.svg benennen, dann kann man diese direkt bearbeiten.
Beispiel:

d.h. das File dann im Verzeichnisbaum doppelklicken (ein bisschen Geduld) und dann im drawio bearbeiten. Zum Speichern auf Datei, Save gehen (Strg+S geht nicht).
Formeln
Darstellen von Formeln usw.. Dafür einbinden von Latex um die Formeln darzustellen. https://www.docsy.dev/docs/adding-content/diagrams-and-formulae/
Denk daran die ..\user-doc\config.toml zu ergänzen.
Latex aktivieren für Formeln
[params.katex]
enable = true\
Commandos / Basic Syntax
für Visual Studio Code
https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf
für MarkDown
https://www.markdownguide.org/basic-syntax oder auch https://markdownmonster.west-wind.com/docs/_4rd0xjy44.htm
Commandos die ich gerne nutze
| Commando | Wirkung |
|---|---|
| Strg+K & V | Preview Fenster in der rechten Bildschirmhälfte. An das Zurückwechseln denken |
| Alt+Strg+V | Einfügen aus der Zwischenablage, je nach Datentyp kommt dann Wenn Bild: Ein Dialog mit dem der Filename angegeben wird. ACHTUNG: Überschreibt ohne Rückfrage. Praktischer Trick wenn überschrieben werden sollte, den Link auf das Bild (Rufzeichen usw.) vorher markieren. Einfügen aus HTML. D.h. das vollständige HTML in die Zwischenablage kopieren.(Vollständiges HTML im Total mit F3 öffnen und dann 1 drücken für reinen Text und dann erst markieren) |
| <br> | Zeilenumbruch erzwingen |
| <u> </u> | Underline ein/ausschalten |
| ** | Fett ein / ausschalten |
| * | Kursive ein / ausschalten |
| - | Auflistung ohne Nummerierung. Wenn unter Einrückungen, dann mit Tab eins weiter nach rechts reinrücken. An den Space danach denken. Geht angeblich auch mit * und + |
| 1. | Auflistung mit Nummerierung (abc geht leider nicht). Auch hier mit Tab für eine Unter-Nummerierung reinrücken. Wichtig der Space nach dem . (und keine Klammer) |
| - a.) | Da wir gerne abc nutzen, vorher das - verwenden und dann manuell das ABC angeben |
| Strg+K & C | Comment: HTML Auskommentieren des markierten Textes. Geht nur innerhalb einer Zeile |
| Strg+K & U | Un-Comment: Die HTML Auskommentierung wieder entfernen |
| [Link](#) | Liefert alle Links innerhalb dieser Datei um hinter dem Link den “GoTo” zu hinterlegen |
| Strg+P | Liste der offenen Files |
| Strg+Shift+P | alle Markdown Befehle |
| ``` | Darstellung von Code-Blöcken ohne Formatierung durch Markdown muss ein- und aus-geschaltet werden |
| Strg+Ö | Startet das Terminal = Windows PowerShell und dann ins Laufwerk wechseln, aufs Verzeichnis gehen (cd .\Git_KES\user-doc) und dann Hugo starten (hugo server –disableFastRender –navigateToChanged) |
| Strg+Shift+H | Wenn links oben  das Verzeichnis der gesamten Dokumentation (Content) ausgewählt ist, so kann damit ein replace in allen Files vorgenommen werden. das Verzeichnis der gesamten Dokumentation (Content) ausgewählt ist, so kann damit ein replace in allen Files vorgenommen werden. ACHTUNG: es gibt kein Undo und wenn man sich vertippt hat, ist es in allen Dateien so. |
vom htm zum RelRef
Eine Beschreibung wie man die einmalige Aktion vom Anker <a </a bzw. *.htm zum relref kommt. Ich nutze dafür Tastentrick.de, kostet 30,- € und habe auf die F11 die Mustersequenz hinterlegt.
D.h. zuerst suchen in allen *.md Dateien nach .htm mittels Totalcommander. Liefert aber nur eine Liste was noch alles zu übertragen ist. Diese in ein Spreadsheet eintragen. Man kann sich das SpreadSheet mit obigem, Strg+Shift+H ersparen.
Zusätzlich kann MarkDown beim Strg+Shift+H auch Regular Expressions. D.h. man kann damit direkt “Übersetzungen” durchführen. Auch hier ACHTUNG: Es gibt kein Undo.
- Ersetze:

- Durch: (Inhalt des Kommentars)

Die HTML-Erzeugungs-Maschine
Um die gesamte Hilfe als schnelle statische HTML Seite zu bekommen, kommt der Google-Dienst Hugo zum Einsatz. In diesem ist auch eine “Google-” Suche mit integriert, damit Sie rasch zu den gewünschten Themen finden.
Installation von Hugo
- https://gohugo.io/installation/
Die weitere Beschreibung geht von einer Windowsumgebung aus - https://gohugo.io/installation/windows/
- Runtersuchen/scrollen zu Prebuilt binaries und Visit the latest release bzw. die darunter ausgeführten Installations-Punkte ausführen. Denken Sie auch daran die Path Variable zu ergänzen. ACHTEN Sie darauf die extend Version zu verwenden, sonst kommt es zu Fehlern des Hugo. Ev. müssen Sie dann auch noch “npm install postcss-cli” ausführen.
- Nun muss als nächstes go installiert werden. Wählen Sie dafür https://go.dev/doc/install. Nach erfolgreicher Installation starten Sie ein neues Command Fenster und geben go version ein. Nun muss die Versionsnummer angezeigt werden.
- Und nun muss noch NodeJS installiert werden. Wechseln Sie dafür auf https://nodejs.org/en/download/
- In den weiteren Beispielen ist der Hugo Server auf d:\Hugo\hugo.exe und der Inhalt der / dieser Hilfe auf d:\Git_KES\user-doc\content
- Wechseln Sie nun in das Root-Verzeichnis der Dokumentation. Das ist in unserem Beispiel: d:\Git_KES\user-doc\
- Starten Sie nun den Hugo-Server durch die Eingabe von Hugo (ohne alles) und beobachten Sie die Ausgabe. Es wird mit dem Download der eigentlichen Module begonnen. Dies kann je nach Leistungsgeschwindigkeit etwas dauern.
- Sie finden die soeben erzeugte Webseite unter ..\user-doc\public\index.html
- Einfacher ist es wenn Sie den Hugo mit dem Parameter server starten. Damit erhalten Sie nach dem Start die Info: Web Server is available at http://localhost:1313/user-doc/
- Nun starten Sie einen Browser z.B. Firefox oder Chrome und rufen http://localhost:1313/user-doc/ auf Der Hugo Server reagiert innerhalb weniger Sekunden auf Ihre Textänderungen in der Hilfe.
Parameter für den Hugo Server
- –navigateToChanged –> Springe in der HTML Darstellung auf die soeben geänderte Seite
- –disableFastRender –> baut den Index neu auf. Praktisch wenn eine Seite nicht funktionieren will
Update von Hugo
wie oben beschrieben auf latest Release gehen und das passende Zip herunterladen. Z.B. hugo_extended_0.128.2_windows-amd64.zip
Die heruntergeladene Datei entzippen und idealerweise über die bestehende Installation drüber-kopieren.
Danach solltest du in jedem Falle den Hugo mit
hugo server –disableFastRender –navigateToChanged
neu starten. Hier kann es aufgrund der strengeren Prüfung durchaus zu Warnungen und Fehlermeldungen kommen. Diese bitte unbedingt beheben.
Dateistruktur
Für eine effiziente Verwendung mit Hugo müssen einige kleine Konventionen in der Dateistruktur und auch im Inhalt der md Dateien eingehalten werden.
- in jedem Verzeichnis gibt es eine Datei _index.md. Dies ist faktisch die Startdatei dieses Unterverzeichnisses.
- weitere Kapitel kommen in eigene Unterverzeichnisse mit jeweils einer eigenen _index.md Datei. Damit wird erreicht, dass sowohl in VSC als auch in der durch Hugo gerenderten Web-Seite die Bilder dargestellt werden.
- Die Reihenfolge ergibt sich aus …..
- Beachten Sie auch, dass der Kopfblock faktisch die Überschrift des Kapitels ist und somit weitere Unterpunkte nur mehr mit ## geschrieben werden dürfen.
- Damit Hugo diese einbindet, müssen die Kopfinformationen, categorie, tags usw. gegeben sein. Damit erreichen Sie ein automatisches Auflisten in der Menüstruktur. Zugleich bedeutet dies aber auch, dass je eigenes Kapitel ein eigenes Unterverzeichnis mit einer eigenen _index.md Datei erforderlich ist.
- Die Verlinkung unter den Dateien kann auf die ## Überschriften hin erfolgen. Es kann dafür auch der Syntax für Hugo verwendet werden. Siehe https://gohugo.io/content-management/cross-references/.
- Sortierung der Dateien in der linken Auflistung. Diese erfolgt nach Default: Weight > Date > LinkTitle > FilePath.
Einfügen aus Zwischenablage
Ist üblicherweise in Visual Studio Code bereits enthalten. Kopiere das gewünschte Bild in die Zwischenablage und drücken dann Strg+Alt+V
Die Frage ist schlichtweg, wie verwaltet man hier sprechende Filenamen, sonst hat man überhaupt keinen Überblick mehr.
Hinweis: Die Zuordnung von Bildern zu den entsprechenden Inhalten funktioniert nur für die _index.md Dateien. Verwendet man andere Dateinamen, z.B. quasi als Unterfile, werden die Bilder zwar in der Vorschau, aber nicht im mittels Hugo kompilierten File angezeigt.
Zeichnen von Diagrammen usw.
Hier ist das Draw.io Plugin zu empfehlen. http://draw.io/

struktur.drawio.svg und wie geht das jetzt?
Rechtschreibprüfung
Installation der Markdown Erweiterung Code Spell Checker
und Installation der deutschsprachigen Erweiterung https://marketplace.visualstudio.com/items?itemName=streetsidesoftware.code-spell-checker-german
Daran denken, dass man nach der Installation noch einmal auf Extensions geht und mit Rechtsklick auf German Code Spellchecker auf Apply Extension to all Profils wählt, damit das auch in allen Dateien angewandt wird.
Kopieren von (HTML) und Bildern
Markdown Paste von telesoho über Extensions  installieren
installieren
Um HTML zu kopieren, den vollständigen HTML Text inkl. aller HTML Commands markieren, in die Zwischenablage kopieren und in ein Markdown File mit Strg+Alt+V einkopieren. Je nach Datenmenge kann das durchaus einige Zeit in Anspruch nehmen.
WICHTIG: Wenn das Einfügen nicht gehen sollte, am Besten an den Bildern aus der Zwischenablage testen, so liegt das an den Trusted Restrictions.
Trusted Restrictions
Gerade bei neuen Installationen oder Verzeichnissen muss man den Dateien und Verzeichnissen vertrauen.
Gegebenenfalls erscheint am oberen Bildschirmrand ein

Klicke hier auf Manage und gib das gesamte Verzeichnis frei.
Oder du klickst im Menü auf Help und dann Show All Commands
und suchst dann nach Trust.
und wählst nun Manage Workspace Trust.
Hier nun weiter und add Folder, bzw. siehst du hier auch, was schon alles freigegeben ist.
Die meist genutzten MarkDown Steuerzeichen
fett
kursive
fett und kursive
Unterstrichen wird nur durch HTML Steuerzeichen unterstützt.
Blockeinrückungen werden mit > am linken Rand erreicht und werden durch ein weiteres > in einer leeren Zeile wieder beendet.
mehrere Ebenen eben mit mehreren >
Kommentare einfügen
Baut auf der HTML Kommentar-Syntax auf. Direkt im VSC Editor den Kommentar markieren und dann Strg+K und Strg+C bzw. um den Kommentar wieder zu entfernen Strg+K und Strg+U (uncomment)
einige grundsätzliche Regeln
Bilder
Bilder werden immer im jeweiligen Modulordner abgelegt (und nicht im IMG oder Assets Unterordner)
Dateinamen
Werden immer ohne Umlaute / deutsche Sonderzeichen geschrieben. Offensichtlich ist es auch zu empfehlen, anstelle von Leerstellen / Spaces Underlines in den Dateinamen, auch der Bilder, zu verwenden.
Sortierung im linken Auswahlmenü
Um die Sortierung zu erreichen wird nur das Attribut Weight verwendet. Dies definiert die Sortierung innerhalb des jeweiligen vorgängerverzeichnisses
Kapitelüberschriften
Es werden die ## für die (Kapitel-) Überschriften genutzt. Damit kann auch darauf verlinkt werden.
Verlinken
in Unterverzeichnisse absolut
Innerhalb der Dokumentation auf ein völlig anderes Kapitel o.ä. springen. D.h. man geht vom Root der Dokumentation aus.
Beispiel:
Mengeneinheiten springt vom Root weg genau auf die Seite (= Unterverzeichnis) Mengeneinheit. In diesem Verzeichnis muss es ein _index.md geben.
Positionsarten in den Verkaufsmodulen
in Unterverzeichnisse relativ
Vom Verzeichnis dieser _index.md ausgehend in ein Unterverzeichnis.
Beispiel:
Mengeneinheiten springt nur auf die Seite (= Unterverzeichnis) Mengeneinheit. In diesem Verzeichnis muss es ein _index.md geben.
Bedenke: Bei eindeutigen UNterverzeichnisnamen kann Hugo auch relative Angaben auflösen. Einzig bei mehrdeutigen Unterverzeichnisnamen muss die absolute Pfadangabe gewählt werden.
Kurzfassung zum Einkopieren:
( )
WICHTIG:
Nach dem Lablenamen in eckigen Klammer muss OHNE Space dazwischen in runden Klammern der Aufruf stehen. Hier ist wieder wichtig, dass nach dem Rundeklammer auf ein Space kommt und dann erst die geschwungenen Klammern.
Wird in der Vorschau der Link nicht aufgelöst, so ist in der Regel hier der Fehler zu suchen.
Hinweis:
Es ist die relative Verlinkung zu bevorzugen, da damit auch Verlagerungen / Reorganisation der Verzeichnisstruktur möglich sind, ohne lange die absoluten Pfade korrigieren zu müssen.
Verlinkung auf eine Kapitelüberschrift
Will man eine direkt zu einer Kapitelüberschrift springen ist nach dem Pfad mit # dann die Kapitelübeschrift in Kleinbuchstaben und Spaces gegen - getauscht anzugeben. Sind darin auch noch Umlaute enthalten landet man schnell bei der HTML Notierung. Hier ist am Einfachsten die Seite mit dem Ziellink im Browser zu öffnen und den Link herauszukopieren und entsprechend anzugeben.
Beispiel:
Muster Link direkt zu einer Überschrift
old
- Verweise auf andere Dateien, Unterverzeichnisse sollten mit z.B.Mengeneinheiten gemacht werden. Das Wort in eckiger Klammer wird in der interpretierten Webseite als Link dargestellt, welcher auf das dahinter angegebene Verzeichnis, mit einer _index.md, verweist. relref bedeutet relative Referenz in der gesamten Dokumentation. Beachten Sie: die Verzeichnisnamen und auch die Anker (anchor) müssen immer in kleinschreibung angegeben werden. Zusätzlich muss bei Verwendung der Anker der gesamte Pfad (inkl. Dateiname bzw. Verzeichnis) in Hochkomma gesetzt sein.
Beispiel:
Mengeneinheiten springt nur auf die Seite Mengeneinheit.
Beachten Sie bitte zusätzlich, dass Leerzeichen in den Ankernamen durch - (Bindestrich) ersetzt werden. Praktisch ist:
Hinweis: Beim Einkopieren passiert es immer wieder dass doppelte (( )) Runde Klammer entstehen. Damit geht der Link nicht und zeigt nur den Inhalt an. Es darf nur eine Runde Klammer, Space, 2 x geschwungene Klammer sein.
Verlinkung innerhalb einer Datei selbst
Geht relativ einfach mit eckiger Klammer und der Angabe des Ankers in runder Klammer, beginnend mit #. Tippt man das ein, kommt ab dem # sofort die Auswahliste der Anker innerhalb der Datei. ABER: alles in kleinbuchstaben
und Leerzeichen werden durch - Bindestrich im Link ersetzt. So geht die Verlinkung auf [Link innerhalb der Datei] nicht, aber Link-innerhalb-der-Datei funktioniert wunderbar. Sollte man sich bei einem Link einmal nicht sicher sein, einfach den Link anlegen und speichern und dann im Browser beim Hugo-Link nachsehen.
Verlinkung zum Download einer lokalen Datei
Manchmal möchte man auch lokale Dateien zur Verfügung stellen.
Dies ist meist auch relativ zum Verzeichnis der bearbeiteten md-Datei. Hier gibt man z.B.
den Text was das ist an (siehe auch Jasperstudio).
Mit obigem Link kommt natürlich nicht gefunden.
Tabellen
werden mit
| Spalte 1 | Spalte 2 rechtsbündig | Mittig |
|---|---|---|
| kurz | Zahl | X |
geschrieben. Sollte die Spalte rechtsbündig ausgerichtet sein, dann hinten ein Doppelpunkt. Sollte sie mittig ausgerichtet werden, so :-:
Beschreibung wie ein Artikel aufgebaut sein sollte
- zuerst den Teaser
- Der Schwerpunkt sollte auf jeden Fall auf dem Modul und seinen Funktionen liegen. Beschreiben Sie nur eine Funktion nach der anderen - verraten Sie nicht alle Funktionen
- Dann einen längeren beschreibenden Text und dann die einzelnen Punkte des Moduls
- Das Ziel ist immer zuerst eine Beschreibung zu haben, wofür was gut ist.
Zuerst sehr allgemein und dann detaillierter.
Orientieren auch am Aufbau eines Werbeemails
was noch ganz praktisch ist:
-
Warnung:
Warning
Beachten Sie bitte …. -
Dies dient zu Ihrer Info
Info
Information speziell für Sie / zu diesem Thema -
ganz besonders wichtig, als erstes zu beachten
Primary
This is a Primary. -
Seiteninfo
Hier die Seiteninfo
ToDo vor dem Einchecken
Man hat, um die optische Erscheinungsform jederzeit prüfen zu können, sowieso den Hugo immer laufen. D.h. theoretisch sollten Tipp und Link-Fehler sofort auffallen. Leider ist dem nicht immer so, was vermutlich der Komplexität geschuldet ist.
Daher: Vor dem Einchecken den Hugo beenden und mit Rebuild neu starten.
Dann eventuelle Fehler beseitigen und danach erst einchecken.

Konvertieren mit Hugo, aufbauend auf DocSys
Unsere Einstellungen:
- ..\user-doc\.vscode\settings.json
For large documentation sets we recommend adding content under the headings in this section, though if some or all of them don’t apply to your project feel free to remove them or add your own. You can see an example of a smaller Docsy documentation site in the Docsy User Guide, which lives in the Docsy theme repo if you’d like to copy its docs section.
Other content such as marketing material, case studies, and community updates should live in the About and Community pages.
Find out how to use the Docsy theme in the Docsy User Guide. You can learn more about how to organize your documentation (and how we organized this site) in Organizing Your Content.
Welche Icons werden verwendet?
Selbstverständlich haben wir uns bemüht alle Programmteile in der passenden Lizenz (AGPL) zu verwenden. Daher kommen auch nur freie Icons zum Einsatz. Wir haben dafür https://www.iconfinder.com/search?price=free&license=gte__1 verwendet.
Wo wird die generelle Description eingestellt?
Google nutzt ja sein eigenes Tool um damit auch kurze Infos in den jeweiligen Suchergebnissen anzuzeigen. Die generelle Einstellung findet man unter …/config.toml, hier der Eintrag “description”. Existiert dieser nicht, kommt das Beste HMTL Tool der Welt.
Was sonst noch so alles aufgefallen ist
Anzeige der Links auf den Überschriften
Muss anscheinend extra aktiviert werden:
https://www.docsy.dev/docs/adding-content/navigation/#heading-self-links
18 - Schnittstellen
Schnittstellen zu deinem Kieselstein-ERP System
Nachfolgend eine lose Sammlung von teilweise praktischen Schnittstellen zu deinem Kieselstein ERP-System
Telefonanlage
Einfache Übergabe der im Kieselstein ERP erfassten Telefonnummern, sodass die Telefonanlage dies automatisch einliest. Womit du auf dem Telefon den Namen des Anrufers siehst. Baut natürlich auf den sauber erfassten Telefonnummern auf. Siehe wie Telefonnummern erfassen.
Schnittstellen
In Kieselstein ERP sind eine Vielzahl von Schnittstellen und Datenanbindungen enthalten, welche auch laufend erweitert werden. Dies beginnt bei Importschnittstellen für Artikel, Stücklisten, Partner, Kunden, Lieferanten und geht bis zu komplexen Anbindungen an verschiedenste weitere vor oder nach-gelagerte Systeme.
Importe
- Kassen Importer Oscar und ADS3000
- TrumpfTops
- Sachkonten Import in der integrierten Finanzbuchhaltung im CSV Format. Musterdaten für Österreich und Deutschland siehe Fibu_DE_Muster.csv. Für Schweiz und Liechtenstein siehe Fibu_CH_Muster.csv
Web-Shop Importe
- Shopify Import in den Lieferschein
- WooCommerce in den Auftrag
Fileimporter
Exporte
Bitte beachte ergänzend zu den Exporten, dass grundsätzlich jeder Druck aus Kieselstein ERP auch für Exporte, insbesondere im CSV bzw. XLS Format und natürlich im allseits beliebten PDF Format erzeugt werden können. Darüber hinaus gibt es noch weitere spezielle Anbindungen die hier beschrieben sind.
Bidirektionale Schnittstellen
Bidirektionale Schnittstellen bestehen meist aus einer Kombination von Modulen bzw. Vorgehensweisen die erst in Ihrer Gesamtheit den tatsächlichen Nutzen ergeben.
Schnittstellen zu Elektronik Distributoren
Nachfolgend eine Beschreibung der derzeit realisierten Schnittstellen zu den verschiedenen Distributoren. Bitte betrachten Sie dies auch als eine Auflistung von Möglichkeiten die bereits bestehen, welche wir, für Ihren bevorzugten Distributor gerne erweitern.
Farnell
Für Farnell wurde die Abfrage der kundenspezifischen Artikelpreise und des Versandes von Bestellungen realisiert.
Abfrage der Artikellieferantenpreise
Grundsätzliches: Voraussetzungen
- Zusatzfunktionsberechtigung WEB_BAUTEIL_ANFRAGE
- Parameter ARTIKELWIEDERBESCHAFFUNGSZEIT in Tage
- API-Request werden am Server getätigt. Das bedeutet Ihr Kieselstein ERP Server muss eine Verbindung zum Farnellserver aufbauen dürfen.
- Gepflegte Daten:
Lieferantenartikelnummer und gegebenenfalls Herstellernummer.
Hinweis: Als Lieferantenartikelnummer soll auch wirklich diese und nicht z.B. die Herstellernummer angegeben sein. - mind. Java 1.8.0_101 am Server
Einstellung im Lieferanten
-
Reiter Webabfrage im Lieferanten
-
Default ist
=> kein Eintrag als Weblieferant -
Auswahl von “Farnell API”
-
Angabe der Mindestparameter:
- URL (= https://api.element14.com/catalog/products)
- Api Key (Registrierung über https://partner.element14.com/member/register)
- Abgerufene Region (de.farnell.com)
-
Für kundenspezifische Preise
- Customer ID (Kundennummer bei Farnell)
- Secret Key (erhält man nach Anforderung über Farnell)

-
Webabfrage-Eintrag kann wieder entfernt werden indem auf <LEER> zurückgesetzt wird

Abfrage im Artikellieferanten Ist ein selektierter Lieferant im Artikellieferant ein Weblieferant (= hat einen Eintrag im Lieferant, Webabfrage <> LEER) so erscheint im Detail ein neuer Button  “Webabfrage” und die Felder “Letzte Webabfrage” und “Bestand”. Mit Klick auf die Weltkugel werden die aktuellen Preise und weitere Daten abgefragt.
“Webabfrage” und die Felder “Letzte Webabfrage” und “Bestand”. Mit Klick auf die Weltkugel werden die aktuellen Preise und weitere Daten abgefragt.
Suchparameter
- Artikelnummer Lieferant (des Artikellieferanten, der zum Zeitpunkt der Abfrage gültig ist bzgl. des Gültig-Ab Datums)
- Herstellerartikelnummer Sobald und nur wenn ein eindeutiges Ergebnis erzielt wird, werden die Daten des Artikellieferanten aktualisiert. Geht der API-Request nicht durch (Service derzeit nicht verfügbar, fehlerhafte Parameter,…) wird auch nicht aktualisiert, es erscheint eine entsprechende Meldung.
Aktualisierung Artikellieferant - Regeln
- Maßgebend ist jener Artikellieferant, der zum Zeitpunkt der Abfrage gültig ist bzgl. des Gültig-Ab Datums
- Blieb der Einzelpreis unverändert, so werden die Daten dieses Eintrags aktualisiert. Sonst wird ein neuer Eintrag des Artikellieferanten erzeugt mit Gültig-Ab des Abfragezeitpunkts
Aktualisierung Artikellieferant - Daten - Letzte Webabfrage
- Webabfrage Bestand
- Einzelpreis
- Nettopreis: bei Neuerzeugung = Einzelpreis, bei Update entsprechend Rabatt
- Rabatt = 0, bei Neuerzeugung
- Artikelnummer Lieferant
- Wiederbeschaffungszeit (in Tagen)
- Weblink
- Staffelpreise
Bitte beachten Sie, dass es zwischen Ihrer lagergeführten Mengeneinheit und der bei Farnell verwendeten Mengeneinheit durchaus Unterschiede geben kann. Das bedeutet, dass z.B. ein Schrumpfschlauch mit 5m bei Farnell als 1Stk mit 5m geführt wird, Sie dies in Ihrem Artikelstamm in aller Regel in m (und damit in der Stückliste in mm) bewirtschaften werden. Das bedeutet nun, dass diese Übersetzung der Menge auf die Verpackungseinheit beim Artikellieferanten durch den Anwender selbst gepflegt werden muss. Weiters bedeutet dies, dass der Bestand und die Staffelmengen von den Farnell-Mengen (die auf Basis der Verpackungseinheit sind) in die lagergeführten Mengeneinheiten Ihres Artikelstamms umgerechnet werden. Bitte vermeiden Sie daher an dieser Stelle Definitionen wie 1Stk = 1Stk, denn andererseits benötigen Sie sicherlich 1Stk (Farnell Gebinde) = 1Liter z.B. einer Reinigungslösung.
Da die von Farnell vorgegebene Mindestbestellmenge nicht unbedingt einen festen Zusammenhang mit der von Ihnen gewünschten Mindestbestellmenge haben muss, wird auch diese nicht auf die Daten der Schnittstelle gesetzt.
Um Missverständnisse in der Mengendefinition zu vermeiden raten wir daher von Farnell die (bekannte) Regelung zu verlangen, dass bei unklaren Einheiten Ihre Bestellung auf Halt gesetzt wird, um zu einer Abklärung der Ungenauigkeit von Seiten Farnell abgefordert zu werden.
Aktualisierung Staffelpreise - Regeln
- Maßgebend ist jener Eintrag, der für die aktuell geprüfte Menge zum Zeitpunkt der Abfrage gültig ist
- Bleibt Menge und Preis unverändert, dann auch der Eintrag
- Bleibt Menge bestehen und Preis ändert sich, dann
- a) Gültig Ab < Abfragetag: Bisheriger Eintrag mit Gültig Bis = Abfragetag - 1 und neuer Eintrag mit aktuellem Preis und Gültg Ab = Abfragetag
- b) Gültig Ab = Abfragetag: Bisheriger Eintrag wird mit neuem Preis aktualisiert
- Neue Menge führt zu einem neuem Eintrag mit Gültig Ab = Abfragetag
- Gibt es eine eingetragene Menge nicht mehr, so wird ihr das Gültig Bis = Abfragetag - 1 gesetzt
Automatikjob Webabfrage Artikellieferant
Um nun nicht jeden Artikel einzeln aktualisieren zu müssen, gibt es den Automatikjob Webabfrage Artikellieferant.
Die Definition dafür finden Sie im Modul System, unterer Modulreiter Automatik.
Dieser muss aktiviert werden und wird dann zum gewünschten Zeitpunkt einmal täglich, z.B. in der Nacht ausgeführt.
Es werden dabei folgende Funktionen durchgeführt:
- Es werden alle Artikel eines Weblieferanten abgefragt und aktualisiert
Weblieferant = Lieferant mit einem Eintrag im Reiter Webabfrage - Es gelten bzgl. Aktualisierung die gleichen Regeln wie über den Button im Artikellieferanten
- Wird im Detail des Automatikjobs eine E-Mail-Adresse definiert, so wird nach Durchführung an diese EMailadresse ein Protokoll gesendet.
Protokoll Beispiel:
Protokoll der Durchführung des Automatikjobs Webabfrage Artikellieferant.
Für Lieferant 'Farnell GmbH':
Artikel '1000394NXP': Aktualisiert
Artikel '1000208YAG': Aktualisiert
Artikel '1000795AVX': KEIN ERGEBNIS
Suchparameter: Lieferantenartikelnummer '1657939', Herstellernummer 'null'
Artikel '1000422NXP': MEHRFACHE ERGEBNISSE
Suchparameter: Lieferantenartikelnummer '1301304', Herstellernummer '74HCT14D'
...
Mögliche Fehlermeldungen
-
Die Webabfrage für Artikel ‘0815’ wurde vom API-Server nicht zugelassen. Bitte prüfen Sie die Webabfragezugangsdaten im Lieferanten ‘XY’
=> Lösung: wahrscheinlich stimmen die Parameter im Weblieferanten nicht. -
Die Webabfrage für Artikel ‘0815’ führte zu keinem (od. mehrfachen) Ergebnis. Folgende Suchparameter wurden verwendet: Lieferantenartikelnummer ‘AB’, Herstellernummer ‘CD’ => Lösung: Prüfung der Lieferantenartikel- und Herstellernummer, z.B. ist keine Lieferantenartikelnummer angegebeben oder es wurde darin die Herstellernummer angegeben. Achtung, das sind zwei unterschiedliche Calls gegen den API-Server!
-
Die Webabfrage für Artikel ‘0815’ enthielt ungültige Parameter. Bitte prüfen Sie die Einstellungen im Lieferanten oder wenden Sie an Ihren Kieselstein ERP Betreuer. Bitte senden Sie uns dazu auch die Protokolldatei.
-
Die Webabfrage für Artikel ‘0815’ führte zu einer unerwarteten Antwort: <HTTP Statusnachricht>
=> Lösung: Warten und später wieder probieren. Vor allem bei 503 Service unavailable oder 500 Internal Server Error
Versenden der Bestellungen im XML Format
Für Farnell steht mit dieser Anbindung auch das Versenden von Bestellungen im XML Format zur Verfügung.
D.h. wenn bei einem Lieferanten die API zu Farnell aktiviert ist, so steht beim EMail-Versand der Bestellung neben dem normalen EMail-Versand auch der Versand per XML zur Verfügung. D.h. um die Bestellung im für Farnell lesbaren Format (OpenTrans1.0) zu senden, klicken Sie bitte auf Mit XML senden.
D.h. um die Bestellung im für Farnell lesbaren Format (OpenTrans1.0) zu senden, klicken Sie bitte auf Mit XML senden.
Das bedeutet, dass wie bisher die Bestellung als PDF Datei an das EMail angefügt wird und zusätzlich die XML Datei als weitere Anhang dazugegeben wird. Beide Dateien werden auch in der Dokumentenablage dieser Bestellung abgelegt.
Es sind dazu folgende Daten erforderlich:
- im Lieferanten muss die Kundennummer hinterlegt sein
- für jeden Artikel muss die “Artikelnummer des Lieferanten” (aus Artikellieferant) gesetzt sein Bitte beachten Sie, dass bei den Mengeneinheiten derzeit nur Stk, Meter, Kg, Liter, Stunde und Rolle in das OpenTransFormat übersetzt werden.
Um die EMail-Adresse der Bestellung entsprechend vorzubesetzen, nutzen Sie bitte die Übersteuerungsmöglichkeit der Ansprechpartnerfunktion. Für die richtige Empfänger-EMail-Adresse stimmen Sie sich bitte mit Ihrem Lieferanten ab. Für dien Test der Funktion sollte eine EMail-Adresse verwendet werden, die auch von Ihrem Lieferanten klar als Test deklariert ist.
Wieso werden bei “jeder” Abfrage neue Artikellieferanteneinträge gemacht?
Wie oben beschrieben werden bei Preisänderung zur Dokumentation der Preisentwicklung neue Gültig ab Einträge angelegt.
Was bedeutet Wiederbeschaffungszeit gegenüber der Lieferdauer?
In der Farnell Schnittstelle werden zwei Informationen übergeben. Einerseits der aktuelle Lagerstand und andererseits die Wiederschaffungszeit. Hier ist mit Wiederbeschaffungszeit jene Zeit (in Tagen) gemeint, die Farnell / das Werk benötigt um diesen Artikel wieder zu beschaffen.
Schnittstellen zu Kassenanbietern
Gerade im Handel sind die Übertragung der Artikel an die Kasse(n) und die Übernahme des Tagesprotokolls für die Verbrauchsbuchungen von der Kasse nach Kieselstein ERP vor allem zur Aktualisierung des Lagerstandes wesentlich. Sollten Sie weitere Schnittstellen / Funktionen benötigen, so bitten wir um Ihre Anfrage. Wir unterstützen Sie gerne.
Gastrosoft
Die Schnittstelle zu Gastrosoft besteht im wesentlichen aus zwei Teilen:
- a.) Export der Artikel mit Beschreibungen und Verkaufspreisen. Dies wird durch eine spezielle Preisliste aus dem Artikelstamm realisiert, mit der die Daten im XLS Format übergeben werden.
- b.) CSV-Kassenimport
Diesen Import finden Sie im Modul Los, Menü Los -> Import -> CSV-Kassenimport.
Auswahl eines Ordners, in dem die zu importierenden CSV-Dateien abgelegt sind. Es werden alle CSV-Dateien darin berücksichtigt.
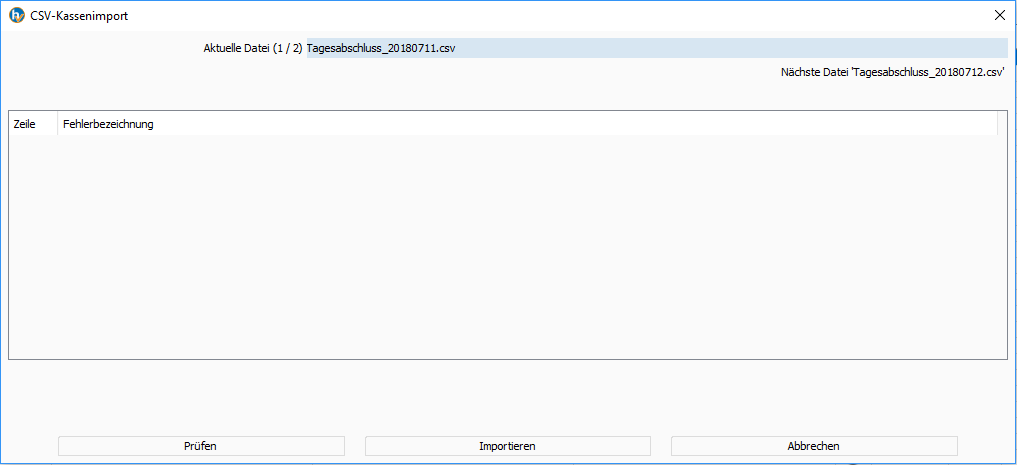
Folgende Spalten werden benötigt:
- Artikel (= Bezeichnung des Artikels)
- Artikel-Nr.
- Menge
- Rech.-Datum
- Rech.-Nr.
- Pos.-Nr.
- Datum (= Abschlussdatum)
- E-Preis (= Einzelpreis)
- G-Preis (= Gesamtpreis)
- Zahlungsart
- PLU
- Hauptwarengruppe
Es wird jede Datei nacheinander manuell importiert. Es empfiehlt sich vor dem Import eine Prüfung zu machen. Etwaige Fehler werden im Importfenster aufgelistet. Wenn es eine spezielle Zeile betrifft mit Zeilennummer. Es wird davon ausgegangen, dass es pro Tagesabschluss eine Datei gibt. Es wird für jeden Dateiimport ein neues Los als freie Materialliste angelegt, mit dem Abschlussdatum des ersten Artikels des Imports als Beginn- und Ende-Datum. Im Projektfeld wird der Tagesabschluss textuell erfasst. Kostenstelle (mit definiertem Sachkonto), Fertigungsgruppe, Montageart muss gegeben sein. Es wird davon jeweils die 1. verwendet. Als Loslager wird jenes mit niedriegstem Loslager-Sort verwendet.
Jede Zeile (also jeder Artikel) wird als Lossollmaterial im Los angelegt. Ist der E-Preis eines Artikels negativ, wird das Sollmaterial als Lagerzugang gebucht, d.h. die angegebene Menge wird mit negativem Vorzeichen berücksichtigt. Ist ein Artikel lagerbewirtschaft, muss genügend im Lager verfügbar sein. Ist keine Artikelnummer angegeben, wird jene Artikelnummer für diese Zeile verwendet, die über den Mandantenparameter KASSENIMPORT_LEERE_ARTIKELNUMMER_DEFAULT_ARTIKEL definiert wurde. Im Kommentarfeld des Sollmaterials wird die Rech.-Nr., der G-Preis und die Zahlungsart geschrieben. Zusätzlich wird bei Verwendung des Defaultartikels die PLU und Artikelbezeichnung hinzugefügt.
Ist ein zu importierender Artikel ein Setartikel, so wird nicht der Artikel selbst, sondern seine Positionen als Lossollmaterial importiert. Die Menge in der Setartikelposition wirkt dabei als Faktor zur Menge aus dem CSV. Als Text des Kommentars wird neben der Rech.Nr., G-Preis und Zahlungsart auch angegegeben aus welchem Setartikel dieses Lossollmaterial ein Bestandteil war.
Beginnt die Hauptwarengruppe mit “Pfand” (Groß-/Kleinschreibung nicht relevant), so werden diese Artikel beim Import nicht berücksichtigt.
Mögliche Fehlerfälle sind:
- Unbekannter Artikel
- erforderliche Spalte nicht gefunden
- zu geringer Lagerstand für bestimmten Artikel
- Wert einer Spalte konnte nicht in erwartetes Datum oder erwartete Zahl umgewandelt werden
- es konnte keine Montageart, Fertigungsgruppe, Kostenstelle mit definiertem Sachkonto oder ein Lager mit Loslager Sortierung gefunden werden
- Defaultartikel für leere Artikelnummer nicht definiert
- Setartikel enthält keine Positionen

Kassen Importer
Schnittstellen zu MES Systemen
Manche Anwender sind der Meinung, dass MES Systeme an Kieselstein ERP angebunden werden sollten. Manchmal gibt es auch die Situation dass verschiedene Maschinenhersteller die erforderlichen Kommunikationsdaten nicht bzw. nur gegen Einsatz von sehr viel Geld, herausgeben.
Auch wenn wir der Meinung sind, dass eine direkte Integration der vollständigen Fertigungssteuerung in Kieselstein ERP deutliche Vorteile bringt, die Komplexität und Mühsamkeit der Abstimmung bestätigt dies, so unterstützen wir unsere Kieselstein ERP Anwender selbstverständlich auch in diesen Dingen.
Hydra
Mit der Hydra-Schnittstelle wurde eine bidirektionale Verbindung zwischen den Losen aus Kieselstein ERP und den (Fertigungs-) Aufträgen von Hydra geschaffen. Bitte beachten Sie bei der Definition Ihrer Kieselstein ERP Daten die zahlreichen Beschränkungen die durch das Hydra System grundsätzlich gegeben sind.
Nachfolgend eine kompakte Beschreibung zur Verbindung mit dem Hydra System. Für weitere Details wenden Sie sich bitte vertrauensvoll an Ihren Kieselstein ERP Betreuer.
Das Hydra-Microservice läuft als eigenständiger HTTP-Server (Host + Port in Mandantenparameter HYDRA_SERVER definieren), idealerweise direkt auf dem Rechner auf dem auch Ihr Hydraserver läuft. Wechselt ein Los in den Status “In Produktion” und entspricht es weiteren Hydra-Kriterien, wird die Ausgabe per HTTP-POST dem Microservice bekanntgegeben. Folgende Kriterien müssen dabei erfüllt werden:
- Zusatzfunktionsberechtigung “Hydra”
- Mandantenparameter HYDRA_SERVER beinhaltet mit Host:Port das darüber erreichbare Microservice
- Los-Fertigungsgruppe ist jene wie in Mandantenparameter HYDRA_FERTIGUNGSGRUPPE definiert
Das Hydra-Microservice holt sich daraufhin selbständig über die Rest-API alle Daten des Loss und wandelt die erhaltenen Daten in die vorgegebene Hydra-Datenstruktur als Hydra-Auftragsdaten um. Diese beinhalten derzeit drei verschiedene Daten-Segmente:
- Auftragskopf: Losnummer, Zusatzstatus, Stücklistenartikelinformation, Kunde, Losgröße, Beginn- und Ende-Termin
- Langtexte des Auftragskopfes: Projekt und Kommentar
- Arbeitsgänge, die wiederum in drei Segmente (AG, AG-Komponenten, AG-Langtexte) unterteilt sind. U.a. mit AG-Nr., AG-Namen, Rüstzeit, Stückzeit, Maschine, Material… Es werden dabei nur jene Arbeitsgänge berücksichtigt, die als AG-Art jene definiert haben, wie sie in der Konfiguration des Microservices definiert ist.
Pro Los erzeugt das Microservice somit eine temporäre Datei mit den zugehörigen Hydra-Auftragsdaten. Hydra nimmt die Daten über eine definierte Zieldatei entgegen, die von beiden Systemen (Hydra, Microservice) erreichbar ist. Ist diese Zieldatei nicht vorhanden (= Hydra hat die letzte eingelesen bzw. übernommen), schreibt das Microservice eine neue und fasst damit alle bis dahin erzeugten temporären Auftragsdaten darin zusammen und stellt sie so Hydra wieder zur Verfügung.
Schnittstellen zu Exchange / Outlook
Steht aktuell für Kieselstein ERP nicht zur Verfügung. Solltest du einen entsprechenden Bedarf haben, freuen wir uns über deine Anfrage.
-
Mit dem Zusatzservice HV-EST, HELIUM V Exchange Synchronisations Tool, können die Daten aus Ihrem Partnerstamm nach Exchange übertragen werden. Im wesentlichen werden hier die Firmen, Ansprechpartner mit deren Adressdaten, sowie Telefonnummern und EMailadressen in einer strukturierten Form in die zentralen Adressdaten des Exchange (LDap-Verzeichnis) importiert. Der Import ist so aufgebaut, dass portionsweise die Adressen vom HELIUM V Exchange Synchronisations Tool vom Kieselstein ERP Server abgeholt und in das Exchange übertragen werden. Da Exchange nur auf Microsoft-Betriebssystemen zur Verfügung steht, ist die HV-EST auch ein Windows-Programm.
Die Gliederung / Erkennung ob eine Partneradresse eine Firma oder ein Ansprechpartner einer Firma ist, erfolgt daran, wenn eine Adresse ein Ansprechpartner einer Firma ist, so wird dies in dieser Struktur im Exchange abgelegt. Ist eine Adresse nicht Mitglied / Ansprechpartner einer anderen Adresse wird dies als reine Firmenadresse betrachtet. Zusätzlich werden die übertragenen Adressen gegenseitig gekennzeichnet, sodass Änderungen in Ihren Kieselstein ERP Adressdaten beim nächsten Lauf im Exchange aktualisiert werden. Da dieser Dienst, wie beschrieben, immer nur Teile überträgt, kann es, je nach Umfang, einige Zeit dauern, bis die Daten synchron sind.
Bitte beachten Sie, dass aufgrund dessen, dass nur Adressdaten übertragen werden, keine wie immer geartete Unterscheidung zwischen den Mandanten gemacht werden kann.
-
Mit dem Zusatzprogramm HV-OST, HELIUM V Outlook Synchronisations Tool, können die Daten aus Ihrem Partnerstamm über Office365 nach Outlook übertragen werden. Die Einrichtung dieser Funktion setzt administrative Rechte für Ihren Office365 Zugang voraus. Das entsprechende Programm (HV-OST.exe) fordern Sie bitte mit der genauen Einrichtungsbeschreibung bei Ihrem Kieselstein ERP Betreuer an. Die Verbindung zwischen Kieselstein ERP und Ihrem Office365 Adressbuch stellt die im Personal des jeweiligen Benutzers eingerichtete EMail-Adresse dar. Es werden die Kontaktdaten anhand folgender Logik ermittelt: Projekte in denen der Benutzer als Mitarbeiter oder als “wird durchgeführt von” im Detail eingetragen ist. Angebote in denen der Benutzer der Vertreter ist Aufträge in denen der Benutzer als Vertreter oder Auftragsteilnehmer eingetragen ist Rechnungen in denen der Benutzer als Vertreter eingetragen ist. Kunden in denen der Benutzer als Provisionsempfänger oder als Sachbearbeiter eingetragen ist.
Bitte beachten Sie auch den Personal-Parameter Alle Kontakte synchronisieren. Mit diesem werden, entgegen obiger Logik, alle Partner in Ihre Outlook-Kontakte übertragen.
Webshop
Nachfolgend eine Sammlung von nützlichen / wichtigen Informationen rund um das Thema Webshop. Zum Thema CleverCure siehe bitte
Lieferschwelle / Lieferung an Endkunden im EU-Ausland
Mit der Lieferung an Endkunden (B2C Geschäft) im EU Ausland sind je nach Empfänger-Land verschiedene Lieferschwellen verbunden, bei denen Sie gezwungen werden, die Umsatzsteuer mit dem Steuersatz des Empfängerlandes anzugeben und auch die einbehaltene Umsatzsteuer beim jeweiligen Empfängerfinanzamt abzuführen.
Dafür, also die Lieferung an Endkunden steht das OSS Verfahren zur Verfügung. Siehe dazu bitte
Dies betrifft nur die Umsätze mit Endkunden. Für die Umsätze zwischen Unternehmen (B2B) gilt die Regelung der innergemeinschaftlichen Lieferungen.
Das bedeutet wiederum, dass es für Neukunden im Webshop wichtig ist, dass dieser seine UID-Nummer angibt.
Eine Aufstellung der Lieferschwellen finden Sie z.B. im Portal der österreichischen Wirtschaftskammer.
Wo kann ich definieren, ob Kundensonderkonditionen an den Webshop übermittelt werden?
In System - Parameter finden Sie den Parameter “KUNDESONDERKONDITIONEN_WEBSHOP_VERWENDEN”. Wenn Sie diesen Parameter auf 0 stellen, so werden die Kundensonderkonditionen nicht an den Webshop übermittelt. Bei 1 werden die Sonderkonditionen übermittelt.
18.1 - CleverCure
Infos rund um CleverCure
Eine Sammlung unserer Informationen rund um die EDI Schnittstelle CleverCure
Rest-Einsprungspunkt
Der Einsprungspunkt über das https: Protokoll (achte darauf, dass für den https-Port NUR dein externer Partner freigeschaltet ist) ist:
https://deine_externe_EP-Adresse/kieselstein-restapi/services/rest/api/beta/cc?companycode=nnnnn&token=tttttttttttt
- Companycode siehe
- token siehe
Error 417
Bedeutet dass (noch) kein Versandweg eingetragen ist. Diesen nachtragen. Dabei darauf achten, dass in der lp_versandwegpartnercc und in der lp_versandwegpartner die gleichen Anzahl an Definitionen gegeben ist. Die jeweilige ID ist der gemeinsame Schüssel.
select * from lp_versandwegpartnercc select lp_versandwegpartnercc.c_kundennummer, part_partner.c_uid, i_soko_adresstyp, * from lp_versandwegpartner inner join part_partner on lp_versandwegpartner.partner_i_id=part_partner.i_id left outer join lp_versandwegpartnercc on lp_versandwegpartnercc.i_id=lp_versandwegpartner.i_id order by part_partner.c_kbez
- Üblicherweise per Hand die neue ID in der lp_versandwegpartner nachtragen
- Irgendwie spielen da die UID Nummern auch noch mit, zumindest für die Zuordnungen
- Knd Lieferantennummer = Werkskennung
- Verkettung im lp_versandwegpartner
- Es muss die Lieferadresse zugeordnet werden
Auftrag xxx existiert bereits
Diese Fehlermeldung (Error 417) kann leider auch bedeuten, dass ein Auftrag mit dieser Bestellnummer bereits in deinem Kieselstein ERP angelegt ist.
- Im Tomcat-Log findest du dazu “nur”
IP-Adresse - - [14/Sep/2023:16:15:05 +0200] “POST /kieselstein-rest/services/rest/api/beta/cc?companycode=12345&token=20ETMCCMVH13 HTTP/1.1” 417 -
Wichtig ist hier der Zeitpunkt.
- Im server.log findest du dazu:
2023-09-14 16:15:05,665 WARN [com.lp.server.auftrag.ejbfac.WebshopOrderServiceEjb] (default task-3) Der Auftrag ‘JJ/nnnnnnn’ existiert mit der Bestellnummer ‘xxxxxxxx’. Kein weiterer Auftrag angelegt!
Das bedeutet nichts anderes, dass versucht wurde einen Auftrag erneut einzuspielen, obwohl dieser bereits übermittelt wurde.
Info: Die Schnittstelle ist so vereinbart, dass einmal übertragene Aufträge vom CleverCure-Sender nicht mehr geändert werden dürfen.
Warum? Wie willst du denn deine Fertigung steuern, wenn dir der Kunde laufend die Auftragsdaten verändert?
zu klären
Werden versteckte Artikel trotzdem in die AB übernommen, oder kommt deswegen ein Fehler, weil nicht ordentlich unterstützt?
Anbindung Clever Cure
Mit der Anbindung an CleverCure (siehe dazu auch CureComp.com) wurde eine praktische Schnittstelle für einen Teil der Supplychain geschaffen.
Die im Wesentlichen abgebildeten Funktionen sind:
- Übertragen einer Bestellung aus dem Kundensystem in Ihr Kieselstein ERP
- Senden der Auftragsbestätigung aus Ihrem Kieselstein ERP an den Kunden
- Senden eines Lieferavisos
Voraussetzungen: (Konfiguration siehe unten)
- Kieselstein ERP Webservices
- Kieselstein ERP RestAPI Server
- HTTPS Zugang bidirektional, abgesichert durch Zertifikate. Eine entsprechende Parametrierung der Firewall ist erforderlich.
- Parameterdaten wie Kundennummern, Lieferantennummern usw.
- Kunden-Sonderkonditionen zur Pflege der Kundenartikelnummern
Ablauf:
Nach erfolgter Parametrierung und Einrichtung des Systems sieht der Ablauf wie folgt aus:
-
Vom Kundensystem wird eine Bestellung mit Auftrags-, Rechnungs- und Lieferadresse und den inhaltlichen Positionen gesandt. Von der Kieselstein ERP CleverCure Schnittstelle werden diese Daten, soweit sie technisch (Achtung: Nicht inhaltlich) in Ordnung sind gültig entgegen genommen.
-
Diese Daten werden konvertiert und als Auftragsbestätigung in Ihrem Kieselstein ERP angelegt. Zugleich wird ein EMail an den CleverCure EMail-Empfänger über den Auftragseingang gesandt. Details zur Datenzuordnung siehe unten.
-
Von Ihnen wird die Auftragsbestätigung geprüft und gegebenenfalls korrigiert. Bitte achten Sie darauf, dass –> Positionensplitt ….
-
Drucken Sie nun die Auftragsbestätigung, zumindest in die Vorschau, aus. Entspricht die AB Ihren Vorstellungen, so
-
senden Sie diese per CleverCure an Ihren Kunden, durch Klick auf den Knopf Auftrag übermitteln
 in den Auftrags-Kopfdaten.
Wurden bereits Daten an Ihren Kunden gesandt, so:
in den Auftrags-Kopfdaten.
Wurden bereits Daten an Ihren Kunden gesandt, so:- wird dies durch einen grünen Hintergrund im Knopf angezeigt
 und der Zeitpunkt des Versands wird in der Fußzeile angezeigt.
und der Zeitpunkt des Versands wird in der Fußzeile angezeigt. - sollte die Auftragsbestätigung erneut an den Kunden gesandt werden, so wird nach dem Klick auf den Auftrag übermitteln Knopf die Meldung
 angezeigt, welche mit Ja bestätigt werden muss. Bitte beachten Sie, dass damit eine entsprechende Änderung der Auftragsdaten auch bei Ihrem Kunden vorgenommen wird.
Info: Neben den üblichen Daten aus Kieselstein ERP wird auch das Ursprungsland, welches im jeweiligen Artikel hinterlegt ist, in der Auftragsbestätigung mit zurückgesandt.
angezeigt, welche mit Ja bestätigt werden muss. Bitte beachten Sie, dass damit eine entsprechende Änderung der Auftragsdaten auch bei Ihrem Kunden vorgenommen wird.
Info: Neben den üblichen Daten aus Kieselstein ERP wird auch das Ursprungsland, welches im jeweiligen Artikel hinterlegt ist, in der Auftragsbestätigung mit zurückgesandt.
- wird dies durch einen grünen Hintergrund im Knopf angezeigt
-
Nach erfolgter Beschaffung / Produktion erfolgt die Lieferung der Ware, in der in Kieselstein ERP üblichen Art und Weise, Auftragsbezogener Lieferschein, Sicht Auftrag.
-
Ist die Lieferung fertig zusammengestellt und der Lieferschein ausgedruckt, so senden Sie Ihrem Kunden eine Lieferaviso. Klicken Sie dazu im Lieferschein, Kopfdaten auf Lieferaviso übermitteln
. Auch hier gilt, wenn ein Lieferaviso bereits versandt wurde, wird dies durch den grünen Hintergrund im Lieferaviso Knopf angezeigt. Auch das Lieferaviso kann erneut versandt werden.
Zuordnung der Daten zwischen CleverCure und Kieselstein ERP
| Clever Cure | Kieselstein ERP | Bemerkung |
|---|---|---|
| <BUYER_PARTY> <PARTY_ID> | Auftragsadresse | Diese muss im Kunden als Lieferantennummer hinterlegt sein. Bitte überprüfen Sie auch die im Kunden hinterlegten UID.Dies ist zugleich auch die Basis für die Zuordnung der Kundenartikelnummern zu Ihren eigenen Artikelnummern. |
| <SHIPMENT_PARTIES> <DELIVERY_PARTY> | Lieferadresse | Es muss dazu die Adresse im Wortlaut übereinstimmen. D.h. die ersten beiden Zeilen der Adresse und die Straße.Gegebenenfalls nicht konvertierbare Zeichen werden ignoriert |
| <INVOICE_PARTY> | Rechnungsadresse | Dazu muss im Kunden die UID Nummer hinterlegt sein. Wenn diese UID nicht übereinstimmt, so wird die Auftragsadresse verwendet. |
| <CC_DRAWING_NR> <CC_INDEX_NR> | Kundenartikelnummer + Revisions- nummer | In der Rechungsadresse werden in den Soko die Kundenartikelnummern gesucht. Parallel zur Zuordnung wird auch die Revision zwischen CC und dem Feld Revision im Kieselstein ERP Artikelstamm geprüft. |
| <LINE_ITEM_ID> | Positions-ID | Essentielle Nummer für die Zuordnung der Position zwischen den CC-Partnern. Für die Durchgängigkeit des Ablauf von Bestellun bis zum Lieferaviso. Diese muss genau übereinstimmen! Sie finden die Information in der Texteingabe zur Position in Kieselstein ERP. |
| <CC_ORDER_UNIT> | Mengeneinheit | Diese muss mit der in Kieselstein ERP eingetragenen Kennung übereinstimmen. Siehe dazu: System, Sprache, Einheit. Wenn diese Kennung hier nicht vorhanden ist, so wird die Mengeneinheit Stk. verwendet. Die Information welche Mengeneinheit bestellt wurde finden Sie in der darüberliegenden Information. Ändern Sie diese entsprechend ab um im Lieferavisio eine Übereinsstimmung zu erzielen. |
| Lieferart | Auch die Lieferart muss mit der in Kieselstein ERP eingetragenen Kennung übereinstimmen. Siehe dazu Lieferadresse, Konditionen, Lieferart bzw. System, Mandant, Lieferart, Kennung.Siehe dazu auch Incoterms im Modul System unterer Modulreiter Mandant oberer Reiter Lieferart. | |
| <DELIVERY_START_DATE> <DELIVERY_END_DATE><ORDER_DATE> | Auftragstermine | In den Kopfdaten des Auftrags in Kieselstein ERP wird in den Liefertermin der früheste Positionstermin und in den Finaltermin der späteste Positionstermin eingefügt. Das Bestelldatum entspricht der Information, die im Order-Date. |
| <DELIVERY_START_DATE> | Positionstermin | Dieser Termin ist der “Wunschtermin” aus der Bestellung des Kunden und kann der Liefersituation entsprechend für das Lieferavisio angepassst werden. |
| <PRICE_AMOUNT> | Nettopreis | Der erhaltene Preis, welcher mit dem im Artikelstamm / Kundensonderkonditionen für diese Auftragsadresse hinterlegten Preis übereinstimmen muss. |
Infos / Fehlermeldungen beim Auftragsimport:
Werden Unstimmigkeiten zwischen den in Ihrem System hinterlegten Daten und den erhaltenen Daten festgestellt, so werden entsprechende Info: Texteingaben in die Auftragsbestätigung vor der jeweiligen Ident/Handeingabe eingefügt. Prüfen Sie diese Fehler, beseitigen Sie diese im Auftrag und vor allem in der Definition Ihrer Daten. So erhalten Sie sehr rasch ein zu / mit Ihrem Kunden abgestimmtes System.
Ein Beispiel hierfür ist, dass eine Artikelnummer in Kieselstein ERP gefunden wird, aber keine der CC-Bestellung entsprechende Revisionsnummer vorhanden ist. Diese Information wird als Texteingabe in den Auftrag geschrieben. Eine Vorgehensweise dazu wäre, dass Sie nun einen neuen Artikel anlegen mit der aktuellen Revisionsnummer und diesen in der Position im Auftrag abändern.
Wenn eine Position (Ident) über die Sonderkonditionen nicht gefunden wird, so wird nach der Artikelnummer gesucht, wenn auch hier keine Übereinstimmung besteht, so wird eine neue Position mit der Art Handeingabe angelegt, die alle Informationen zur Bestellposition enthält (Bezeichnung, Menge, Mengeneinheit, LINE_ITEM_ID, Mwst-Sätze, gesuchte Artikelnummer).
Wenn keine Preise/Verkaufspreisbasis für einen Artikel hinterlegt sind, wird der Betrag “0.00” für die Auftragsposition verwendet. Zusätzlich gibt es eine Textposition mit der Mitteilung, dass der Preis nicht ermittelt werden konnte und deshalb auf 0 gestellt wurde.
ACHTUNG: Die LINE_ITEM_ID muss in jeder Position des Auftrags als Texteingabe in folgender Form {“lineitemid” : “1”} enthalten sein! Verwenden Sie für die Umwandelung einer Handeingabe in einen Artikel den Menüpunkt Bearbeiten, Handartikel in Artikel umwandeln, so bleibt diese Information erhalten.
Welche Daten werden von der Schnittstelle in der Dokumentenablage des jeweiligen Auftrages abgelegt?
-
Import Clevercure XML Import_Clevercure Dies sind die Original Daten die Kieselstein ERP von CleverCure erhalten hat
-
Export Clevercure XML Auftragbestätigung_osa_Clevercure Diese Daten wurden als Auftragsbestätigung an CleverCure gesandt
Daten die zum Export des Lieferavisos abgelegt werden sind:
- Export Clevercure XML Lieferaviso_Clevercure Diese Daten wurden als Lieferaviso an CleverCure gesandt
Ergänzende Infos in den Formularen zu CleverCure
-
Auftragsbestätigung
Parameter java.lang.String P_VERSANDWEG_BESTAETIGUNG_TERMIN, der Zeitpunkt (Datum&Uhrzeit) an dem die Bestätigung gesendet wurde als Datum formatiert. Null wenn noch nicht bestätigt Parameter java.lang.Boolean P_VERSANDWEG, “true” wenn für diesen Auftrag ein Versandweg (Clevercure) festgelegt ist, “false” wenn nicht
-
Lieferschein
Parameter java.lang.String P_VERSANDWEG_AVISO_TERMIN, der Zeitpunkt (Datum&Uhrzeit) an dem das Aviso gesendet wurde als Datum formatiert. Null wenn noch nicht avisiert
Parameter java.lang.Boolean P_VERSANDWEG, “true” wenn für diesen Auftrag ein Versandweg (Clevercure) festgelegt ist, “false” wenn nicht
Feld java.lang.String F_AUFTRAG_BESTAETIGUNG_TERMIN der Zeitpunkt (Datum&Uhrzeit) an dem die Bestätigung gesendet wurde als Datum formatiert. Null wenn noch nicht bestätigt
Feld java.lang.BOOLEAN F_AUFTRAG_VERSANDWEG “true” wenn für diesen Auftrag ein Versandweg (Clevercure) festgelegt worden ist, ansonsten “false”
Kieselstein ERP Webservices - in der Standard-Installation von Kieselstein ERP enthalten.
Kieselstein ERP RestAPI Server
siehe Grundeinstellung und Definition RestAPI
Zusätzlich gibt es einen Kieselstein ERP Benutzer, der die Interaktion von Kieselstein ERP und dem RestAPI-Webserver durchführt. Dieser muss auf beiden Seiten definiert werden.
Im Tomcat passen Sie die Definition restapi.xml nach folgendem Vorbild an:

Weitere Definitionen in Kieselstein ERP
Legen Sie dazu im Modul Benutzer einen neuen Benutzer an und geben Sie ihm eine Benutzerrolle und hinterlegen den Mandanten. Die Benutzerrolle muss die Rechte AUFT_AUFTRAG_CUD, AUFT_AUFTRAG_R, PART_LIEFERANT_R, PART_PARTNER_R, WW_ARTIKEL_R besitzen. Hinterlegen Sie beim Benutzer je nach Anforderung eine neue Person (Modul Personal Neu) oder eine bestehende.
Geben Sie im Modul Personal oberer Reiter Daten jene E-Mail Adresse ein, an die eine Nachricht gesendet wird, wenn in Kieselstein ERP ein neuer Auftrag angelegt wurde. Um die Nachricht an mehrere E-Mail Adressen zu verschicken, geben Sie die Adressen mit einem Semikolon (;) getrennt ein.
Im oberen Reiter Detail muss im Feld Ausweis die Identifikationsnummer für das Clevercure-Portal eingegeben werden.
Im Modul Artikel unterer Reiter Grunddaten legen Sie im oberen Reiter Webshop einen neuen Webshop an. Der Name muss ebenso der Definition im restapi.xml entsprechen.
Im Modul System unterer Reiter Sprache, oberer Reiter Einheiten legen Sie die Einheiten PCE (Stück) und KGM (kg) an. Bitte bedenken Sie, falls weitere Übersetzungen der Einheiten aus der Auftragsübermittlung nötig sind, diese hier anzulegen.
HTTPS Zugang bidirektional, abgesichert durch Zertifikate. Eine entsprechende Parametrierung der Firewall ist erforderlich.
Parameterdaten wie Kundennummern, Lieferantennummern usw.
Für die Definition für welche Kunden Sie die Clevercure-Schnittstelle verwenden, wenden Sie sich dazu derzeit an Ihren Kieselstein ERP Betreuer.
Für die Definition im Clevercure-Portal, für welchen Kunden Sie ein Auftragsbestätigung/Lieferaviso schicken, geben Sie im Modul Kunde, oberer Reiter Konditionen Ihre eigene Kundennummer im Feld Lieferantennummer ein.
Kunden-Sonderkonditionen zur Pflege der Kundenartikelnummern
Tragen Sie die Artikelnummern für die Kunden jeweils im Modul Kunde - oberer Reiter Sonderkondition ein. Klicken Sie dazu auf neu, wählen Ihren Artikel aus und geben die kundenspezifische Ident ein. Achtung: Beachten Sie das Feld Gültig ab und tragen hier das gewünschte Datum ein. Zusätzlich definieren Sie im Modul Artikel bei diesem Artikel die Revisions-Nummer.
VMI Artikel
Es kommt immer wieder die Frage wie ist im Rahmen von CleverCure mit den VMI Artikel (Vendor Managed Inventory) umzugehen. Die Antwort dazu ist eigentlich, es ist dies durch entsprechende Verträge zu regeln. Die Bedeutung von VMI ist im Sinne von CleverCure, dass Artikel quasi sofort, spätestens am nächsten Tag geliefert werden müssen. Da bedingt, dass Sie als Lieferant an Ihren CleverCure Kunden wissen müssen, welche Artikel das sind. Sie müssen auch wissen, welche Menge Sie zu bevorraten haben. Sind diese Artikel, durch Ihren Kunden, definiert so müssen im Kieselstein ERP entsprechende Lagermindeststände dafür hinterlegt werden, damit Sie immer lieferfähig sind. Kommt nun ein neuer/zusätzlicher Artikel, aus dem Sinne des VMI über die Schnittstelle, so bedeutet dies nur, dass dieser Artikel nicht Vertragsbestandteil der VMI Vereinbarung ist. D.h. es hätte Ihnen Ihr Kunde rechtzeitig mitteilen müssen, dass er einen weiteren Artikel in die VMI Logik mit aufnimmt. In diesem Falle muss die weitere Vorgehensweise direkt (telefonisch) mit Ihrem Kunden geklärt werden. Dass Sie natürlich versuchen den Kunden entsprechend rasch zu beliefern, ist für alle Beteiligten sicherlich nachvollziehbar.
18.2 - Woo Commerce Import
Einlesen von Shopdaten in den Auftrag
Im Auftragsmodul steht auch der Shop-Import im WooCommerce Format zur Verfügung. Laut Informationen von Kieselstein ERP eG Mitgliedern kann dieses Datenformat auch von Shopware mit einer kleinen Anpassungsprogrammierung zur Verfügung gestellt werden.
WooCommerce Import
Dieser Import steht im Modul Auftrag, im Menüpunkt Auftrag, Import, WooCommerce CSV zur Verfügung. Die Grundidee ist, dass vom Shop täglich Daten abgeholt werden, z.B. über FTP Import und dann täglich diese Daten eingelesen werden. Da es dabei immer wieder zu erforderlichen Anpassungsarbeiten kommt, sehen wir den manuellen Import als sinnvoller an.
Man findet die Schnittstelle im Modul Auftrag.

Zuordnung der WooCommerce Spaltenname:
Wichtig: Die Spaltenbezeichnungen müssen in Englisch übergeben werden. Wir gehen davon aus, dass alle Beträge als Nettobeträge übergeben werden.
Zusätzlich haben wir die Logik implementiert, dass der Brutto-Gesamtbetrag = Order Total Amount aus dem Shop exakt dem anhand der Kieselstein ERP Preise errechneten Wert entsprechen muss / sollte. D.h. wenn die Verkaufspreisfindung gleiche Preise ergibt wie die Preise aus dem Shop, so sollten sich die gleichen Summen ergeben.
Hier kommt noch die Herausforderung dazu, dass der Shop ein Brutto rechnendes System ist und Kieselstein ERP netto rechnet. Das bedeutet wiederum, dass es zu geringen Cent-Abweichungen kommen kann.
Diese Differenz wird, wenn sie unter 1,00 € ist, ausgeglichen. Ev. ist dafür auch der Rundungsartikel zu definieren.
Definieren Sie dafür den Parameter RUNDUNGSAUSGLEICH_ARTIKEL mit z.B. RUNDUNG. Der Artikel RUNDUNG selbst muss, nicht lagerbewirtschaftet sein. Der Mehrwertsteuersatz muss mit steuerfrei definiert werden.
“Order Number”,“Order Status”,“Order Date”,“Customer Note”,Title,“First Name (Billing)”,“Last Name (Billing)”,“Company (Billing)”,“Address 1&2 (Billing)”,“City (Billing)”,“State Code (Billing)”,“Postcode (Billing)”,“Country Code (Billing)”,“Email (Billing)”,“Phone (Billing)”,“First Name (Shipping)”,“Last Name (Shipping)”,“Address 1&2 (Shipping)”,“City (Shipping)”,“State Code (Shipping)”,“Postcode (Shipping)”,“Country Code (Shipping)”,“Payment Method Title”,“Cart Discount Amount”,“Order Subtotal Amount”,“Shipping Method Title”,“Order Shipping Amount”,“Order Refund Amount”,“Order Total Amount”,“Order Total Tax Amount”,SKU,“Item #”,“Item Name”,Quantity,“Item Cost”
| Spalte | Bedeutung | Aktion / Beschreibung |
|---|---|---|
| Title | Anrede | Die Anrede (Title) aus dem Shop wird wie folgt interpretiert: 1 … Herr 2 … Frau alle anderen werden derzeit auf <leer>, also keine gesetzt. |
| First Name | Vorname | Es werden die Spalte First Name in den Vornamen und Last Name in den Familiennamen übernommen |
| Last Name | Nachname | |
| Kunden Erkennung | Um zu erkennen ob ein Kunde schon angelegt ist, wird die RE-EMail-Adresse herangezogen. D.h. gibt es für die erhaltene EMail-Adresse Email (Billing) bereits einen angelegten Kunden, so wird dieser verwendet und kein neuer Kunde angelegt. Wird die EMail-Adresse nicht unter RE-EMail-Adresse gefunden, so wird der Kunde neu angelegt. Bitte achten Sie darauf, dass aktuell auch die Groß-/Kleinschreibung für die Zuordnung herangezogen wird. |
|
| Shipping Method Title | Lieferart | Dieser Eintrag wird unter den Lieferarten, genauer einer Bezeichnung aus den Lieferarten gesucht. Wird kein Eintrag gefunden, wird der Import abgebrochen. Hinter der Lieferart muss es auch einen Versandkosten- (Transportkosten)-Artikel geben. Die Versandkosten werden (netto) vom Shop in der Spalte Order Shipping Amount übergeben. Beim Import wird der Verkaufspreis der AB-Position des Versandkostenartikels auf diesen Betrag gesetzt, wodurch die Adresse wie eine Firma behandelt wird. |
| SKU | Artikelnummer | muss mit der Artikelnummer deines Kieselstein-ERP Artikelstamms übereinstimmen |
| Quantity | Menge | wird als Positionsmenge in den Auftrag übernommen |
| Item Cost | netto Verkaufspreis dieses Artikels | Bei der Anlage der Auftragsposition wird der Verkaufspreis anhand der Verkaufspreisfindung ermittelt. Weichen der ermittelte Verkaufspreis zu dem vom Shop erhaltenen Item Cost um mehr als 0,01 € ab, wird eine Fehlerzeile hinzugefügt. |
Rechnungsadresse / Lieferadresse
- Die Rechnungsadresse wird anhand der erhaltenen EMailadresse ermittelt. D.h. ist im Kieselstein ERP Kundenstamm die RE-EMail Adresse bereits vorhanden, so wird diese Adresse als Kunde verwendet. Es erfolgt keine weitere Prüfung mehr.
- Sind in den erhaltenen Shop-Daten die Daten für die Rechnungsadresse und die Lieferadresse gleich, so wird als Lieferadresse, des Auftrags, die Rechnungsadresse verwendet, egal ob die erhaltenen Adressdaten davon abweichend sind.
- Sind in den erhaltenen Shop-Daten die Daten für die Rechnungsadresse und die Lieferadresse ungleich, so wird die Lieferadresse neu angelegt und die Adressart als Lieferadresse gekennzeichnet.
ACHTUNG
Die RE-EMail Adresse darf im gesamten Kundenstamm nur EINMAL vorkommen. Anderenfalls wird die Adresse erneut angelegt. Auch wenn diese EMail Adresse bei verschiedenen Ansprechpartnern definiert ist, kann es zu Fehlinterpretationen kommen.Nutze gegebenenfalls auch die Groß-/Klein-Schreibung bei den EMail Adressen (nicht getestet).
Info:
Die erweiterte Suche bei der Kundenauswahl prüft leider die RE-EMail-Adresse NICHT!
Fehlermeldungen
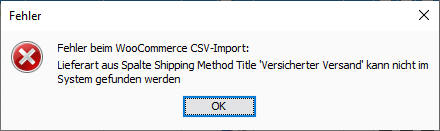
Bitte die angeführte Lieferart definieren. Siehe oben Lieferart bzw. nachfolgend ein Muster wie die Lieferat angelegt werden könnte.
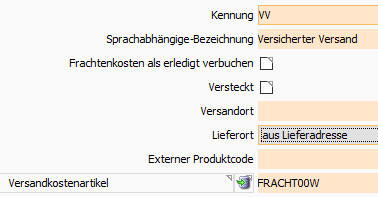
Bitte beachte die Zuordnung des Frachtkostenartikels
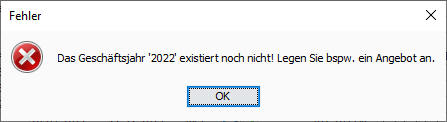
Passiert bei der Vergabe der Debitorennummer für neue Kunden.
ACHTUNG: Bitte die automatische Vergabe der Debitorennummer abschalten.
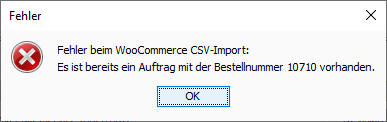
Dies passiert gerne, wenn manuell der Auftrag aus dem Shop angelegt wird und danach der Import gestartet wird. Um diese Situation zu entschärfen, wird vom Import automatisch SHOP- vor die eigentliche Bestellnummer aus dem Shop gestellt.
Parameter
Mit dem Parameter WOOCOMMERCE_PARTNER_ZUSAMMENZIEHEN kann eingerichtet werden, dass Vorname und Nachname beim Import, wenn keine Company gegeben ist, in den PartnerName1 zusammengezogen wird.
Musterdaten
Musterdaten mit genauer Feldzuordnung siehe als LibreOffice Vorlage mit Beschreibung bzw. als CSV
Zusatzinfo
- Die Partnerart ist fix auf Adresse, so wie bei anderen Kunden auch
- Die Kommunikationssprache ist in der Regel die Sprache in der sich der Kieselstein ERP Benutzer angemeldet hat
- Der Mehrwertsteuersatz kommt aus dem Land, also Inland mit Allgemeine Waren, alle anderen Länder Steuerfrei. Für genauere Definition siehe bitte System, Mandant, Vorbelegungen.
18.3 - Profirst Anbindung
Profirst Anbindung
PROfirst Anbindung
Mit der Profirst Anbindung wird eine Verbindung zwischen dem Konstruktions und Schachtelprogramm ProFirst und Kieselstein ERP geschaffen. ProFirst wird vor allem in der Blechbearbeitung, wie z.B. Laserschneiden bzw. Plasmaschneiden eingesetzt. Der grundsätzliche Ablauf ist in der Regel folgender (siehe auch):
-
Vom Kunden wird ein neues Teil angefragt. Dieses wird in PROfirst konstruiert und somit der Fertigungs-Artikel in Profirst mit all seinen Eigenschaften angelegt. Ist der Fertigungs-Artikel fertig konstruiert, müssen die PROfirst-Daten von Kieselstein ERP eingelesen werden. Wählen Sie dafür im Artikelmodul, Pflege, PROfirst Import. Bei diesem Import wird ein direkter Zugriff auf Ihre PROfirst Datenbank gemacht und die Bauteile und deren Bildinformationen ausgelesen.
-
Die Verdrahtung der Felder zwischen ProFirst und Kieselstein ERP ist wie folgt: Es wird dabei auch ein Bild des Artikels aus ProFirst nach Kieselstein ERP mit übernommen. Verdrahtung:
ProFirst Kieselstein ERP Bedeutung Artikelnummer Stücklisten-Artikelnummer Dies ist die Artikelnummer der Stückliste unter der der Fertigungs-Artikel angelegt wird.Auf die Länge achten, max 25Stellen, Alphanummerisch Material Stkl-Pos-Artikelnummer Das Rohmaterial wird in die Stückliste als Materialposition übernommen. Die Abmessungen werden in mm für das umformende Rechteck übergeben. Auf diesen Abmessungen beruhen die Bedarfsberechnungen für das Gesamtmaterial.Die Material-Stärke wird in der Artikelnummer des Materials abgebildet.Das Rohmaterial ist entweder bereits angelegt oder wird beim Import von Kieselstein ERP erzeugt. Der Aufbau der Artikelnummer wird wie folgt errechnet: Maschine Stkl-Arbeitsplan-Position Erzeugt eine Arbeitsplanposition der Tätigkeit Autogen oder Plasma oder Laser -schneiden unter Angabe der Maschine auf der der Artikel geschnitten werden soll.Rüst- und Stückzeit kommen aus den Feldern …..und werden im Format hh:mm:ss übergeben. Es sind auch Zeiten > 24Std möglichDie dafür erforderlichen Tätigkeiten müssen definiert sein.Die dafür erforderlichen Maschinen müssen ebenfalls definiert sein. Die Arbeitsgangposition wird mit der Materialposition verbunden. Bilddatei Artikelkommentar Fertigungsbild Es ist im Verzeichnis passend zur Artikelnummer auch eine Bilddatei im xxx (jpg/png) Format abgelegt. Diese wird bei der Stückliste als Artikelkommentar, mit der Markierung bei Fertigung mitdrucken hinterlegt. Bauteilname Artikelnummer Kunde Stückliste Kunde Stärke Teil der Artikelnummer des Materials Werkstoff Teil der Artikelnummer des Materials Hinterlegen des Werkstoffs beim Material Werkstofftyp Teil der Artikelnummer des Materials Bezeichnung des Materials Form wird nicht verwendet Menge wird nicht verwendet Ändern wird nicht verwendet Fläche (Brutto) Fläche des Materials Wird in mm² als Material in die Stücklistenposition eingetragen Preis NettoField 1 VK-Preisbasis Verkaufspreisbasis Das Datum gültig ab wird mit dem Importdatum vorbesetzt Knd.Art.Nr.Field 2 Kurzbezeichnung Wird üblicherweise als Knd.Art.Nr verwendet und auch bezeichnet ZeichnungsNrField 3 Referenznummer Wird üblicherweise als Zeichnungsnummer verwendet und auch bezeichnet AnarbeitungField 4 Fremd-arbeitsgang-artikel (siehe unten) KommissionField 5 Zusatzbezeichnung2 Feld 6 Bauform Wird üblicherweise als Beschreibung verwendet und auch bezeichnet Bearbeitungszeit Stückzeit in hh:mm:ss Maschine Maschine Name (= Inventarnummer) der Maschine auf die die Tätigkeit gebucht werden sollte Schneidart Tätigkeit Artikelnummer der Tätigkeit des Arbeitsgangs, beginnt mit AZ_ gefolgt von der Schneidart. Muss angelegt sein.Es ist dies die Tätigkeit hinter der dann obige Stückzeit und Maschine hinterlegt werden.Das Material des Arbeitsgangs zeigt auf die Materialposition Gewicht (kg) Artikel-Gewicht Gewicht im Artikel im Reiter Technik Datum wird nicht genutzt -
Nun wird gegebenenfalls das entsprechende Angebot in Kieselstein ERP erstellt und an den Kunden übermittelt.
-
Der Kunde bestellt, in Kieselstein ERP wird eine Auftragsbestätigung mit dem Kundenartikel, welches der oben übernommene Fertigungsartikel, der wiederum eine Stückliste ist, erstellt. Natürlich können beliebig viele Positionen im Kundenauftrag erfasst werden.
-
Mit dem internen Bestellvorschlag werden die anzulegenden Lose ermittelt und erzeugt. Nun stehen die zu produzierenden Lose mit deren Arbeitsgängen in denen wiederum die Maschinen enthalten sind und den Materialbedarfen in Kieselstein ERP zur Verfügung.
-
Im Modul Los, unterer Reiter offene AGs, oberer Reiter produzieren sind alle angelegten Lose und deren Arbeitsgänge mit Kunde, Los Nr, Material, Maschine und Fortschritt ersichtlich. Anhand dieser Liste, oder auch anhand des Journals, Maschine + Material, kann der Werker / Arbeitsvorbereiter entscheiden, welche Fertigungsaufträge / Arbeitsgänge er als Arbeitsvorrat für die nächste(n) Tafel(n) an ProFirst übergibt. In dieser Liste finden Sie auch die Anzeige der jetzt produzierbaren Lose. Und wenn Sie mehrere Lose markieren, so wird oben die Summe der Stunden und der Materialmenge, was in der Regel die Fläche der Tafel sein wird, angezeigt. So bekommen Sie ein Gefühl dafür, ob diese Lose aus der Tafel / den Tafeln geschnitten werden können.
-
Für die Übergabe markiert man nun die gewünschten Lose der Maus und Klick auf
 Übergabe an ProFirst.
Damit werden Stkl-Artikelnummer, Losgröße, Kunde, … an ProFirst übergeben.
Zugleich werden die Lose dadurch mit dem Zusatzstatus in PROfirst versehen. Das Los selbst bleibt im Status angelegt.
Übergabe an ProFirst.
Damit werden Stkl-Artikelnummer, Losgröße, Kunde, … an ProFirst übergeben.
Zugleich werden die Lose dadurch mit dem Zusatzstatus in PROfirst versehen. Das Los selbst bleibt im Status angelegt. -
Nun lesen Sie den Arbeitsvorrat in Ihr PROfirst ein. Bitte achten Sie dabei darauf, dass Ihr PROfirst so eingestellt ist, dass vorhandener Arbeitsvorrat immer ergänzt, also erhöht wird.
-
Nun werden in ProFirst die Bauteile auf die Tafeln geschachtelt.
-
Die geschachtelten Bauteile, mit der Information welche Tafel für welches Los (= Fertigungsauftrag) vorgesehen ist, wird wiederum von ProFirst exportiert.
-
Nun wird der Schachtelplan durch Klick auf …. eingelesen. Beim Einlesen werden die im Schachtelplan enthaltenen Artikel/Bauteile so auf die Lose verteilt, dass immer das älteste Los eines Bauteiles verwendet wird. Sollte nicht die gesamte Losgröße in diesem Schachtelplan / der Tafel verwendet worden sein, so wird auch das Los gesplittet, damit wiederum die Gesamtmenge dieses Artikels erhalten bleibt und auch die Information, dass im PROfirst noch offene Lose für dieses Bauteil gegeben sind. Beim Splitting eines Loses wird der Zusatzstatus dass dieses Los bereits in PROfirst ist mit übernommen. Die Information welchem Schachtelplan das Los zugeordnet ist, wird beim Los hinterlegt. Es kann auch nach den Schachtelplannummern gesucht werden. Wir gehen davon aus, dass der Dateiaufbau des Schachtelplans mit csvnnnnn.csv gegeben ist, wobei nnnnn die Schachtelplannummer ist. Wird eine Schachtelplannumer eingegeben die nicht vorhanden ist, erhalten Sie einen entsprechenden Hinweis.
-
Beim Einlesen des Schachtelplans erhalten Sie eine Liste der laut Kieselstein ERP lagernden Tafeln dieses Materials. Wählen Sie nun das tatsächlich verwendete Material aus.
-
Da im Schachtelplan auch die Menge definiert ist, die nach dem Schneiden als nutzbare Restmenge übrig bleibt, kann eine Restmengenberechnung durchgeführt werden. D.h. es werden die Los-Sollmengen aller Lose des Schachtelplans der laut Schachtelplan verbrauchten Menge gegenübergestellt und daraus ein Korrekturfaktor ermittelt mit dem die Lossollmengen umgerechnet / korrigiert werden. Damit wird erreicht, dass bei jedem Einlesen eines Schachtelplanes die verbleibende Restmenge einer Tafel zwischen Kieselstein ERP und PROfirst übereinstimmen. Zugleich wird bei diesem Vorgang nach der Korrektur der Sollmengen das gesamte Material der Lose dieses Schachtelplans ausgegeben, vom Lager in die Lose gebucht.
-
Ist die Tafel nun geschnitten, so muss dies ebenfalls in Kieselstein ERP erfasst werden. Klicken Sie dazu auf …. Es erscheint erneut die Abfrage nach dem Schachtelplan. Nun werden alle Lose dieses Schachtelplans mit deren Sollmengen angezeigt. Es kann nun bei jedem Los angegeben werden, ob eventuell Ausschuss zu erfassen ist. Geben Sie die unbrauchbaren Mengen für das jeweilige Los an und klicken Sie dann auf Erledigt/Buchen. Damit werden die angegebenen Lose mit den Losgrößen abzüglich den Ausschussmengen als Ablieferungsbuchung gebucht. Womit die Teile auf Lager sind und z.B. per Lieferschein ausgeliefert werden können.
Anmerkungen:
-
Da von ProFirst der Materialbedarf in x & y Abmessungen übergeben wird, sind die Dimensionen für m² und mm² in den Mengeneinheiten entsprechend auf 2 einzustellen.
-
Beim Erstellen neuer Bauteile in PROfirst achten Sie bitte darauf, dass die Bestellmenge immer 0,00 bleibt. Anderenfalls würden Sie mehr schachteln / produzieren als Sie aufgrund des offenen Auftragsstandes tatsächlich sollten.
-
Sollte ein Kunde einen Auftrag stornieren, so ist neben dem Storno des Loses auch die entsprechende offene Menge des Bauteils zu korrigieren / auf 0,00 zu setzen
Zuordnung der Tafelnummer zur Chargennummer
-
Bei der Buchung des Wareneinganges werden anstelle der Chargennummern, welche in der Regel bei der Anlieferung nicht sichtbar sind, Tafelnummern erfasst. Wichtig ist hier, dass die Tafelnummern bereits jede Tafel vereinzeln, d.h. für jede Tafel ist eine aufsteigende eigene Tafelnummer zu verwenden. Diese werden in der Zubuchung des Wareneinganges durch Klick auf “Tafelnummer” erzeugen generiert und für jede einzelne Tafel hinterlegt. Damit liegen die Tafeln mit diesen Nummern auf Lager. Die Tafelnummer ist der Ersatz für die Chargennummer. Das bedeutet auch, dass Tafeln die noch nicht in Chargennummern umgewandelt wurden –»> FRAGE: Umwandeln oder Ergänzen, in den Lagerinformationen eindeutig ersichtlich sind.
-
Die Tafelnummer wird in Kieselstein ERP in der Version der Charge abgelegt. Die eigentliche Chargennummer wird mit “noch nicht definiert” vorbesetzt. Die vergebenen Tafelnummern werden durch die Wareneingangsetiketten ausgedruckt und bei den jeweiligen Tafeln durch aufkleben auf die Tafeln bzw. deren Begleitpapiere identifiziert. (Z.B. ….) Die Tafelnummer ev. in Kombination mit der Artikelnummer wird auch in Barcodeform auf der Wareneingangsetikette angedruckt.
-
Zuordnung der Chargennummern zu den Tafelnummern. Durch die Entnahme der Tafel, welche einige Tonnen hat, wird deren Chargennummer sichtbar. Der Werker geht nun an das BDE-Terminal, identifiziert sich mit seiner Ausweiskarte, und tippt auf Tafelnummern zuordnen. Nun scannt er die Tafelnummer ein und tippt die Chargennummer, welche er sich vorher auf dem Tafelnummernetikett notiert hat, in das Terminal ein. Die Chargennummern sind durch Ziffern und normale Zeichen (keine Umlaute, keine Sonderzeichen (vor allem wiederum wegen Barcode)) definiert.
-
Aus Gründen der Rückverfolgbarkeit sollte die Zuordnung Tafelnummer <-> Chargennummer immer erhalten bleiben. Damit wird, je nach Menge der verarbeiteten Tafeln, die Anzahl der laufenden Stellen der Tafelnummern definiert. Da pro Tag und Schicht und Maschine ca. eine Tafel verarbeitet wird, ist bei drei Maschinen und Dreischichtigem Betrieb von 3285 Tafeln pro Jahr auszugehen. D.h. die Tafelnummern sind mindestens 6stellig auszulegen. Wir würden der Einfachheit und klareren Zuordnung halber, die Tafelnummern über alle Artikel ziehen. D.h. egal ob das ein Mittelformat mit 2mm oder ein 4x6mx10cm Blech ist, die eine Tafelnummer kommt nach der anderen.
-
Nachdrucken von Tafel-Etiketten. Diese können im Artikel unter Info, Etikett und Angabe der Chargennummer bzw. Tafelnummer jederzeit nachgedruckt werden.
Parametrierung für ProFirst
Die Profirst Artikeldaten (Parts) werden als Stücklisten Daten nach Kieselstein ERP importiert. Dazu wird von Kieselstein ERP direkt auf die Tabellen Ihres ProFirst Servers zu gegriffen. Um diesen Zugriff zu ermöglichen müssen folgende Parameter definiert werden:
| Parameter | Bedeutung | Beispiel |
|---|---|---|
| PRO_FIRST_DBURL | Der Pfad zu Ihrer Profirst Datenbank. Beachten Sie bitte dazu auch die untenstehenden Anmerkungen | jdbc:jtds:sqlserver://192.168.8.57:1433/profirst |
| PRO_FIRST_DBUSER | Der Benutzer für den DatenbankzugriffDie Details dazu erhalten Sie von Ihrem ProFirst Betreuer | |
| PRO_FIRST_DBPASSWORD | Das Kennwort um auf die Datenbank zuzugreifen | |
| PRO_FIRST_ANZAHL_ZU_IMPORTIERENDE_DATENSAETZE | Gibt die in einem Importdurchlauf aus ProFirst eingelesenen Stücklisten an. | Steht Default auf 1 um die Verbindung und den Import testen zu können. Erhöhen Sie diesen nach erfolgreicher Parametrierung auf zb. 50 Datensätze |
| ARTIKEL_MAXIMALELAENGE_ARTIKELNUMMER | Erlaubte Länge der Artikelnummer | 25 (Bitte auf Maximalwert stellen) |
| ARTIKEL_LAENGE_HERSTELLERBEZEICHNUNG | Kein Herstellerbezug | 0 |
| HERSTELLERKURZZEICHENAUTOMATIK | Abschalten | 0 |
| ARTIKELNUMMER_ZEICHENSATZ | Definieren Sie die erlaubten Zeichen. Bitte unbedingt ohne Leerstelle, zu Ihrer eigenen Sicherheit. | ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789-_. |
| ABMESSUNGEN_STATT_ZUSATZBEZ_IN_AUSWAHLLISTE | Damit werden die Blechdicken in der Artikelauswahl angezeigt | |
| PRO_FIRST_LEAD_IN_AZ_ARTIKEL | Definieren Sie hier bitte die führenden Buchstaben für die Artikel für die Tätigkeit | AZ_ |
| PRO_FIRST_VERZEICHNIS | In dieses Verzeichnis werden die von Kieselstein ERP erzeugten Exportdateien für ProFirst abgelegt.Bitte stellen Sie sicher, dass JEDER Benutzer auf dieses Verzeichnis ein entsprechendes Zugriffsrecht besitztWir raten zur Verwendung von UNC Namen, da diese in den Netzwerken eindeutig sind.Achten Sie darauf dass das angegebene Verzeichnis auch vorhanden ist. | \server\PROfirst\CSV\ |
| VERPACKUNGSMENGEN_EINGABE | Da in dieser Branche sehr oft in Tafeln gedacht wird, sollte dieser Parameter auf 1 gestellt werden. Damit erreichen Sie, gemeinsam mit der Hinterlegung der Verpackungsmenge, dass die Tafelanzahl auf den Bestelldaten mit angedruckt werden. | |
| PRO_FIRST_BILD_PFAD | Pfad in dem die von PROfirst automatisch erzeugten Bilder abgelegt werden. Diese werden in die Artikelkommentare der Stücklisten übernommen.Dieser Pfad muss aus Sicht des Kieselstein ERP Servers definiert werden. | Die Einstellung und die Definition in welchen Pfad Ihr PROfirst dies abspeichert finden Sie unter Extras, Optionen, Bauteil-BMP. Hier bitte die automatische Speicherung anhaken und den entsprechenden Pfad angeben. Als Dateiformat bitte JPG verwenden.Nutzen Sie für bestehende Daten den Knopf für bestehende Bauteile Bilder erzeugen.Beispiel: \\server\PROfirst\Bilder bedeutet bei einem Linux-Server aus Kieselstein ERP /mnt/profirst/Bilder |
| PRO_FIRST_FREMDFERTIGUNGSARTIKEL | Im PROfirst können auch Fremdarbeitskosten definiert werden. Diese werden im Zusatzfield5 (siehe unten) angegeben. Geben Sie hier die Artikelnummer an unter der diese Kosten in die Stückliste übernommen werden sollten. | AZ_FREMD |
| PRO_FIRST_ARTIKELGRUPPE | Die Artikelgruppe unter der Ihre PROfirst Artikel angelegt werden. Ist insbesondere dann erforderlich, wenn in Kieselstein ERP auch die integrierte Finanzbuchhaltung verwendet wird. | |
| PRO_FIRST_SCHACHTELPLAN_PFAD | Pfad in dem die Schachtelplan-CSV-Dateien gefunden werden.Importierte Schachtelpläne werden in das Unterverzeichnis Old verschoben. | |
| DEFAULT_ARBEITSZEITARTIKEL | Dieser Arbeitszeitartikel wird in den Arbeitsplänen der Stücklisten für die Tätigkeiten hinterlegt, bei denen in der Bauteildefinition Ihres PROfirst zwar eine Arbeitszeit aber keine Tätigkeit definiert ist. |
Die in PROfirst definierbaren Zusatzfelder werden wie folgt übernommen: Field1 … Verkaufspreisbasis des Artikels Field2 … Artikel Kurzbezeichnung welche üblicherweise für PROfirst Anwender mit Kundenartikelnummer bezeichnet ist Field3 … Artikel Referenznummer, welche üblicherweise für PROfirst Anwender mit Zeichnungsnummer bezeichnet ist Field4 … wird für die Darstellung der Fremdarbeitskosten verwendet. D.h. um diesen Zahlenwert zu übernehmen muss der PRO_FIRST_FREMDFERTIGUNGSARTIKEL definiert sein. Bitte beachten Sie, dass dessen Mengeneinheit EUR € sein sollte, da ja hier nur Kosten übergeben werden. Diese “Menge” = Kosten werden in die Stückliste als zusätzliche Materialposition übernommen. Field5 … Artikel Zusatzbezeichnung2 Field6 … Artikel Bauform, welche für PRfirst Anwender auch als Beschreibung bezeichnet ist Field7 … Artikel Verpackungsart -> dieses Feld wird von der PROfirst Version 9 nicht unterstützt Field8 … Wird von PROfirst Version 9 nicht unterstützt / verwendet und daher auch in Kieselstein ERP nicht ausgewertet
Damit die PROfirst Funktionen zur Verfügung stehen, muss zumindest die PRO_FIRST_DBURL definiert sein.
Zusätzlich achten Sie bitte am ProFirst Server, dass die TCPIP Verbindungen aktiv / erlaubt sind.
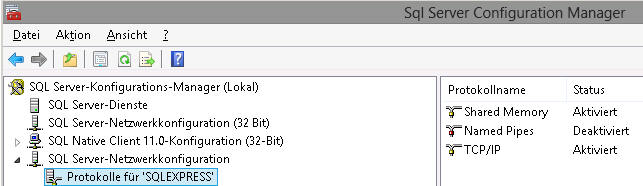
Und dass die entsprechenden Ports im SQL Configuration Manager eingestellt sind:
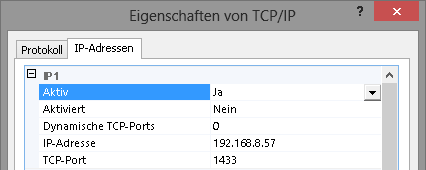
Testen Sie die Verbindung z.B. durch eine Verbindung mit dem SQL Manager:
Mögliche Fehlermeldungen
Ungültige Zeichen
 Grundsätzlich werden bei der Übernahme alle Zeichen auf Großbuchstaben umgesetzt. Sollten trotzdem nicht definierte Zeichen enthalten sein erhalten Sie eine Meldung ähnlich der obigen. Ergänzen Sie in diesem Falle die Definition der erlaubten Zeichen Ihrer Artikelnummer. In obigem Beispiel ist der . Punkt nicht definiert.
Der Import wird abgebrochen. Bitte ergänzen Sie die Artikelnummerndefinition oder ändern Sie den Namen in ProFirst
Grundsätzlich werden bei der Übernahme alle Zeichen auf Großbuchstaben umgesetzt. Sollten trotzdem nicht definierte Zeichen enthalten sein erhalten Sie eine Meldung ähnlich der obigen. Ergänzen Sie in diesem Falle die Definition der erlaubten Zeichen Ihrer Artikelnummer. In obigem Beispiel ist der . Punkt nicht definiert.
Der Import wird abgebrochen. Bitte ergänzen Sie die Artikelnummerndefinition oder ändern Sie den Namen in ProFirst
Kunde nicht definiert
 Generell ist die Definition, dass die Verbindung der Kunden zwischen Kieselstein ERP und ProFirst über die KundenKurzbezeichnung erfolgt. Wird kein Kunde mit der in ProFirst eingetragenen Kurzbezeichnung gefunden, so erscheint obige Fehlermeldung und der Import wird abgebrochen. Siehe unten / Kunden Import / ignorieren
Generell ist die Definition, dass die Verbindung der Kunden zwischen Kieselstein ERP und ProFirst über die KundenKurzbezeichnung erfolgt. Wird kein Kunde mit der in ProFirst eingetragenen Kurzbezeichnung gefunden, so erscheint obige Fehlermeldung und der Import wird abgebrochen. Siehe unten / Kunden Import / ignorieren
Arbeitzseitartikel nicht definiert
 Um die Arbeitszeitartikel von ProFirst in die Arbeitspläne von Kieselstein ERP übernehmen zu können, müssen diese definiert sein. Diese werden entsprechend dem Rulecode aus ProFirst übernommen. Diese Artikel müssen als Arbeitszeitartikel in Kieselstein ERP angelegt sein.
PROfirst Bauteile, die im PROfirst keine oder fehlerhafte Arbeitszeit-IDs (kein Rulecode oder Rulecode in Ruletabelle nicht vorhanden) werden auf den im Parameter DEFAULT_ARBEITSZEIT Arbeitszeitartikel gesetzt.
Um die Arbeitszeitartikel von ProFirst in die Arbeitspläne von Kieselstein ERP übernehmen zu können, müssen diese definiert sein. Diese werden entsprechend dem Rulecode aus ProFirst übernommen. Diese Artikel müssen als Arbeitszeitartikel in Kieselstein ERP angelegt sein.
PROfirst Bauteile, die im PROfirst keine oder fehlerhafte Arbeitszeit-IDs (kein Rulecode oder Rulecode in Ruletabelle nicht vorhanden) werden auf den im Parameter DEFAULT_ARBEITSZEIT Arbeitszeitartikel gesetzt.
Maschine nicht definiert
 Die bedeutet dass für die angegebene Maschine (aus PROfirst) keine Maschine in Ihrem Kieselstein ERP mit der entsprechenden Inventarnummer gefunden wurde. D.h. bitte entweder die Maschinendefinition in Ihrem PROfirst richtig stellen (siehe Liste der Bauteile der Maschine) oder die Maschine in Ihrem Kieselstein ERP anlegen (Zeiterfassung, unterer Reiter Maschinen). Bitte beachten Sie, dass die Inventarnummer mit der Maschinenbezeichnung in PROfirst übereinstimmen muss. In Kieselstein ERP ist die Inventarnummer auf 15Stellen begrenzt.
Die bedeutet dass für die angegebene Maschine (aus PROfirst) keine Maschine in Ihrem Kieselstein ERP mit der entsprechenden Inventarnummer gefunden wurde. D.h. bitte entweder die Maschinendefinition in Ihrem PROfirst richtig stellen (siehe Liste der Bauteile der Maschine) oder die Maschine in Ihrem Kieselstein ERP anlegen (Zeiterfassung, unterer Reiter Maschinen). Bitte beachten Sie, dass die Inventarnummer mit der Maschinenbezeichnung in PROfirst übereinstimmen muss. In Kieselstein ERP ist die Inventarnummer auf 15Stellen begrenzt.
Profirst Artikel und Stücklisten Import durchführen
Sind alle beschriebenen Einstellungen getroffen, so wählen Sie im Artikelmodul bitte Pflege, ProFirst Import. Damit wird die jeweilige Anzahl an neuen Datensätzen eingelesen. Bitte beachten Sie, dass wir, so wie es in der Praxis üblich ist, davon ausgehen, dass die Artikel in ProFirst erst abgespeichert werden, wenn diese eindeutig definiert sind. Da der Import parallel von mehreren Mitarbeitern angestoßen werden kann, aber nicht sollte, würden unter Umständen nicht fertig definierte Artikel importiert. Wir haben uns daher dazu entschlossen, dass ein Artikel nur einmal eingelesen wird.
Aus dem Namen des ProFirst Artikels werden die Artikelnummern gebildet. Würde sich daraus eine gleichlautende (doppelte) Artikelnummer ergeben, so werden die letzten Stellen durch _nnn hochgezählt. In die Bezeichnung wird der original Name eingetragen. Bitte beachten Sie, dass Artikel deren Namen eine Artikelnummer ergeben würden, die kürzer als die Mindeststellenanzahl, üblicherweise 5, ist, ignoriert werden.
Der Import wird immer so durchgeführt, dass Artikel für Artikel eingelesen und die Stücklisten daraus erzeugt werden. Kommt es nun zu einem Abbruch, wegen eines Fehlers, eine ungültigen Definition, so wurden alle Artikel bis zum Auftreten des Fehleres bereits eingelesen und sind bereits in Ihrem Kieselstein ERP vorhanden. D.h. wenn nun der Fehler korrigiert wird, so wird exakt bei dieser Fehlerbedingung wieder fortgesetzt und erneut eine bestimmte Anzahl an Datensätzen eingelesen.
Um die direkte Verknüpfung der Stücklisten zwischen Kieselstein ERP und ProFirst eindeutig darzustellen, wird die ProFirst PART.IDPART in der Stückliste in den Kopfdaten unter Fremdsystemnr. abgelegt. Damit kann Programmtechnisch eindeutig auf den richtigen Artikel in ProFirst zurückgegriffen werden. Für den Import wird von der höchsten in Kieselstein ERP hinterlegten Fremdsystemnr. ausgegangen und die danach kommenden Artikel eingelesen.
Wareneingänge nach Profirst exportieren
Um die im Wareneingang erfassten Tafeln auch an ProFirst zu signalisieren wurde diese Funktion geschaffen. Sie finden diese ebenfalls im Modul Artikel, Pflege, Export Wareneingang nach ProFirst. Es werden damit alle Wareneingänge seit dem letzten Exportlauf an Profirst über den Umweg einer CSV Datei übertragen.
Bitte beachten Sie dass dies ein einmaliger Vorgang ist. Nachträgliche Änderungen an den Warenzugangsbuchungen werden NICHT an ProFirst übergeben. Die Exportdatei wird ebenfalls im definierten Profirst Exportverzeichnis abgelegt und beginnt mit WE_AB_Datum-Uhrzeit
Um die Daten nach ProFirst zu importieren, starten Sie bitte Ihr ProFirst, wählen dann
 CAM, CAM Medium.
CAM, CAM Medium.
Klicken Sie nun unten auf Blechverwaltung
nun wählen Sie
 Tafeln einlesen.
Tafeln einlesen.
Geben Sie hier den unter PRO_FIRST_VERZEICHNIS definierten Pfad ein und definieren Sie den Import anhand folgender Spalten: Tafelnummer Material ArtikelnummerMaterial Staerke Breite Tiefe Chargennummer AnzahlTafeln Lieferant Dokument Preis/Kilo Werkstoff
Da üblicherweise nicht nur die verschiedenen Standardformate (Klein, Mittel, Groß) sondern auch Sonderformate verarbeitet werden, kann in der Wareneingangsposition die Breite / Tiefe (in mm) angegeben werden. Dazu muss in den Parametern die Dimension der BS-Pos-Einheit auf 2 gestellt werden.
Export der zu schneidenden Lose / Arbeitsgänge
Verwenden Sie für die Signalisierung der von Ihnen gewünschten zu schneidenden Lose bzw. Arbeitsgänge im Modul Los den unteren Modulreiter offene AGs und dann den oberen Reiter [Produzieren](../Fertigung/index.htm#Welche Lose können produziert werden).
Hier filtern Sie zuerst nach dem Material dass Sie schneiden möchten z.B. durch Eingabe der Artikelnummer des Materials.

Sortieren Sie nun die Lose in der Reihenfolge in der diese gefertigt werden sollten. In der Regel wird das der AG-Beginn sein.
Sind hier Spalten OHNE AG-Beginn, so gibt es für diese Lose keine Arbeitsgänge, was bei importierten Stücklisten nicht sein sollte. Siehe oben.
Für die Sortierung klicken Sie nun auf die Spaltenüberschrift AG-Beginn.
Klicken Sie nun die Lose an, die Sie nach PROfirst zum Schachteln übertragen wollen. Damit Sie ein Gefühl dafür bekommen, ob denn die ausgewählten Lose auf die Tafel geschachtelt werden können, zeigen wir oben die Summe der Abmessungen der Materialien der markierten Lose an. Beachten Sie bitte, dass dies nur die mathematische Addition der in den Stücklisten eingetragenen Flächen ist. Es ist dies in keinem Falle ein wie immer gearteter Schachtelversuch. Nutzen Sie auch die Anzeige heute produzierbar, diese zeigt ob überhaupt ausreichend Material auf Lager ist.
Haben Sie nun alle Lose für die Übertragung markiert, so klicken Sie bitte auf  nach PROfirst exportieren. Damit werden alle markierten Lose in die CSV Exportdatei exportiert.
Der Export wird durch
nach PROfirst exportieren. Damit werden alle markierten Lose in die CSV Exportdatei exportiert.
Der Export wird durch 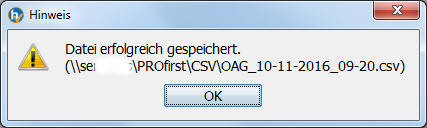 angezeigt.
Der Dateiname hat den Aufbau OAG-Datum-Uhrzeit.csv.
angezeigt.
Der Dateiname hat den Aufbau OAG-Datum-Uhrzeit.csv.
Zusätzlich wird das jeweilige Los mit dem Zusatzstatus P1 markiert. Hinterlegen Sie hinter diesem Zusatzstatus ein entsprechendes Symbol und den für Sie passenden Begriff. Damit sehen Sie bereits in der Losübersicht, welche Lose zum Schachteln an ProFirst übergeben wurden. Hinweis: Damit das neue Symbol angezeigt wird, muss der Kieselstein ERP Client neu gestartet werden. Wann diese Daten an ProFirst übergeben wurden, ist je Los im Reiter Zusatzstatus ersichtlich.
Der Datenaufbau sieht z.B. wie folgt aus: KundeKbez,Losnummer,StklArtikelnummerProFirst,OffeneLosmenge,MaterialProFirst,MaterialHoehe,,,, Test,16/0000001,696-419-01-01-05,35,S355,25.0
Importieren Sie diese Daten in ProFirst unter CAM Medium, Fertigungsaufträge
 Auftrag von PPS ein(lesen).
Auftrag von PPS ein(lesen).
Bitte beachten Sie dass dadurch das Los noch immer im Status angelegt ist. D.h. Buchungstechnisch ist das Material noch im Lager. Erst durch die Rückmeldung der Schachtelung wird das Los ausgegeben und damit das Material vom Lager abgebucht.
Einstellung des PROfirst für den Import
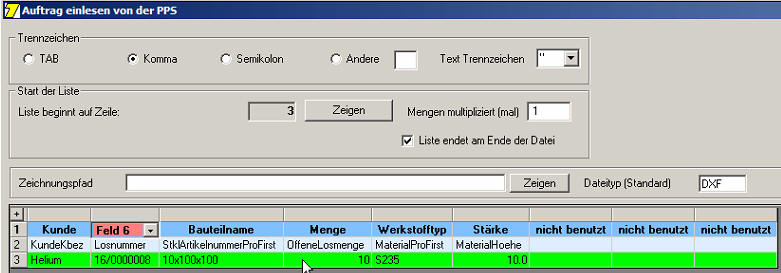
Für den Ablauf ist wichtig, dass die Verwaltung der offenen, d.h. der zu schneidenden Mengen in beiden Systemen gleich ist.
wie können Stücklisten aktualisiert werden?
hierfür stehen zwei Varianten zur Verfügung:
- a.) Aktualisieren einer einzelnen Stückliste. Wechseln Sie dazu im Stücklisten Modul auf die gewünschte Stückliste und wählen nun im Menü Bearbeiten, Stückliste aus PROfirst aktualisieren.
- b.) Aktualisieren aller Stücklisten eines Kunden. Wechseln Sie im Kundenmodul auf den gewünschten Kunden und wählen aus dem Menü, Pflege, PROfirst Import. Bitte beachten Sie, dass hier die Begrenzung auf die maximale Anzahl der zu importierenden Artikel NICHT wirkt. D.h. es werden alle Artikel dieses Kunden eingelesen. Es ist dieser Import jedoch auf ein reines Aktualisieren begrenzt. D.h. es werden nur die bereits in Kieselstein ERP eingetragenen Stücklisten aktualisiert. Das Einlesen neuer Artikel muss bitte immer im Artikelmodul, Pflege, PROfirst Import erfolgen (Hintergrund ist die Verwaltung der noch einzulesenden Artikel).
In anderen Worten ist die Bauteilübernahme aus PROfirst wie folgt definiert:
-
Kunde pflegt die bestehenden Artikel / Stücklisten ausgehend von PROfirst zu Kieselstein ERP
-
Artikel fügt hinzu: Es werden Bauteile die anhand ihrer PROfirst ID noch nicht im Artikel / Stücklistenstamm von Kieselstein ERP sind hinzugefügt = neu angelegt
Wie wird mit Verkaufspreisänderungen umgegangen?
Bei jeder Aktualisierung werden auch die aktuellen Verkaufspreise aus PROfirst übernommen und das Preis gültig ab Datum auf das Importdatum gesetzt. Somit sehen Sie im Artikel unter Info, Verkaufspreisentwicklung, wie sich der Preis im Laufe der Zeit veränder hat.
Können Kunden vom Import ausgenommen werden.
Ja. Wenn über den Import im Artikelmodul die Fehlermeldung Kundenkurzbezeichnung für xyz nicht gefunden, so wählen Sie Kunde für weitere Importe ignorieren. Damit wird der Kunde in die zu ignorieren Liste mit aufgenommen und beim nächsten Importlauf übersprungen. Sollten Sie die Artikel dieses Kunden später trotzdem importieren wollen, so legen Sie bitte den Kunden an bzw. definieren Sie die entsprechende Kundenkurzbezeichnung eines bestehenden Kunden und wählen Sie dann Pflege, PROfirst Import, wie oben beschrieben. Die nun erscheinende Frage beantworten Sie bitte mit Ja.
Einfache Beschreibung des grundsätzlichen Ablaufes
-
Importieren Sie alle benötigten Artikel
-
Legen Sie die Kundenaufträge an
-
erzeugen Sie die entsprechenden Lose, z.B. mit der internen Bestellung
-
Bestellen Sie die nötigen Rohartikel, z.B. Blechtafeln
-
Buchen Sie die Lieferungen im Wareneingang zu. Achten Sie darauf dass die Blechtafeln entsprechend Chargengeführt sind (es muss die Abfrage nach Chargennummern kommen)
-
Exportieren Sie im Modul Los, unterer Reiter offene AGs oberer Reiter Produzieren Beachten Sie die produzierbaren Lose nach Sortierung
-
Schachteln Sie die gewünschten Aufträge im PROfirst
-
Einlesen eines Schachtelplanes in Kieselstein ERP. Damit automatische Zuordnung der Schachtelplannummern zu den Losen.
-
Schneiden der Schachtelpläne
-
Abliefern der Schachtelpläne = Tafel abliefern unter Angabe des eventuellen Ausschusses Dabei Auswahl der tatsächlich verwendeten Tafel
19 - Knowledge
Praktisches Wissen rund um dein Kieselstein ERP
Aufgrund des Wunsches der Mitglieder, eine lose Sammlung an praktischen Bedienungsdingen für Betriebssysteme und Datenbank, die man selten aber doch immer wieder einmal braucht.
Gedacht ist dies für Menschen, die ihre Systeme selbst administrieren und damit auch wissen was sie tun und die Verantwortung dafür übernehmen können und wollen.
Windows
Windows Defender
Als Virenscanner einrichten, dass so aktuell wie möglich
Signatur Update Intervall
Registry Hive HKEY_LOCAL_MACHINE
Registry Path Software\Policies\Microsoft\Windows Defender\Signature Updates
Value Name SignatureUpdateInterval
Value Type REG_DWORD
Enabled Value 1 1 - 24 Stunden
Disabled Value 0
Bearbeiten und Gruppenrichtlinien Editor /Windowstaste, Gruppenrichtlinie
Computerkonfiguration
Administrative Vorlagen
Windows-Komponenten
Microsoft Defender Antivirus
Aktualisierung der Sicherheitsinformationen
Intervall für die Suche nach Updates der Sicherheitsinformationen
DNS Puffer neu initialisieren
ipconfig /flushdns
Filezugriff
Zugriff von alten Windows-Rechner (XP aber teilweise auch Linux) auf Win7 und höher Freigaben
Auf der Win10 (dorthin wo man den Zugriff möchte) im Systemsteuerung, Windows Programme und Features, Windowsfeatures, Unterstützung für SMB 1.0 suchen und zumindest den SMB 1.0 Server freischalten.
Danach den Rechner neu starten.
laufende Prozesse
netstat -nao
liefert auch die Prozessnumer um damit über den Taskmanager den richtigen Javaprozess killen zu können.
Druckaufträge bleiben hängen.
Passiert komischerweise seit einiger Zeit auf den aktuellen Windows10 usw. Installationen
Ursache, es scheint eine temporäre Datei hängen zu bleiben.
Lösung:
- Spoolerdienst = Druckwarteschlange beenden
- Drucker abschalten
- c:\windows\system32\spool\PRINTERS
alle Dateien entfernen.
Es müssen sich alle Dateien lösche lassen.
Wenn nicht läuft vermutlich der printfilterpipelinesve.exe noch. Dieses über den Taskmanager beenden. - Drucker wieder einschalten
- Druckwarteschlange wieder starten
- Wenn keine Druckjobs anstehen muss dieses Verzeichnis leer sein.
Freigaben
net share liefert alle Freigaben dieses Rechners
sieht man auch in der Computerverwaltung, System, freigegebene Ordner, Freigaben und kann da die Freigaben auch löschen
Kein Zugriff auf Freigaben möglich
Der Status des Netzwerkes hat sich wieder mal bei einem Update auf öffentliches Netzwerk geändert.
Man geht in die Einstellungen und wechselt dort zu “Netzwerk und Internet”.
Unter Status klickt ihr auf “Verbindungseigenschaften ändern”.
Anschließend könnt ihr durch die Aktivierung des jeweiligen Schalters von “Öffentlich” in “Privat” wechseln oder umgekehrt
oft ist das aber nicht genau so, dann kann man
- Status, weiter auf Ethernet
- da findet man dann das verbunde Netzwerk und da dann auf das Symbol klicken
- und das Netzwerkprofil auf Privat ändern
Bei Netzwerkstatus (im Dialog Status) muss dann Privat stehen
Dann geht auch der RDP Zugriff wieder
Schnellzugriff Einstellungen
Mit der Tastenkombination “Windows + I” die Windows 10-Einstellungen und wechselt dort zu “Netzwerk und Internet”.
Aktuelles Datum und aktuelle Uhrzeit in den Dateinamen einsetzen
Manchmal ist es sinnvoll, in einen Dateinamen auch das Datum der Erstellung mit hinein zu nehmen. Damit kann man dann die verschiedenen Versionen der Datei sehr einfach und schnell unterscheiden.
Es gibt im Kommandozeilenmodus von Windows die Variablen
%DATE% = Datum in der FormTT.MM.JJJJ
und
%TIME% = Zeit In der Form HH:MM:SS
Darüber hinaus kann man auch noch das Format und die Reihenfolge der einzelnen Teile des Datums und der Uhrzeit bestimmen:
%DATE:~6,4% = Jahreszahl vierstellig
%DATE:~3,2% = Monatszahl zweistellig
%DATE:~0,2% = Tageszahl zweistellig
%TIME:~0,2%= Stundenzahl zweistellig
%TIME:~3,2% = Minutenzahl zweistellig
%TIME:~6,2% = Sekundenzahl zweistellig
Hier ist ein Beispiel:
ren Test.txt Test"%DATE:~6,4%.%DATE:~3,2%.%DATE:~0,2%-%TIME:~0,2%.%TIME:~3,2%-%TIME:~6,2%".txt
ergibt
Test2011.12.05-21.13-37.txt
Man kann mit diesen Variablen auch Ordner erstellen, kopieren oder oder umbenennen.
Beispiele:
Einen Ordner erstellen md “%date%-%time:~0,2%-%time:~3,2%-%time:~6,2%"
xcopy ordner “%date%-%time:~0,2%.%time:~3,2%-%time:~6,2%"
USB Stick auf Read Only setzen
Method 1. Manually Remove Read-only with DiskPart CMD
Click on your "Start Menu", type cmd in the search bar, then hit "Enter".
Type command diskpart and hit "Enter".
Type list disk and hit "Enter". (
Type the command select disk 0 and hit "Enter".
Type attributes disk clear readonly and hit "Enter".
Zum Setzen: attributes disk set readonly eingeben.
Speichertest integriert
mdsched.exe
Zuordnung MAC Adressen / IP Adressen
arp -a liefert alle seit, … aufgerufenen IP Adressen und deren MAC Adresse dazu
BatchCommandos Übersicht
Autostart abschalten
Autostart auf Win10 abschalten mit Autoruns aus Sysinternals Download von
Als Administrator ausführen
Vorsichtig abhaken der nicht gewünschten Funktionen
Windows Rebooten mit Sprung ins Bios
Ctrl+left+Shift+Windows und dann Reboot mit der Maus
Geht beim Neustart ins Bootmenü
Drucken über Remotedesktop
- Auch Thinstuff druckt normal über den RDP Printer
- geht normalerweise problemlos
- Zum Testen als erstes auf den umgeleiteten Microsoft PDF Drucker drucken
Dieser legt die Dateien im RDP Aufrufverzeichnis ab
Geht auch über mehrere Ebenen dann auf die Wurzel der RDP Verbindung - mit Konica Minolta
- Es muss der SMB Client & Server 1.0 eingerichtet sein
- Es sollten die aktuellsten Treiber von Konica Minolta AT!!! verwendet werden
- Ev. den Drucker LOKAL freigeben
- Win10 / Win11
- getestet auf Win10 mit Thinstuff und lokaler Rechner Win11
Schnelldump der KIESELSTEIN Datenbank
ohne Bilder, Versandaufträge usw.. Also klein und schnell erstellt
“?:\Program Files\PostgreSQL\14\bin\pg_dump.exe” -Fc -h localhost -U postgres –exclude-table-data=public.ww_artikelkommentarspr –exclude-table-data=public.rekla_reklamationbild –exclude-table-data=public.lp_entitylog –exclude-table-data=public.lp_installer –exclude-table-data=public.lp_usercount –exclude-table-data=public.lp_versandauftrag –exclude-table-data=public.lp_versandanhang –verbose -f KIESELSTEIN_SMALL.backup KIESELSTEIN
Linux
allgemein
| Zweck | Befehl | Wirkung / Beschreibung |
|---|---|---|
| File finden | find -iname *hba*.* | findet pg_hba.conf |
| Owner ändern | chown –R root report | Ändert ab report und tiefer (-R) den Owner auf root. Danach können z.B. die Reports über den WinScp einkopiert werden |
| Direkt Rechte ändern | chmod -R 777 verzeichnis | Bedeutet im verzeichnis dürfen alle alles |
| User einer Gruppe hinzufügen | usermod -aG Gruppe User | |
| als root arbeiten | su root | und Passwort |
| als vollwertiger root arbeiten | su - root | nur damit verhält das OS sich wie wenn man sich als root angemeldet hätte |
| Service ein / ausschalten | chkconfig jboss on oder off | Beim Start wird der Service ausgeführt oder eben nicht |
| Liste der installierten Services | systemctl list-unit-files | |
| Liste filtern | grep xxxx | listet nur Zeilen die xxxx enthalten |
| Editor | vi filename | Mühsam zu bedienender standard Linux Editor vi Commandos mit : einleiten, also :q! -> raus ohne änderungen :wq -> raus und schreiben |
| Editor | nano filename | ausreichend komfortabler Editor. Ist auf den meisten Linuxen installiert |
| Dienste starten / Stoppen | systemctl start/stop/restart Dienstname | übliche Dienstnamen: kieselstein postgresql jeweils mit TAB vervollständigen |
| Neues Verzeichnis | mkdir | erzeuge neues Verzeichnis |
| Directory Listing | ls -al | Directory Listing mit allen Infos |
| Verzeichnis leeren | rm * -R | -> im Ubuntu leere das gesamte verzeichnis |
| Verzeichnis löschen | rmdir Verzeichnis | löscht ein leeres Verzeichnis |
| Verzeichnis umbenennen | mv old new | old auf new umbenennen |
| ausführliches Directory Listing | ls -alh | List Directory alle Attribute Langformat Human Readable |
| Freier Plattenplatz | df -hl | zeigt freien Speicherplatz des lokalen Dateisystems |
| Welche IP hört auf welchem Port | netstat -anlp | listet alle laufenden IP-Listener und die zugehörigen Programme die da horchen |
| Prozesse auflisten | ps -axf | listet alle Prozesse und deren Aufrufparameter z.B. ps -axf | grep -i test liefert den Prozessstatus mit den Aufrufparametern (-i = ignore Case beim Wort danach) |
| Prozess beenden | kill -9 PID | Beendet den Prozess (PID) in jedem Falle |
| Aufgabenplanung | crontab -e | bei Ubuntu: /etc/crontab (Ist vi, d.h. mit :wq beenden |
| File laufend anzeigen | tail Filename -f | zeigt andauernd die aktualisierten Inhalte des (Log-) Files an |
| Umgebungsvariablen auslesen | env | |
| Umgebungsvariablen auslesen | env | grep JAVA_HOME | Zeigt den Wert (Pfad) von Java_Home |
pg_hba.conf
liegt je nach Betriebssystem / Linux wo anders
- Ubunut etc/p…..
- var/lib/p…
- usr/lib/p…
Installation der MS-Fonts (Arial usw.)
apt-get install ttf-mscorefonts-installer
Anmerkung: Die EULA muss bestätigt werden. Damit man zum OK kommt, mit die TAB-taste drücken und dann Enter bzw. Space
sudo fc-cache -fv
mount
- a.) das Verzeichnis (/mnt/datastore) muss es geben sonst mit mkdir anlegen
- b.) das Filesystem muss es auch geben, muss am Linux verfügbar sein
- c.) wenn im PW !, dann mit \ escapen
- d.) mount -t nfs 192.168.0.40:/opt/kieselstein/postgres_datastore_xxxx/ /mnt/datastore
nfs = Filesystem, der abschließende Slash ist wichtig
WICHTIG: Es muss dies auch freigegeben werden. Dazu im WebMin(Port 10000) unter Netzwerk NFS Exporte eintragen von welchem Rechner zugegriffen wird
Debian
ip adress für ifconfig
apt install htop
shutdown -> systemctl poweroff
Ubuntu
Dateien mit Doppelklick starten
Rechte Maus auf die Datei, unten Eigenschaften, Reiter öffnen mit
nun unter weitere Anwendungen, Anwendung starten auswählen
useradd … neue User anlegen
angelegte User findet man im File /etc/passwd passwd BENUTZERNAME und dann das neue Passwort eingeben
ssh Zugriff nicht eingerichtet (ubuntu 14.04 LTS)
apt-get install openssh-server …. herunterladen
danach starten … /etc/init.d/ssh restart
Netzwerkadressen
ändern über Console (wenn installiert)
- nmtui (ist eine Terminal gui für Netzwerkeinstellungen)
- yum install nmtui
Grafisch
IP-Adresse kann man im Ubuntu über die Einstellungen ändern
Suse
Java liegt gegenüber allen anderen Linux Distributionen unter
CentOS (RedHat)
Datum stellen:
date MMDDhhmm[[CC]YY][.ss]
date MMTThhmmJJ
hwclock -w … schreibt die gesetzte Uhrzeit in die Hardwareclock
yum install htop
Small-Backup der Kieselstein
pg_dump -Fc -h localhost -U postgres –exclude-table-data=public.ww_artikelkommentarspr –exclude-table-data=public.rekla_reklamationbild –exclude-table-data=public.lp_entitylog –exclude-table-data=public.lp_installer –exclude-table-data=public.lp_usercount –exclude-table-data=public.lp_versandauftrag –exclude-table-data=public.lp_versandanhang –verbose -f KIESELSTEIN_SMALL.backup KIESELSTEIN
Backup der Kieselstein
pg_dump -Fc -h localhost -U postgres -f ./KIESELSTEIN.backup KIESELSTEIN
TCPDUMP
TCPDUMP, also wie laufen denn so die Pakete sehr tief unten sudo tcpdump ’tcp port 8280’ -A -l
MAC
Wenn man im Finder verschiedene Devices usw. nicht findet, dann am Desktop auf Gehe Zu (Computer) und dann dieses Device links reinziehen. Ab dem Zeitpunkt ist es da.
Ab OS X Version 8? steht der Launcher zum Starten der Dienste zur Verfügung:
launchctkl start/stop dienst
mit list sieht man alle Dienste und die die eine PID haben laufen
start durch: launchctl load Dienst / Pfad auf plist
stop durch: launchctl unload Dienst / Pfad auf plist
find / -name xxx*.* findet alle Dateien ab Root
Rechtsklick mit der Maus bringt Einsetzen (aus der zwischenablage)
Einrichtung
- Zugriff auf die plist: Im Finder zeigen, Paket Inhalt zeigen, Content, info.plist
- Zugriff auf die Info.plist Rechts auf Icon, Paketinhalt zeigen, Content, info.plist, rechts-Klick, öffnen mit Texteditor
SQL, PostgresQL
Wechsel von pgAdmin 7 auf 8
Es verschiebt sich der Pfad der Runtime. Damit geht gegebenenfalls die nachträglich manuell ergänzte Pfad-Definition nicht mehr Windows, System, erweiterte Systemeinstellungen, Umgebungsvariablen
Restore
pg_restore -c -h localhost -U postgres -d KIESELSTEIN KIESELSTEIN.backup » restore.log Vorher die KIESELSTEIN z.B. über pgadmin oder mit createDB aus ..\database anlegen
noch einsortieren
Postgres reload im laufenden Betrieb, z.B. wenn IP Adressen nicht freigeschaltet sind /etc/postgresql/14/main/pg_hba.conf su postgres /usr/lib/postgresql/14/bin/pg_ctl -D /var/lib/postgresql/14/main reload
aufruf von psql.exe a.) es reicht aus dem pgadmin das runtime Verzeichnis zu kopieren b.) bei der Angabe des Hostnamens entscheidet das führende Slash ob Socket Communication (was im Linux nicht unterstützt wird) wenn –host OHNE / angegeben wird, wird eine TCPIP Kommunikation angenommen, die dann nur mehr über das pg_hba.conf gesteuert wird c.) im Debian und Postgres 14 ist die pg_hba.conf im etc
Postgres Password Reset des Users Postgres Siehe auch
- C:\Program Files\PostgreSQL\12\data\pg_hba.conf
- sichern der pg_hba.conf
- Ändern aller Connection von md5 auf trust
- Restart des Postgres Dienstes über die Dienste oder mit pg_ctl -D “C:\Program Files\PostgreSQL\12\data” restart The “C:\Program Files\PostgreSQL\12\data” is the data directory.
- Connect to PostgreSQL database server using any tool such as psql or pgAdmin: psql -U postgres PostgreSQL will not require a password to login.
- Setzen des neuen Passwords für den User Postgres postgres=# ALTER USER postgres WITH PASSWORD ’new_password';
- Wiederherstellen der original pg_hba.conf
- Restart des Postgres Dienstes
Rest des PGAdmin Master-Passwords Siehe auch
- Beim Anmelde Dialog, bei dem das Master Password abgefragt wird, einfach Reset Master Password anklicken.
Damit werden alle, in einer lokalen SQLite DB abgelegten Passwörter gelöscht.
Datentypen
numeric -> BigDecimal -> Sum liefert immer numeric und damit BigDecimal
Uhrzeit rechnen
Wenn man Uhrzeit1 von Uhrzeit2 abziehen will, und beides sind Timestamp without timezone, dann select extract(epoch from danach.t_zeit) from pers_zeitdaten liefert nur Sekunden als numeric, mit denen kann man dann aber einen Sum machen
mehrere Fields mit Trennzeichen zusammenhängen
SELECT string_agg(c_lagerplatz::text, ‘,’) AS Name FROM ww_artikellagerplaetze inner join ww_lagerplatz on ww_lagerplatz.i_id=ww_artikellagerplaetze.lagerplatz_i_id where artikel_i_id=(select i_id from ww_artikel where c_nr=‘ABCD1234’)
suchen
Symbol Meaning LIKE ‘5[%]’ 5% LIKE ‘[_]n’ _n
Null-Werte auf definierten Wert setzen
COALESCE
coalesce geht nur wenn ein Ergebnis kommt, kommt keines, also im PGadmin keine Zeile, dann wirkt dies nicht. Daher immer so aufbauen, dass ein Null-Ergebnis überhaupt theoretisch kommen kann.
Z.B mit left outer join
Zu Datum Tage dazuzählen
date+1 geht nicht immer
Daher besser:
(ww_artikelreservierung.t_liefertermin - interval ‘1’ day * COALESCE(part_kunde.i_lieferdauer,2)) as t_liefertermin verwenden
Es geht auch aus einem Timestamp
select DATE(pers_zeitdaten.t_zeit) || ’ 00:00:00’, * from pers_zeitdaten where i_id = 4003090 select to_char(t_zeit, ‘YYYY-MM-DD 00:00:00’), * from pers_zeitdaten where i_id = 4003090
Mit dem to Char kann noch wesentlich mehr gemacht werden siehe
UND WICHTIG: Will man z.B. zwei Timestamps vergleichen ob sie am gleichen Tag sind, dann einfach
DATE(pzd.t_zeit) = DATE(pers_zeitdaten.t_zeit)
Wochentagsnamen aus einem Timestamp
select to_char(t_datum, ‘Day’), * from pers_betriebskalender
gibt man als Formater nur Dy an, so kommen die Tagesnamen mit den ersten beiden Buchstaben. In der Regel in englisch.
Mit substring(to_char(t_datum, ‘Day’),1,1) != ‘S’ dann das Wochenende herausfiltern
Tabellen zusammenhängen
Union all
die Spaltennamen durch das as müssen alle gleich sein
Anzahl der unterschiedlichen Einträge der Maschinen_I_ID’s zählen
“select count(distinct(MASCHINE_I_ID)) from PERS_MASCHINENZEITDATEN where LOSSOLLARBEITSPLAN_I_ID="+$F{lossollarbeitsplan_i_id}+” “+
Anzahl der unterschiedlichen Artikel
z.B. im Los
select count(distinct artikel_i_id) from fert_lossollmaterial
inner join fert_los on fert_los.i_id=fert_lossollmaterial.los_i_id
inner join ww_artikel on ww_artikel.i_id=fert_lossollmaterial.artikel_i_id
where fert_los.c_nr like ‘24%’
and ww_artikel.artikelart_c_nr = ‘Artikel’;
Anzahl der unterschiedlichen Stücklisten in den Losen verwendet
select count(distinct stueckliste_i_id) from fert_los where fert_los.c_nr like ‘24%’;
Felder in der Datenbank finden
Man hat immer wieder die Herausforderung, dass man in einer Installation vor zig Jahren, Felder übersteuert hat. Und dann will man auch noch wissen, in welcher Tabelle, denn das gesuchte Feld ist.
In diesem Falle wollte der Anwender die Mindesthaltbarkeit, die man wunderbar im Artikel sieht, auf verschiedenen Formularen angedruckt haben. Es gibt aber diese Mindesthaltbarkeit in der Datenbank nicht. Wie also finden.
- Suchen der Übersteuerung des Textes
select * from lp_text where c_text like 'Mindest%' -->> garantiezeit
- Suchen in welchem Datenbankfeld das nun tatsächlich enthalten ist
SELECT table_name, * FROM information_schema.columns where column_name LIKE '%garant%' and table_name like 'ww_%'
Report
Libre Office, Calc
Interessante Funktionen und deren Namen
| Funktion | Beschreibung |
|---|---|
| Abrunden | Rundet immer die angegebenen Stellen ab |
| Runden | Rundet mathematisch, vermutlich nicht Bankers Rounding |
| Aufrunden | Rundet immer auf |
| VRunden | klingt wie Modulo |
| suchen | Suchzeichen und Zelle. Wenn nichts gefunden liefert #WERT! |
| wennfehler | Zelle die zu lesen ist, steht hier ein Fehler (#WERT!) dann wird die Zahl/Wert.. dahinter ausgegeben Z.B. wenn bei Suchen das Zeichen nicht kommt, dann z.B. 0 (=wennfehler(E2;0)) entweder der Wert aus E2, wenn aber Fehler, dann 0 |
| Teil | Substring mit Zelle; Beginn; Länge |
| Verketten | Zusammenhängen mehrerer Stringfelder zu einem String. Nutze ich gerne um SQL Strings zu erzeugen |
KI, AI
Die sogenannte künstliche Intelligenz
Der Versuch, Menschen in einen Datensatz zu verwandeln, ist Teil einer Kultur des Todes, die alles, was Leben ausmacht
Spontaneität, fühlendes Erleben, Selbstorganisation und Kreativität,
durch Abstraktion und Berechnung ersetzt.
Ihr Fluchtpunkt ist ein wüstenartiger Planet, auf dem einsam im dunklen Weltall ein blinkender Riesenrechner steht, der anzeigt, wie viel Geld er gerade verdient.
Fabian Scheidler
Der Stoff aus dem wir sind
2.Auflage 2021
20 - Datenübernahme
Datenübernahme von anderen Systemen
Da auch immer wieder die Frage kommt, wie bekommt man aus anderen ERP Systemen, die Daten in das Kieselstein ERP.
Der Klassiker von beliebigen anderen Systemen ist, dass die Stammdaten inkl. Stücklisten per XLS Datei importiert werden. Es ist dafür erforderlich, dass die Daten vom Alt-System entsprechend zur Verfügung gestellt werden.
Eine Übernahme von Bewegungsdaten, also Angeboten bis Lieferscheine und Rechnungen, Bestellungen, Wareneingänge, Fertigungsaufträgen, usw. ist zwar theoretisch möglich, aber immer mit einem enormen Aufwand verbunden.
Es kommt ergänzend dazu, dass auch die in Dokumentenmanagementsystemen abgelegten Belege übernommen werden sollten, was mit einem enormen Aufwand verbunden ist.
Die Datenübernahme aus dem ERP-System HELIUM V, dessen Fork das Kieselstein ERP ist, ist unter gewissen Umständen sehr einfach möglich.
Was ist für die Umstellung von HELIUM V auf Kieselstein-ERP alles vorzubereiten, zu beachten. Es werden alle Daten auf Knopfdruck, innerhalb kurzer Zeit, nach entsprechender Vorbereitung und von einem guten Backup übernommen. Also:
- Datenbanken (sowohl ERP Daten wie Dokumenten-Daten)
- Formulare
Wichtige Voraussetzung:
Gültige Softwarepflege / Miete für HELIUM V bis inkl. September 2022
Die Daten gehören laut europäischem Recht dem Anwender, also dir, denn die Arbeit die Daten im ERP-System zu erfassen ist beim Anwender gelegen. D.h. die Leistung der Datenpflege wurde durch den Anwender erbacht.
Sollten obige Voraussetzungen teilweise nicht gegeben sein, so nimm bitte mit uns Kontakt auf, es gibt noch weitere Möglichkeiten. Es ist uns sehr wichtig, dass alle diese Dinge im rechtlich legitimen Rahmen ablaufen.
Vorgehensweise zur Umstellung
Für die Umstellung von HELIUM V auf dein Kieselstein ERP wird wie folgt vorgegangen:
| Nr. | Beschreibung | wer | wann |
|---|---|---|---|
| 1. | zur Verfügung-Stellung eigenständiger Kieselstein ERP Server | M | |
| 2. | Einrichten Kieselstein ERP System | C | |
| 3. | einkopieren der Datenbanken und Formulare | C | |
| 3a. | Prüfung ev. hinzugekommener Datenbankfelder und deren Verwendung im eigenen Unternehmen | C+M | |
| 3b. | Prüfung der Eignung / Geschwindigkeit des Kieselstein ERP Servers | C | |
| 4. | Anpassung der Formulare | C | |
| 5. | einrichten Clients | C+M | |
| 6. | ausführliche Tests | M | |
| 7. | Fehlerreporting | M an C | |
| 8. | Entscheidung wie mit den Fehlern umgehen - Formularanpassung - Programmierung - Umgehung |
M + C | |
| 9. | Freigabe der Tests und Festlegung des Starttermins | M + C | |
| 10. | Übertragung und ev. Konvertierung der Datenbank nach Kieselstein ERP System | C | |
| 11. | Echtstart | C + M | |
| 12. | Feierlicher Abschluss | alle |
Bedeutung:
- C … Consultant
- M … Mitglied
Wie prüft man, welche DB Änderungen gemacht wurden
Wenn neuere Datenbankversionen gegeben sind, müssen die Datenstrukturen und die Inhalte geprüft werden. Hier geht man davon aus, dass anhand der Kieselstein-ERP default Datenbank (…/kieselstein/dist/bootstrap/database) ein Vergleich (https://www.devart.com/dbforge/sql/schemacompare/) mit der bestehenden Datenbank gemacht wird.
Anhand dessen, muss gemeinsam überlegt werden, welche Inhalte bei der Überleitung eventuell verloren gehen würden.
Anmerkung: Bisher haben wir zwar leichte Änderungen in den Strukturen bemerkt, welche jedoch, da nicht verwendet, (fast) keine Auswirkungen in den Dateninhalten hatten.
Selbstverständlich ist hier mit entsprechender Umsicht vorzugehen.
Hinweis: Mitglieder der Kieselstein-ERP eG können die genaue Umstellungsanleitung im Wiki nutzen.
Fehlermeldungen und deren mögliche Ursachen
Falsches Java am Server
Es scheint alles zu gehen, aber beim Drucker der Artikelstatistik kommt (wegen der Grafik) ein schwerer Fehler. Dieser weist in dem langen Fehlerstack auf Grafik / SVG Fehler hin.
im Server selbst sieht man, in den installierten Programmen, dass, vermutlich von früher noch,  installiert ist. Diese bitte deinstallieren und das aktuelle JDK mit FX für das jeweilige Betriebssystem verwenden. Das sieht dann so aus:
installiert ist. Diese bitte deinstallieren und das aktuelle JDK mit FX für das jeweilige Betriebssystem verwenden. Das sieht dann so aus: 
Dies passiert gerne wenn der bisherige ERP Server verwendet wird und das Java nicht überprüft wurde.